 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Group Feature Selection and Discriminative Filter Learning for Robust Visual Object Tracking
Aug 02, 2019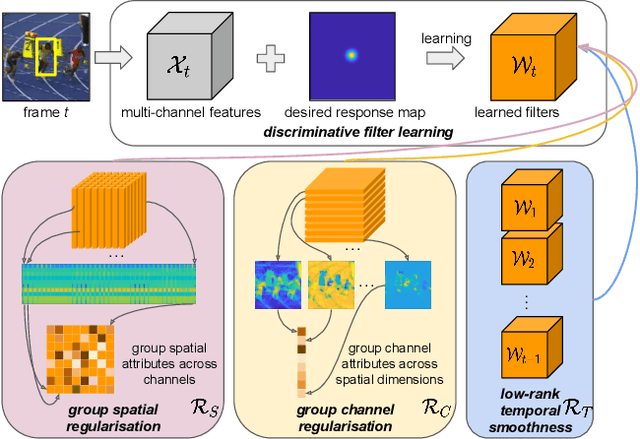
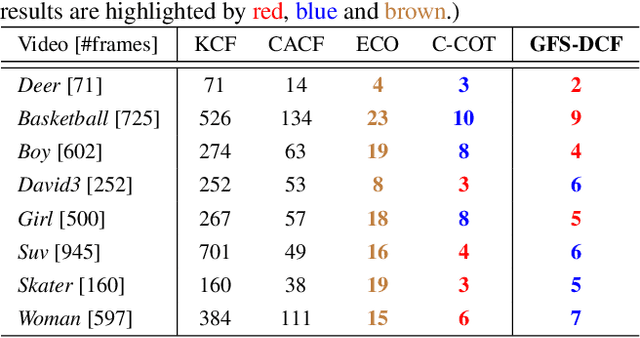
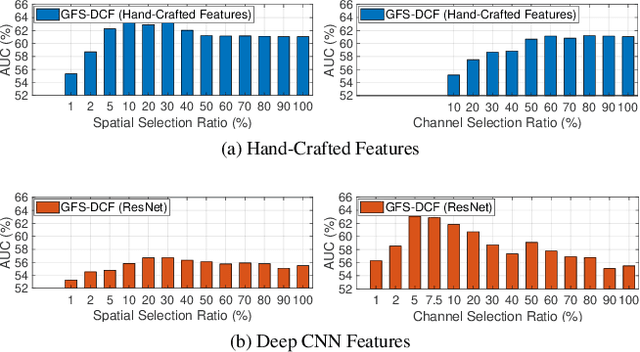
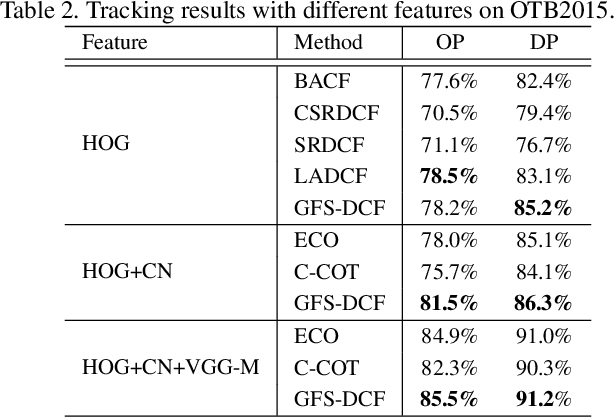
We propose a new Group Feature Selection method for Discriminative Correlation Filters (GFS-DCF) based visual object tracking. The key innovation of the proposed method is to perform group feature selection across both channel and spatial dimensions, thus to pinpoint the structural relevance of multi-channel features to the filtering system. In contrast to the widely used spatial regularisation or feature selection methods, to the best of our knowledge, this is the first time that channel selection has been advocated for DCF-based tracking. We demonstrate that our GFS-DCF method is able to significantly improve the performance of a DCF tracker equipped with deep neural network features. In addition, our GFS-DCF enables joint feature selection and filter learning, achieving enhanced discrimination and interpretability of the learned filters. To further improve the performance, we adaptively integrate historical information by constraining filters to be smooth across temporal frames, using an efficient low-rank approximation. By design, specific temporal-spatial-channel configurations are dynamically learned in the tracking process, highlighting the relevant features, and alleviating the performance degrading impact of less discriminative representations and reducing information redundancy. The experimental results obtained on OTB2013, OTB2015, VOT2017, VOT2018 and TrackingNet demonstrate the merits of our GFS-DCF and its superiority over the state-of-the-art trackers. The code is publicly available at https://github.com/XU-TIANYANG/GFS-DCF.
Multi-Task Kernel Null-Space for One-Class Classification
May 22, 2019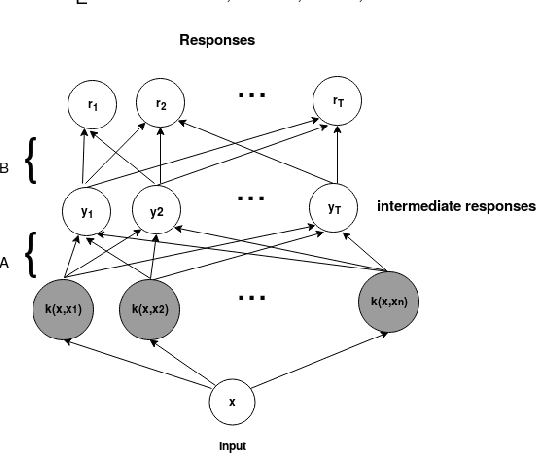
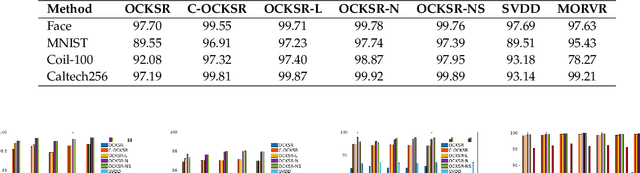
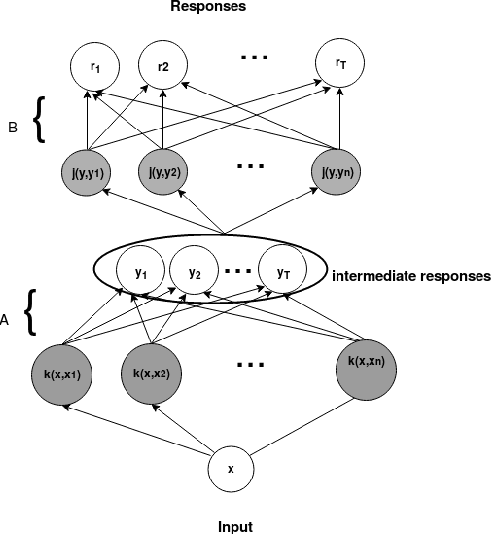

The one-class kernel spectral regression (OC-KSR), the regression-based formulation of the kernel null-space approach has been found to be an effective Fisher criterion-based methodology for one-class classification (OCC), achieving state-of-the-art performance in one-class classification while providing relatively high robustness against data corruption. This work extends the OC-KSR methodology to a multi-task setting where multiple one-class problems share information for improved performance. By viewing the multi-task structure learning problem as one of compositional function learning, first, the OC-KSR method is extended to learn multiple tasks' structure \textit{linearly} by posing it as an instantiation of the separable kernel learning problem in a vector-valued reproducing kernel Hilbert space where an output kernel encodes tasks' structure while another kernel captures input similarities. Next, a non-linear structure learning mechanism is proposed which captures multiple tasks' relationships \textit{non-linearly} via an output kernel. The non-linear structure learning method is then extended to a sparse setting where different tasks compete in an output composition mechanism, leading to a sparse non-linear structure among multiple problems. Through extensive experiments on different data sets, the merits of the proposed multi-task kernel null-space techniques are verified against the baseline as well as other existing multi-task one-class learning techniques.
Transition Subspace Learning based Least Squares Regression for Image Classification
May 14, 2019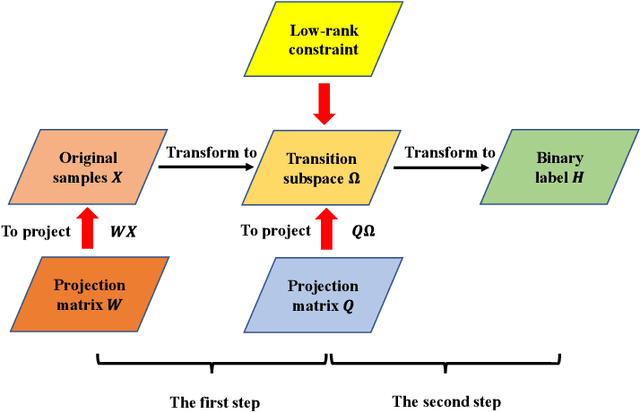
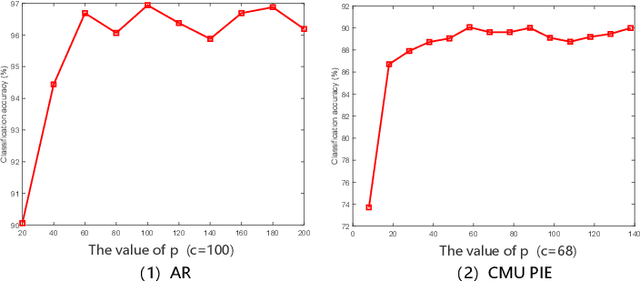
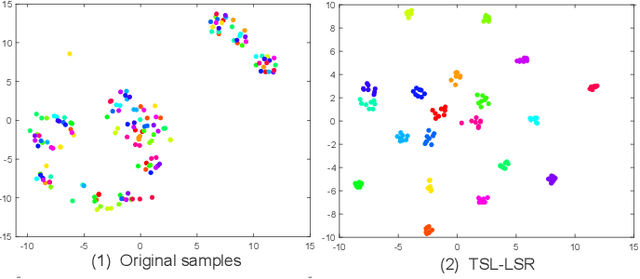
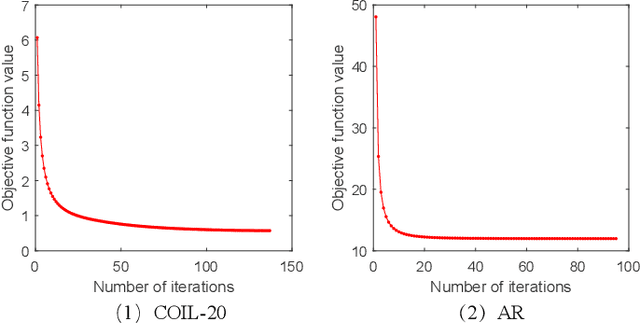
Only learning one projection matrix from original samples to the corresponding binary labels is too strict and will consequentlly lose some intrinsic geometric structures of data. In this paper, we propose a novel transition subspace learning based least squares regression (TSL-LSR) model for multicategory image classification. The main idea of TSL-LSR is to learn a transition subspace between the original samples and binary labels to alleviate the problem of overfitting caused by strict projection learning. Moreover, in order to reflect the underlying low-rank structure of transition matrix and learn more discriminative projection matrix, a low-rank constraint is added to the transition subspace. Experimental results on several image datasets demonstrate the effectiveness of the proposed TSL-LSR model in comparison with state-of-the-art algorithms
Low-Rank Discriminative Least Squares Regression for Image Classification
Apr 16, 2019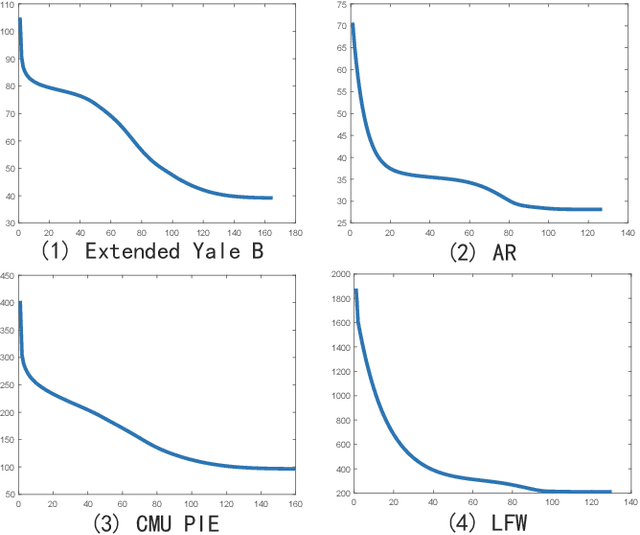


Latest least squares regression (LSR) methods mainly try to learn slack regression targets to replace strict zero-one labels. However, the difference of intra-class targets can also be highlighted when enlarging the distance between different classes, and roughly persuing relaxed targets may lead to the problem of overfitting. To solve above problems, we propose a low-rank discriminative least squares regression model (LRDLSR) for multi-class image classification. Specifically, LRDLSR class-wisely imposes low-rank constraint on the intra-class regression targets to encourage its compactness and similarity. Moreover, LRDLSR introduces an additional regularization term on the learned targets to avoid the problem of overfitting. These two improvements are helpful to learn a more discriminative projection for regression and thus achieving better classification performance. Experimental results over a range of image databases demonstrate the effectiveness of the proposed LRDLSR method.
Non-negative representation based discriminative dictionary learning for face recognition
Mar 19, 2019



In this paper, we propose a non-negative representation based discriminative dictionary learning algorithm (NRDL) for multicategory face classification. In contrast to traditional dictionary learning methods, NRDL investigates the use of non-negative representation (NR), which contributes to learning discriminative dictionary atoms. In order to make the learned dictionary more suitable for classification, NRDL seamlessly incorporates nonnegative representation constraint, discriminative dictionary learning and linear classifier training into a unified model. Specifically, NRDL introduces a positive constraint on representation matrix to find distinct atoms from heterogeneous training samples, which results in sparse and discriminative representation. Moreover, a discriminative dictionary encouraging function is proposed to enhance the uniqueness of class-specific sub-dictionaries. Meanwhile, an inter-class incoherence constraint and a compact graph based regularization term are constructed to respectively improve the discriminability of learned classifier. Experimental results on several benchmark face data sets verify the advantages of our NRDL algorithm over the state-of-the-art dictionary learning methods.
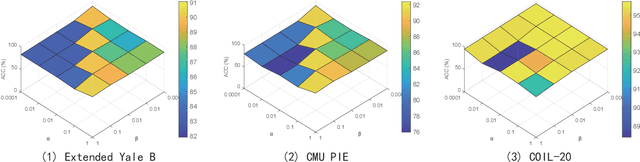
Fisher Discriminative Least Square Regression with Self-Adaptive Weighting for Face Recognition
Mar 19, 2019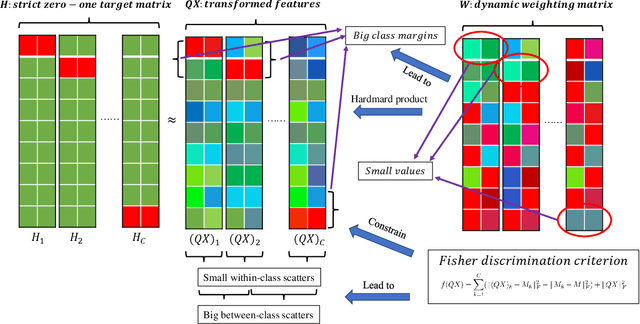
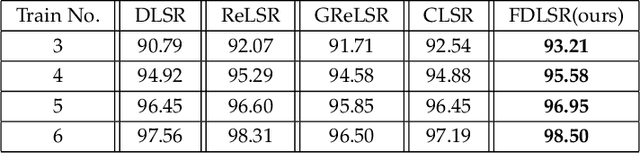

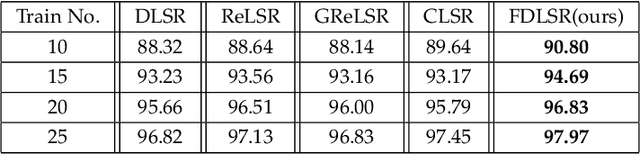
As a supervised classification method, least square regression (LSR) has shown promising performance in multiclass face recognition tasks. However, the latest LSR based classification methods mainly focus on learning a relaxed regression target to replace traditional zero-one label matrix while ignoring the discriminability of transformed features. Based on the assumption that the transformed features of samples from the same class have similar structure while those of samples from different classes are uncorrelated, in this paper we propose a novel discriminative LSR method based on the Fisher discrimination criterion (FDLSR), where the projected features have small within-class scatter and large inter-class scatter simultaneously. Moreover, different from other methods, we explore relax regression from the view of transformed features rather than the regression targets. Specifically, we impose a dynamic non-negative weight matrix on the transformed features to enlarge the margin between the true and the false classes by self-adaptively assigning appropriate weights to different features. Above two factors can encourage the learned transformation for regression to be more discriminative and thus achieving better classification performance. Extensive experiments on various databases demonstrate that the proposed FDLSR method achieves superior performance to other state-of-the-art LSR based classification methods.
Visual Semantic Information Pursuit: A Survey
Mar 13, 2019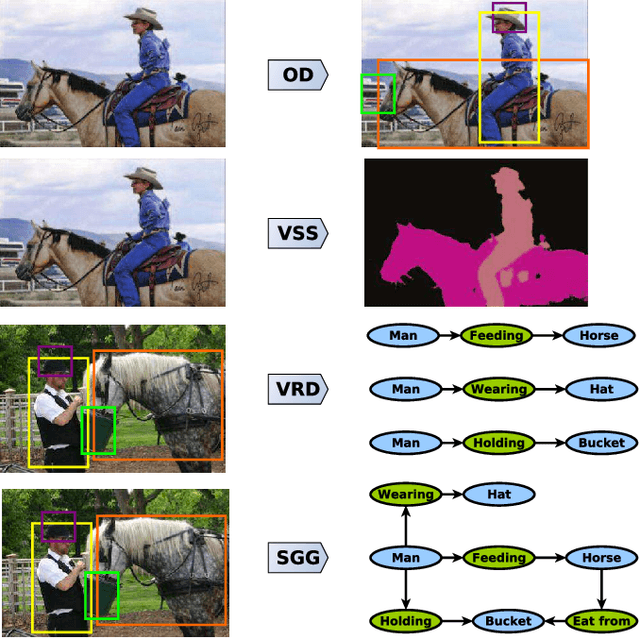

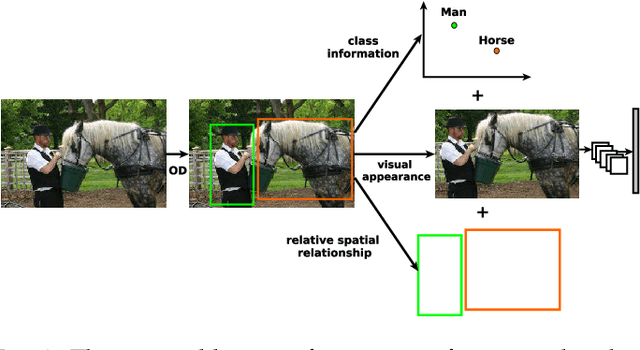
Visual semantic information comprises two important parts: the meaning of each visual semantic unit and the coherent visual semantic relation conveyed by these visual semantic units. Essentially, the former one is a visual perception task while the latter one corresponds to visual context reasoning. Remarkable advances in visual perception have been achieved due to the success of deep learning. In contrast, visual semantic information pursuit, a visual scene semantic interpretation task combining visual perception and visual context reasoning, is still in its early stage. It is the core task of many different computer vision applications, such as object detection, visual semantic segmentation, visual relationship detection or scene graph generation. Since it helps to enhance the accuracy and the consistency of the resulting interpretation, visual context reasoning is often incorporated with visual perception in current deep end-to-end visual semantic information pursuit methods. However, a comprehensive review for this exciting area is still lacking. In this survey, we present a unified theoretical paradigm for all these methods, followed by an overview of the major developments and the future trends in each potential direction. The common benchmark datasets, the evaluation metrics and the comparisons of the corresponding methods are also introduced.
Robust One-Class Kernel Spectral Regression
Feb 06, 2019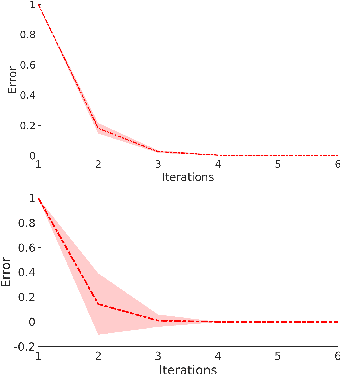
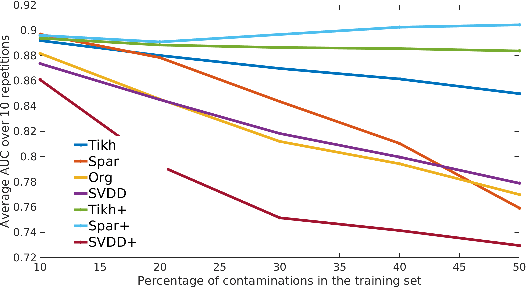
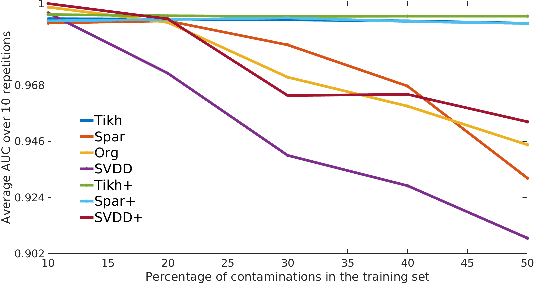
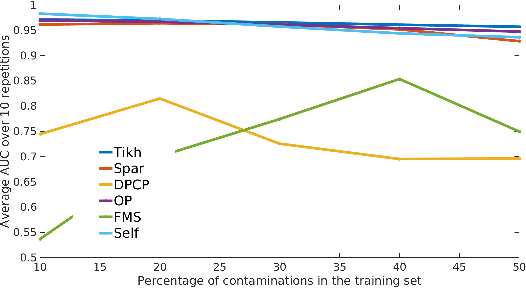
The kernel null-space technique and its regression-based formulation (called one-class kernel spectral regression, a.k.a. OC-KSR) is known to be an effective and computationally attractive one-class classification framework. Despite its outstanding performance, the applicability of kernel null-space method is limited due to its susceptibility to possible training data corruptions and inability to rank training observations according to their conformity with the model. This work addresses these shortcomings by studying the effect of regularising the solution of the null-space kernel Fisher methodology in the context of its regression-based formulation (OC-KSR). In this respect, first, the effect of a Tikhonov regularisation in the Hilbert space is analysed where the one-class learning problem in presence of contaminations in the training set is posed as a sensitivity analysis problem. Next, driven by the success of the sparse representation methodology, the effect of a sparsity regularisation on the solution is studied. For both alternative regularisation schemes, iterative algorithms are proposed which recursively update label confidences and rank training observations based on their fit with the model. Through extensive experiments conducted on different data sets, the proposed methodology is found to enhance robustness against contamination in the training set as compared with the baseline kernel null-space technique as well as other existing approaches in a one-class classification paradigm while providing the functionality to rank training samples effectively.
Discriminative Supervised Hashing for Cross-Modal similarity Search
Dec 06, 2018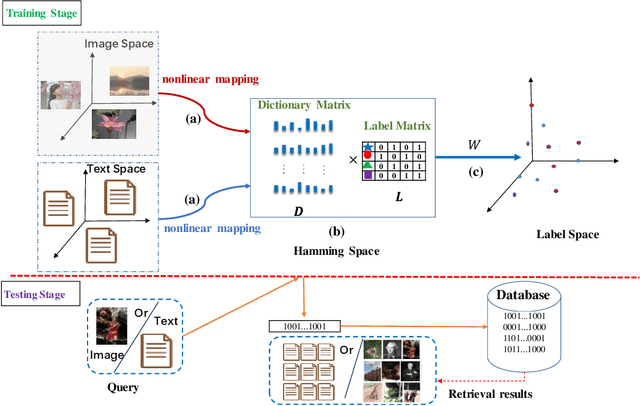
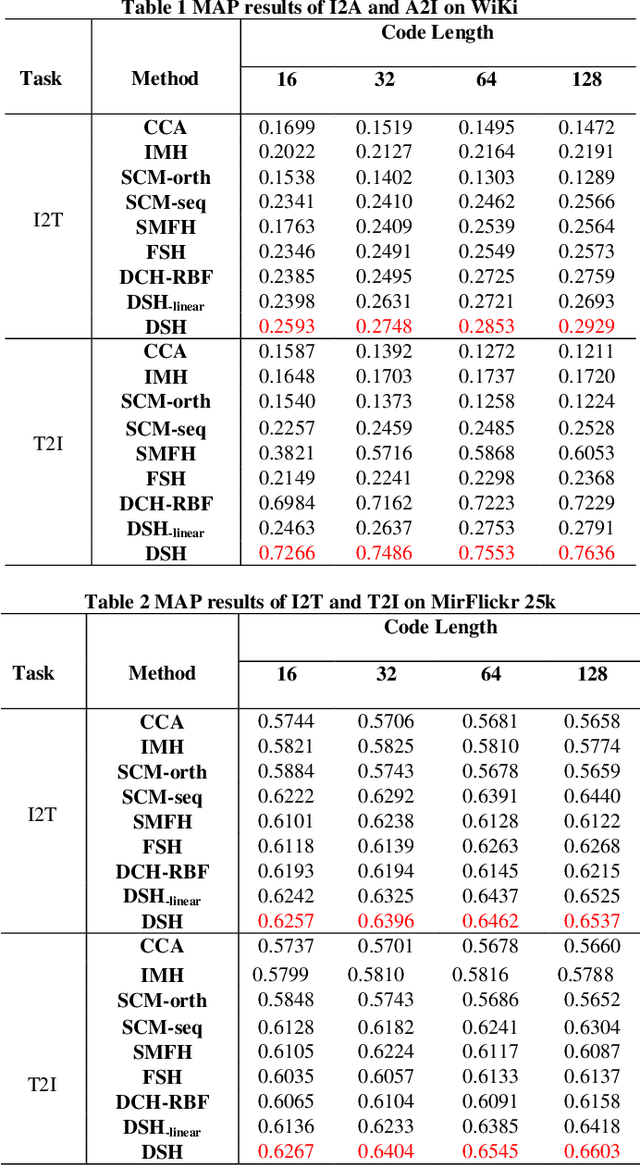
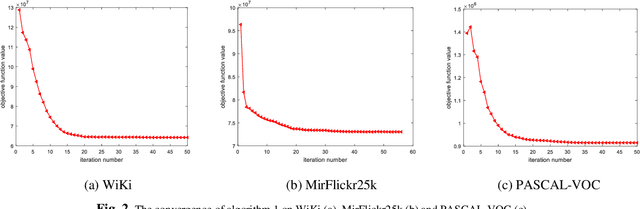
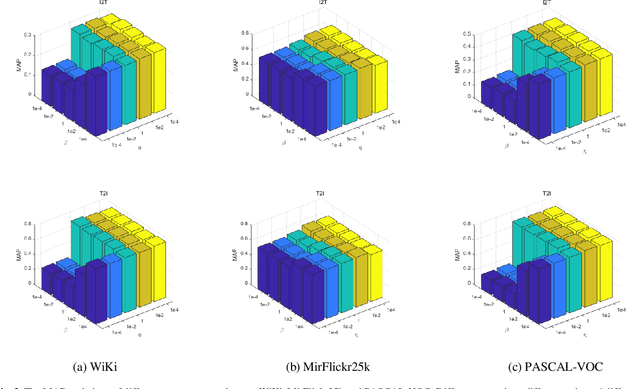
With the advantage of low storage cost and high retrieval efficiency, hashing techniques have recently been an emerging topic in cross-modal similarity search. As multiple modal data reflect similar semantic content, many researches aim at learning unified binary codes. However, discriminative hashing features learned by these methods are not adequate. This results in lower accuracy and robustness. We propose a novel hashing learning framework which jointly performs classifier learning, subspace learning and matrix factorization to preserve class-specific semantic content, termed Discriminative Supervised Hashing (DSH), to learn the discrimative unified binary codes for multi-modal data. Besides, reducing the loss of information and preserving the non-linear structure of data, DSH non-linearly projects different modalities into the common space in which the similarity among heterogeneous data points can be measured. Extensive experiments conducted on the three publicly available datasets demonstrate that the framework proposed in this paper outperforms several state-of -the-art methods.
Pose Invariant 3D Face Reconstruction
Nov 13, 2018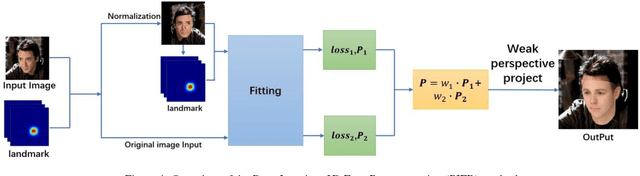
3D face reconstruction is an important task in the field of computer vision. Although 3D face reconstruction has being developing rapidly in recent years, it is still a challenge for face reconstruction under large pose. That is because much of the information about a face in a large pose will be unknowable. In order to address this issue, this paper proposes a novel 3D face reconstruction algorithm (PIFR) based on 3D Morphable Model (3DMM). After input a single face image, it generates a frontal image by normalizing the image. Then we set weighted sum of the 3D parameters of the two images. Our method solves the problem of face reconstruction of a single image of a traditional method in a large pose, works on arbitrary Pose and Expressions, greatly improves the accuracy of reconstruction. Experiments on the challenging AFW, LFPW and AFLW database show that our algorithm significantly improves the accuracy of 3D face reconstruction even under extreme poses .