 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAREX: A Benchmark for Multi-Modal Structured Extraction from Documents
Mar 16, 2026We introduce VAREX (VARied-schema EXtraction), a benchmark for evaluating multimodal foundation models on structured data extraction from government forms. VAREX employs a Reverse Annotation pipeline that programmatically fills PDF templates with synthetic values, producing deterministic ground truth validated through three-phase quality assurance. The benchmark comprises 1,777 documents with 1,771 unique schemas across three structural categories, each provided in four input modalities: plain text, layout-preserving text (whitespace-aligned to approximate column positions), document image, or both text and image combined. Unlike existing benchmarks that evaluate from a single input representation, VAREX provides four controlled modalities per document, enabling systematic ablation of how input format affects extraction accuracy -- a capability absent from prior benchmarks. We evaluate 20 models from frontier proprietary models to small open models, with particular attention to models <=4B parameters suitable for cost-sensitive and latency-constrained deployment. Results reveal that (1) below 4B parameters, structured output compliance -- not extraction capability -- is a dominant bottleneck; in particular, schema echo (models producing schema-conforming structure instead of extracted values) depresses scores by 45-65 pp (percentage points) in affected models; (2) extraction-specific fine-tuning at 2B yields +81 pp gains, demonstrating that the instruction-following deficit is addressable without scale; (3) layout-preserving text provides the largest accuracy gain (+3-18 pp), exceeding pixel-level visual cues; and (4) the benchmark most effectively discriminates models in the 60-95% accuracy band. Dataset and evaluation code are publicly available.
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
May 01, 2024



In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
BusiNet -- a Light and Fast Text Detection Network for Business Documents
Jul 04, 2022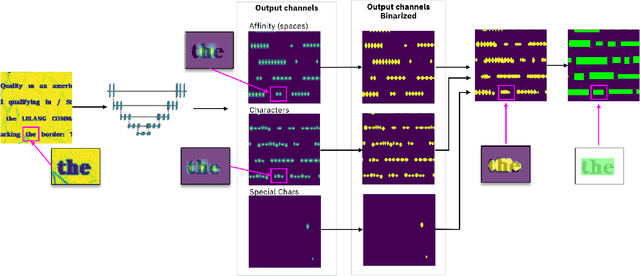
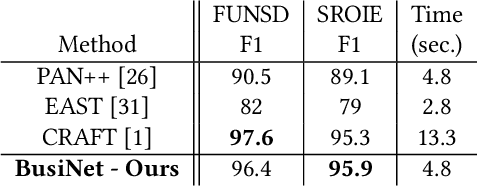

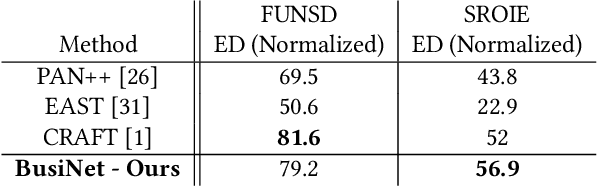
For digitizing or indexing physical documents, Optical Character Recognition (OCR), the process of extracting textual information from scanned documents, is a vital technology. When a document is visually damaged or contains non-textual elements, existing technologies can yield poor results, as erroneous detection results can greatly affect the quality of OCR. In this paper we present a detection network dubbed BusiNet aimed at OCR of business documents. Business documents often include sensitive information and as such they cannot be uploaded to a cloud service for OCR. BusiNet was designed to be fast and light so it could run locally preventing privacy issues. Furthermore, BusiNet is built to handle scanned document corruption and noise using a specialized synthetic dataset. The model is made robust to unseen noise by employing adversarial training strategies. We perform an evaluation on publicly available datasets demonstrating the usefulness and broad applicability of our model.
Detection Masking for Improved OCR on Noisy Documents
May 17, 2022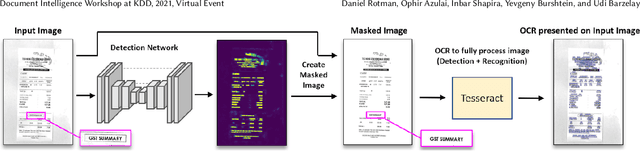
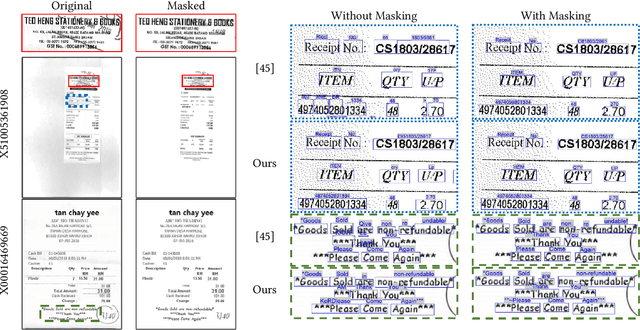

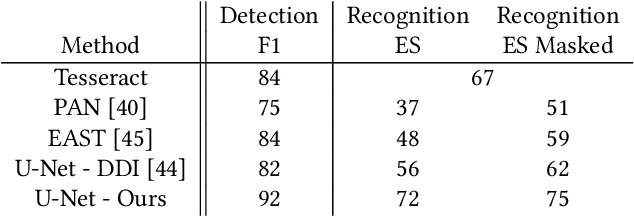
Optical Character Recognition (OCR), the task of extracting textual information from scanned documents is a vital and broadly used technology for digitizing and indexing physical documents. Existing technologies perform well for clean documents, but when the document is visually degraded, or when there are non-textual elements, OCR quality can be greatly impacted, specifically due to erroneous detections. In this paper we present an improved detection network with a masking system to improve the quality of OCR performed on documents. By filtering non-textual elements from the image we can utilize document-level OCR to incorporate contextual information to improve OCR results. We perform a unified evaluation on a publicly available dataset demonstrating the usefulness and broad applicability of our method. Additionally, we present and make publicly available our synthetic dataset with a unique hard-negative component specifically tuned to improve detection results, and evaluate the benefits that can be gained from its usage
CHARTER: heatmap-based multi-type chart data extraction
Nov 28, 2021
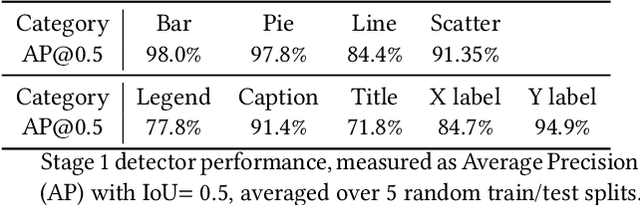
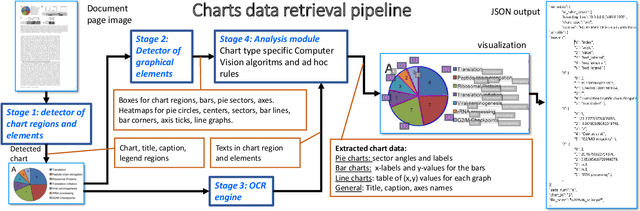
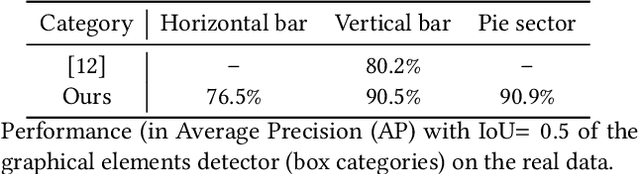
The digital conversion of information stored in documents is a great source of knowledge. In contrast to the documents text, the conversion of the embedded documents graphics, such as charts and plots, has been much less explored. We present a method and a system for end-to-end conversion of document charts into machine readable tabular data format, which can be easily stored and analyzed in the digital domain. Our approach extracts and analyses charts along with their graphical elements and supporting structures such as legends, axes, titles, and captions. Our detection system is based on neural networks, trained solely on synthetic data, eliminating the limiting factor of data collection. As opposed to previous methods, which detect graphical elements using bounding-boxes, our networks feature auxiliary domain specific heatmaps prediction enabling the precise detection of pie charts, line and scatter plots which do not fit the rectangular bounding-box presumption. Qualitative and quantitative results show high robustness and precision, improving upon previous works on popular benchmarks
* Joseph Shtok, Sivan Harary and Leonid Karlinsky had equal contribution
TAEN: Temporal Aware Embedding Network for Few-Shot Action Recognition
Apr 21, 2020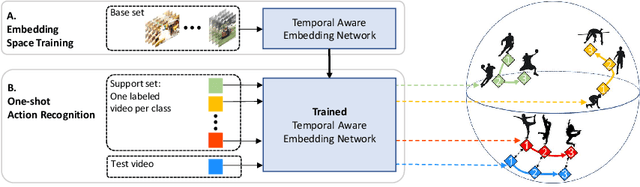
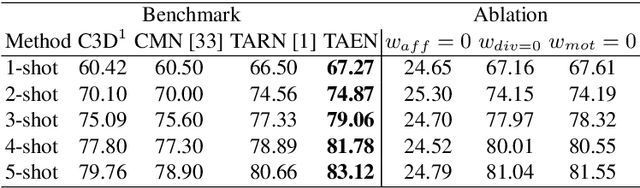
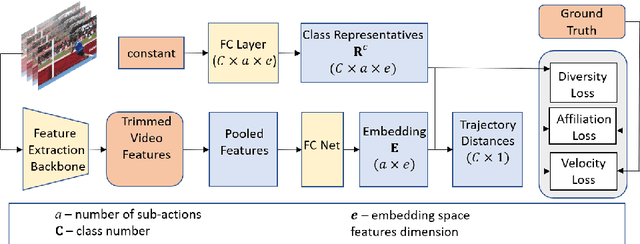
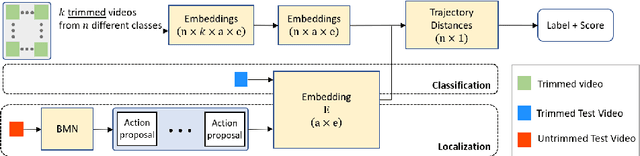
Classification of a new class entities requires collecting and annotating hundreds or thousands of samples that is often prohibitively time consuming and costly. Few-shot learning (FSL) suggests learning to classify new classes using just a few examples. Only a small number of studies address the challenge of using just a few labeled samples to learn a new spatio-temporal pattern such as videos. In this paper, we present a Temporal Aware Embedding Network (TAEN) for few-shot action recognition, that learns to represent actions, in a metric space as a trajectory, conveying both short term semantics and longer term connectivity between sub-actions. We demonstrate the effectiveness of TAEN on two few shot tasks, video classification and temporal action detection. We achieve state-of-the-art results on the Kinetics few-shot benchmark and on the ActivityNet 1.2 few-shot temporal action detection task. Code will be released upon acceptance of the paper.