 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpponent Modeling in Negotiation Dialogues by Related Data Adaptation
May 03, 2022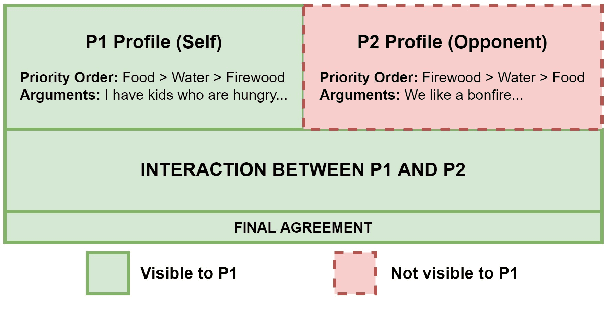
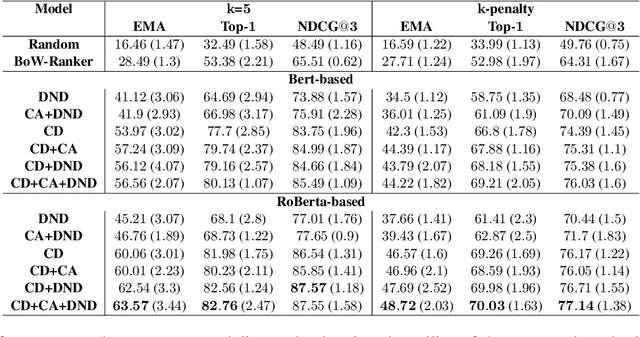
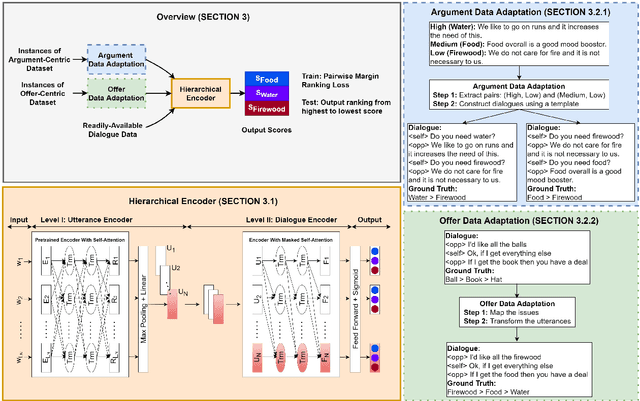

Opponent modeling is the task of inferring another party's mental state within the context of social interactions. In a multi-issue negotiation, it involves inferring the relative importance that the opponent assigns to each issue under discussion, which is crucial for finding high-value deals. A practical model for this task needs to infer these priorities of the opponent on the fly based on partial dialogues as input, without needing additional annotations for training. In this work, we propose a ranker for identifying these priorities from negotiation dialogues. The model takes in a partial dialogue as input and predicts the priority order of the opponent. We further devise ways to adapt related data sources for this task to provide more explicit supervision for incorporating the opponent's preferences and offers, as a proxy to relying on granular utterance-level annotations. We show the utility of our proposed approach through extensive experiments based on two dialogue datasets. We find that the proposed data adaptations lead to strong performance in zero-shot and few-shot scenarios. Moreover, they allow the model to perform better than baselines while accessing fewer utterances from the opponent. We release our code to support future work in this direction.
CheckDST: Measuring Real-World Generalization of Dialogue State Tracking Performance
Dec 15, 2021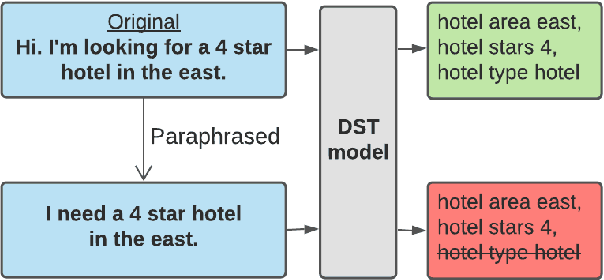
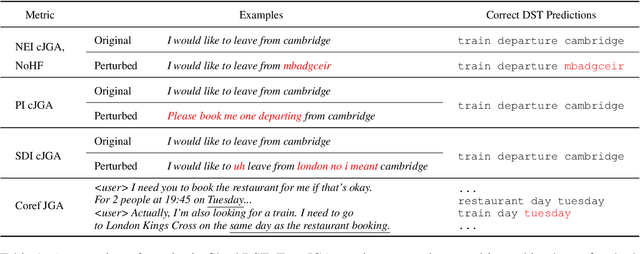
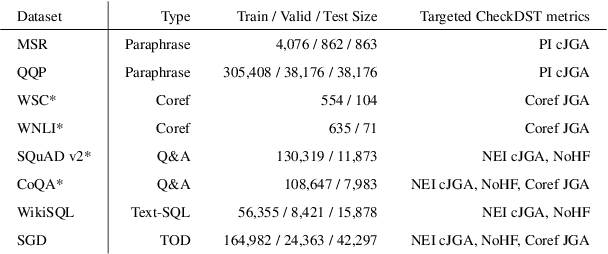
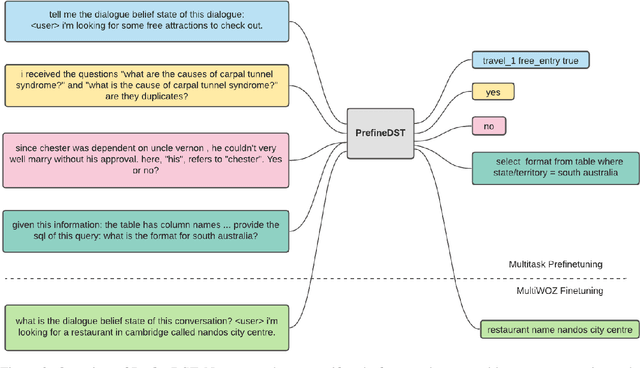
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.
Explaining Face Presentation Attack Detection Using Natural Language
Nov 08, 2021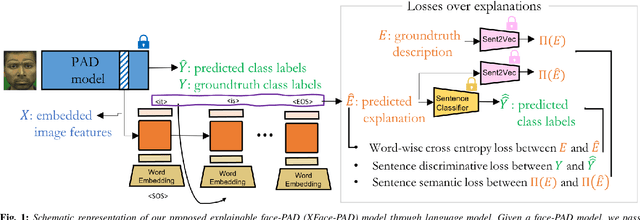
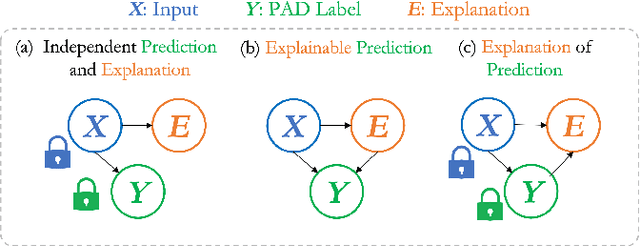
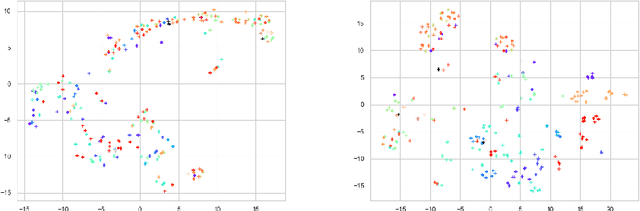
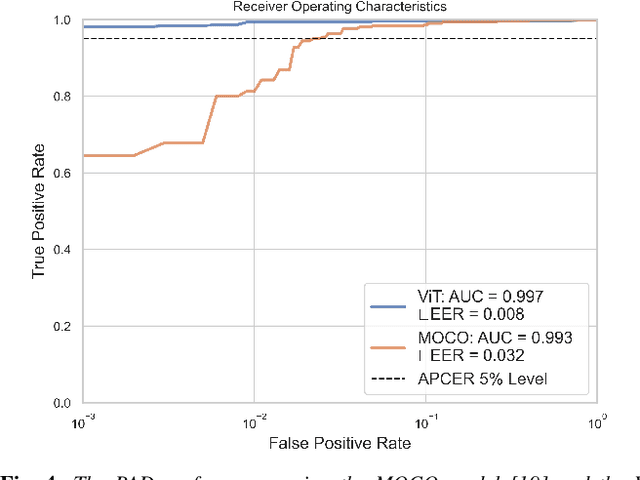
A large number of deep neural network based techniques have been developed to address the challenging problem of face presentation attack detection (PAD). Whereas such techniques' focus has been on improving PAD performance in terms of classification accuracy and robustness against unseen attacks and environmental conditions, there exists little attention on the explainability of PAD predictions. In this paper, we tackle the problem of explaining PAD predictions through natural language. Our approach passes feature representations of a deep layer of the PAD model to a language model to generate text describing the reasoning behind the PAD prediction. Due to the limited amount of annotated data in our study, we apply a light-weight LSTM network as our natural language generation model. We investigate how the quality of the generated explanations is affected by different loss functions, including the commonly used word-wise cross entropy loss, a sentence discriminative loss, and a sentence semantic loss. We perform our experiments using face images from a dataset consisting of 1,105 bona-fide and 924 presentation attack samples. Our quantitative and qualitative results show the effectiveness of our model for generating proper PAD explanations through text as well as the power of the sentence-wise losses. To the best of our knowledge, this is the first introduction of a joint biometrics-NLP task. Our dataset can be obtained through our GitHub page.
Salience-Aware Event Chain Modeling for Narrative Understanding
Sep 22, 2021
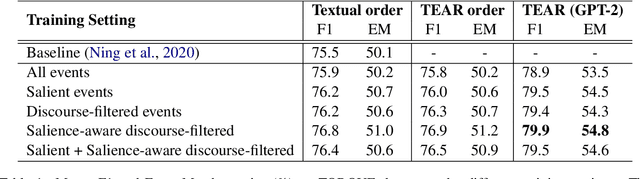
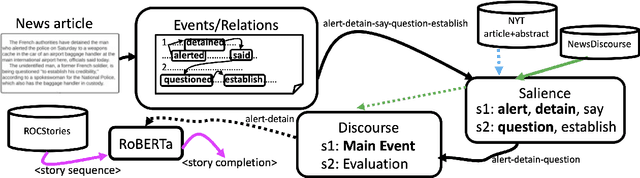
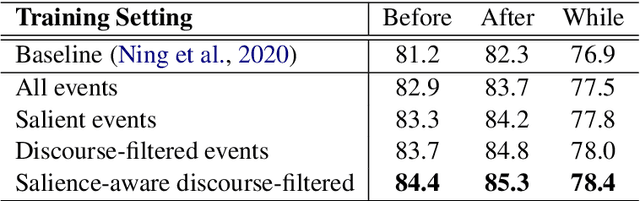
Storytelling, whether via fables, news reports, documentaries, or memoirs, can be thought of as the communication of interesting and related events that, taken together, form a concrete process. It is desirable to extract the event chains that represent such processes. However, this extraction remains a challenging problem. We posit that this is due to the nature of the texts from which chains are discovered. Natural language text interleaves a narrative of concrete, salient events with background information, contextualization, opinion, and other elements that are important for a variety of necessary discourse and pragmatics acts but are not part of the principal chain of events being communicated. We introduce methods for extracting this principal chain from natural language text, by filtering away non-salient events and supportive sentences. We demonstrate the effectiveness of our methods at isolating critical event chains by comparing their effect on downstream tasks. We show that by pre-training large language models on our extracted chains, we obtain improvements in two tasks that benefit from a clear understanding of event chains: narrative prediction and event-based temporal question answering. The demonstrated improvements and ablative studies confirm that our extraction method isolates critical event chains.
Viola: A Topic Agnostic Generate-and-Rank Dialogue System
Aug 25, 2021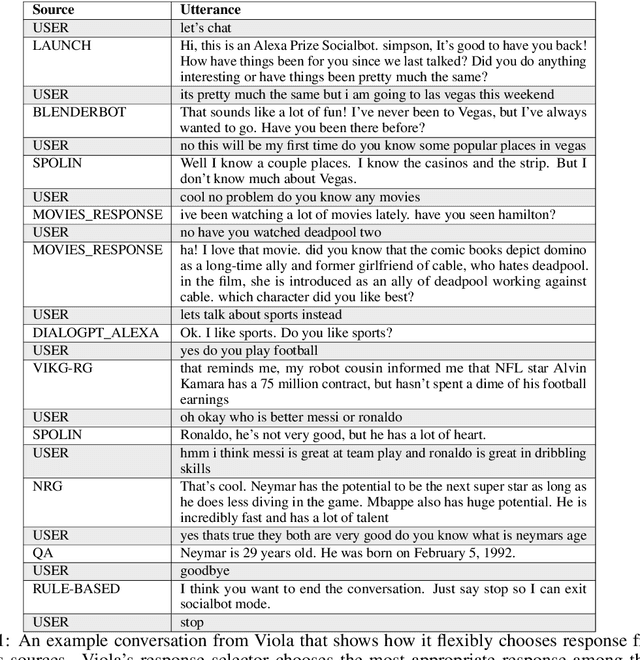
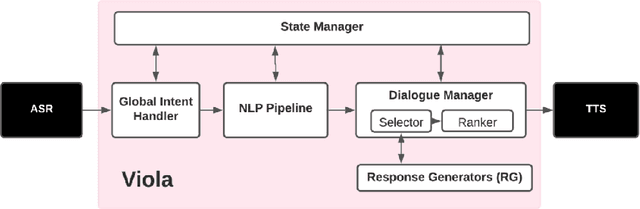
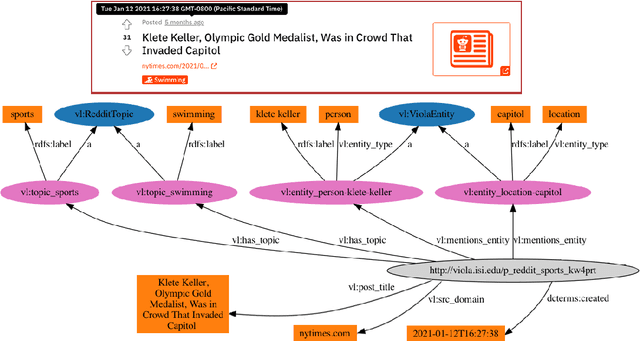
We present Viola, an open-domain dialogue system for spoken conversation that uses a topic-agnostic dialogue manager based on a simple generate-and-rank approach. Leveraging recent advances of generative dialogue systems powered by large language models, Viola fetches a batch of response candidates from various neural dialogue models trained with different datasets and knowledge-grounding inputs. Additional responses originating from template-based generators are also considered, depending on the user's input and detected entities. The hand-crafted generators build on a dynamic knowledge graph injected with rich content that is crawled from the web and automatically processed on a daily basis. Viola's response ranker is a fine-tuned polyencoder that chooses the best response given the dialogue history. While dedicated annotations for the polyencoder alone can indirectly steer it away from choosing problematic responses, we add rule-based safety nets to detect neural degeneration and a dedicated classifier to filter out offensive content. We analyze conversations that Viola took part in for the Alexa Prize Socialbot Grand Challenge 4 and discuss the strengths and weaknesses of our approach. Lastly, we suggest future work with a focus on curating conversation data specifcially for socialbots that will contribute towards a more robust data-driven socialbot.
Luna: Linear Unified Nested Attention
Jun 03, 2021
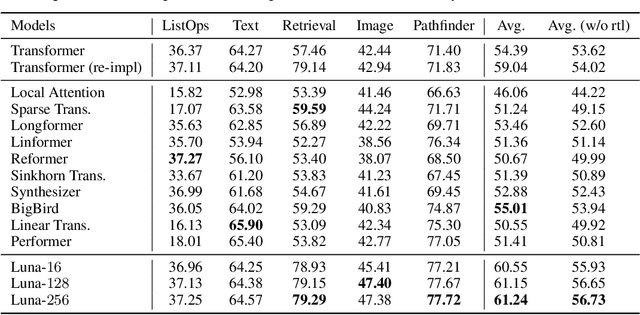
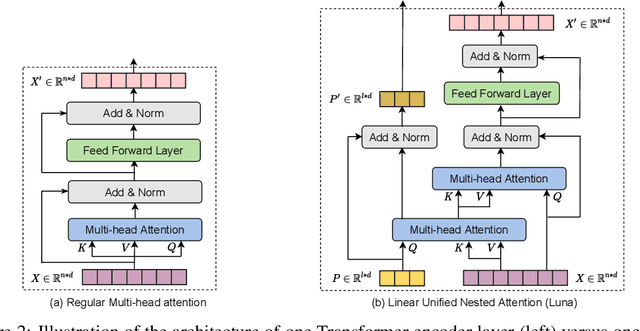
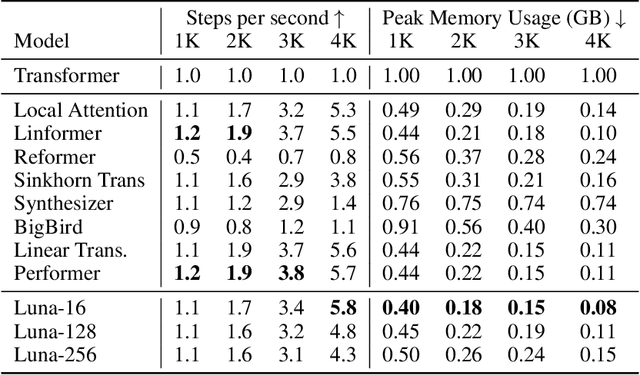
The quadratic computational and memory complexities of the Transformer's attention mechanism have limited its scalability for modeling long sequences. In this paper, we propose Luna, a linear unified nested attention mechanism that approximates softmax attention with two nested linear attention functions, yielding only linear (as opposed to quadratic) time and space complexity. Specifically, with the first attention function, Luna packs the input sequence into a sequence of fixed length. Then, the packed sequence is unpacked using the second attention function. As compared to a more traditional attention mechanism, Luna introduces an additional sequence with a fixed length as input and an additional corresponding output, which allows Luna to perform attention operation linearly, while also storing adequate contextual information. We perform extensive evaluations on three benchmarks of sequence modeling tasks: long-context sequence modeling, neural machine translation and masked language modeling for large-scale pretraining. Competitive or even better experimental results demonstrate both the effectiveness and efficiency of Luna compared to a variety
\textit{StateCensusLaws.org}: A Web Application for Consuming and Annotating Legal Discourse Learning
Apr 20, 2021
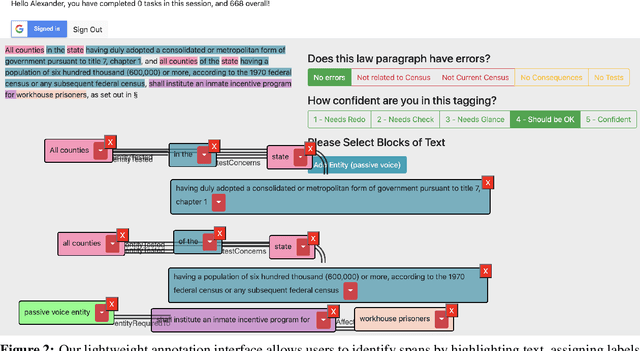

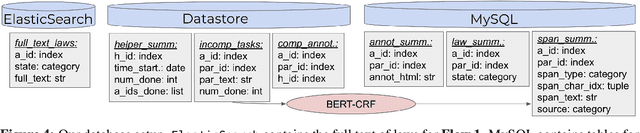
In this work, we create a web application to highlight the output of NLP models trained to parse and label discourse segments in law text. Our system is built primarily with journalists and legal interpreters in mind, and we focus on state-level law that uses U.S. Census population numbers to allocate resources and organize government. Our system exposes a corpus we collect of 6,000 state-level laws that pertain to the U.S. census, using 25 scrapers we built to crawl state law websites, which we release. We also build a novel, flexible annotation framework that can handle span-tagging and relation tagging on an arbitrary input text document and be embedded simply into any webpage. This framework allows journalists and researchers to add to our annotation database by correcting and tagging new data.
X-METRA-ADA: Cross-lingual Meta-Transfer Learning Adaptation to Natural Language Understanding and Question Answering
Apr 20, 2021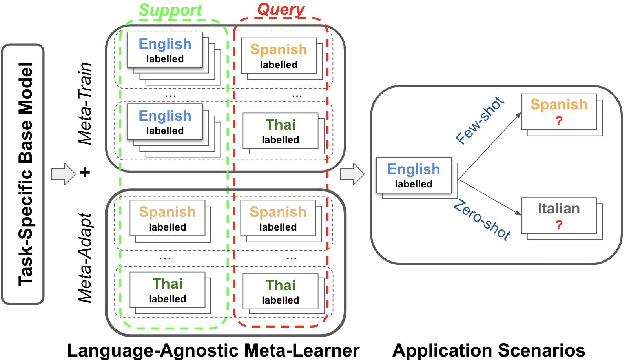
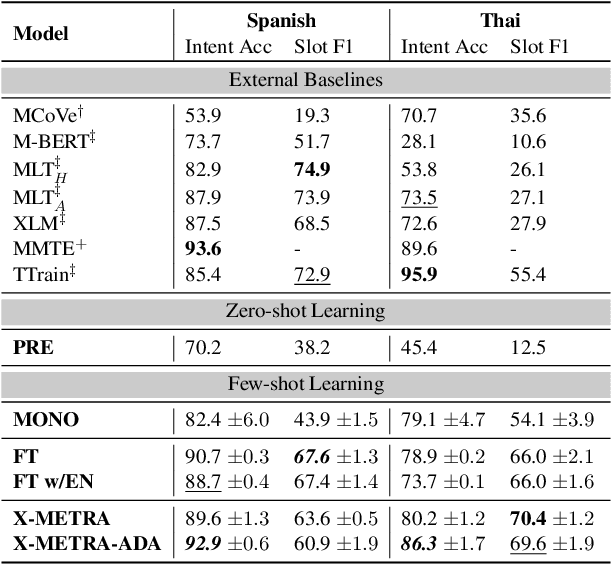
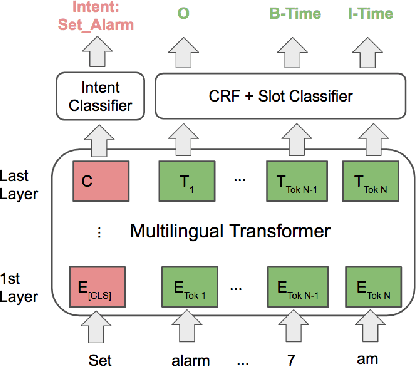
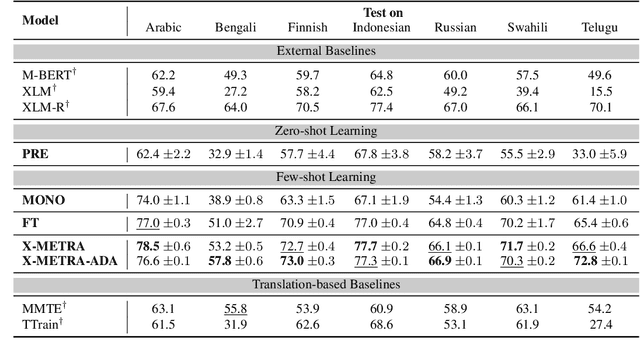
Multilingual models, such as M-BERT and XLM-R, have gained increasing popularity, due to their zero-shot cross-lingual transfer learning capabilities. However, their generalization ability is still inconsistent for typologically diverse languages and across different benchmarks. Recently, meta-learning has garnered attention as a promising technique for enhancing transfer learning under low-resource scenarios: particularly for cross-lingual transfer in Natural Language Understanding (NLU). In this work, we propose X-METRA-ADA, a cross-lingual MEta-TRAnsfer learning ADAptation approach for NLU. Our approach adapts MAML, an optimization-based meta-learning approach, to learn to adapt to new languages. We extensively evaluate our framework on two challenging cross-lingual NLU tasks: multilingual task-oriented dialog and typologically diverse question answering. We show that our approach outperforms naive fine-tuning, reaching competitive performance on both tasks for most languages. Our analysis reveals that X-METRA-ADA can leverage limited data for faster adaptation.
"Don't quote me on that": Finding Mixtures of Sources in News Articles
Apr 19, 2021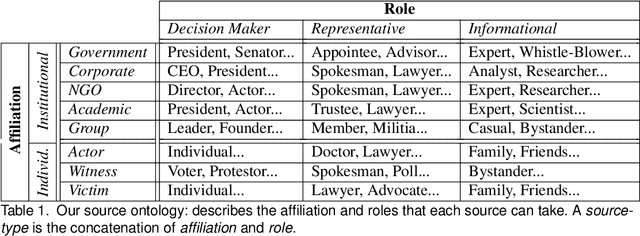
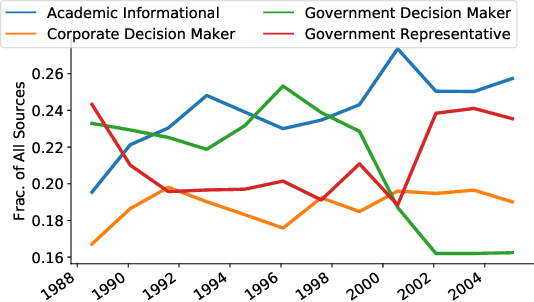


Journalists publish statements provided by people, or \textit{sources} to contextualize current events, help voters make informed decisions, and hold powerful individuals accountable. In this work, we construct an ontological labeling system for sources based on each source's \textit{affiliation} and \textit{role}. We build a probabilistic model to infer these attributes for named sources and to describe news articles as mixtures of these sources. Our model outperforms existing mixture modeling and co-clustering approaches and correctly infers source-type in 80\% of expert-evaluated trials. Such work can facilitate research in downstream tasks like opinion and argumentation mining, representing a first step towards machine-in-the-loop \textit{computational journalism} systems.
Modeling "Newsworthiness" for Lead-Generation Across Corpora
Apr 19, 2021
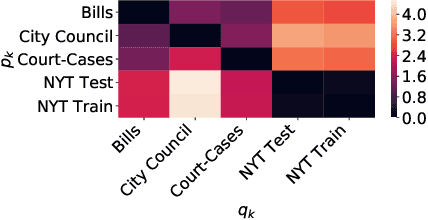

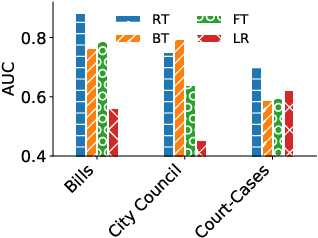
Journalists obtain "leads", or story ideas, by reading large corpora of government records: court cases, proposed bills, etc. However, only a small percentage of such records are interesting documents. We propose a model of "newsworthiness" aimed at surfacing interesting documents. We train models on automatically labeled corpora -- published newspaper articles -- to predict whether each article was a front-page article (i.e., \textbf{newsworthy}) or not (i.e., \textbf{less newsworthy}). We transfer these models to unlabeled corpora -- court cases, bills, city-council meeting minutes -- to rank documents in these corpora on "newsworthiness". A fine-tuned RoBERTa model achieves .93 AUC performance on heldout labeled documents, and .88 AUC on expert-validated unlabeled corpora. We provide interpretation and visualization for our models.