 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Consistency and Composability of Lottery Ticket Pruning Masks
Apr 30, 2021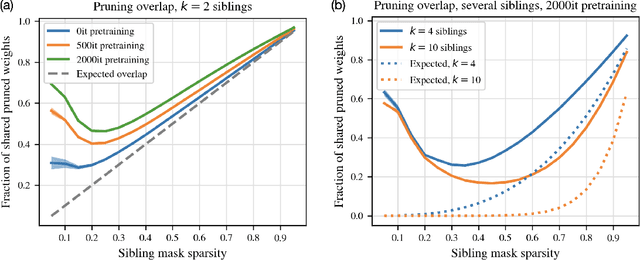
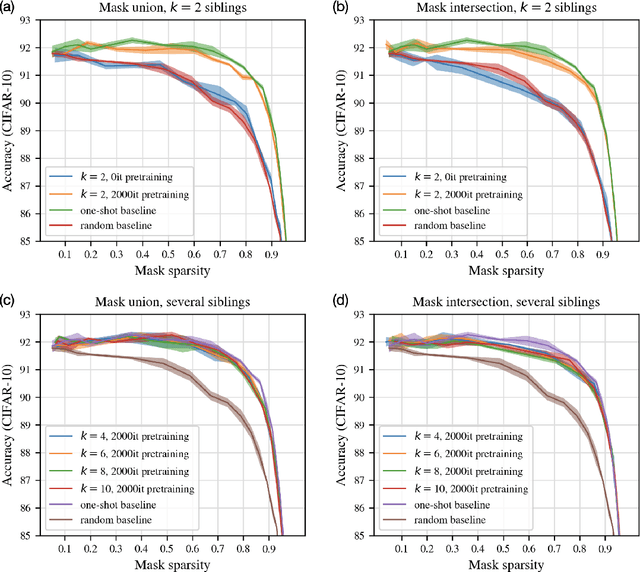
Magnitude pruning is a common, effective technique to identify sparse subnetworks at little cost to accuracy. In this work, we ask whether a particular architecture's accuracy-sparsity tradeoff can be improved by combining pruning information across multiple runs of training. From a shared ResNet-20 initialization, we train several network copies (\emph{siblings}) to completion using different SGD data orders on CIFAR-10. While the siblings' pruning masks are naively not much more similar than chance, starting sibling training after a few epochs of shared pretraining significantly increases pruning overlap. We then choose a subnetwork by either (1) taking all weights that survive pruning in any sibling (mask union), or (2) taking only the weights that survive pruning across all siblings (mask intersection). The resulting subnetwork is retrained. Strikingly, we find that union and intersection masks perform very similarly. Both methods match the accuracy-sparsity tradeoffs of the one-shot magnitude pruning baseline, even when we combine masks from up to $k = 10$ siblings.
The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models
Dec 12, 2020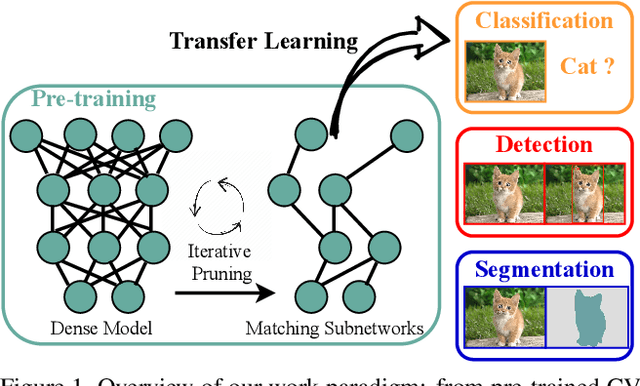

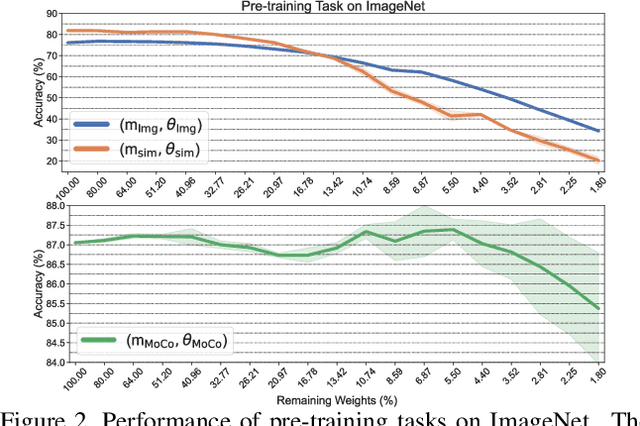
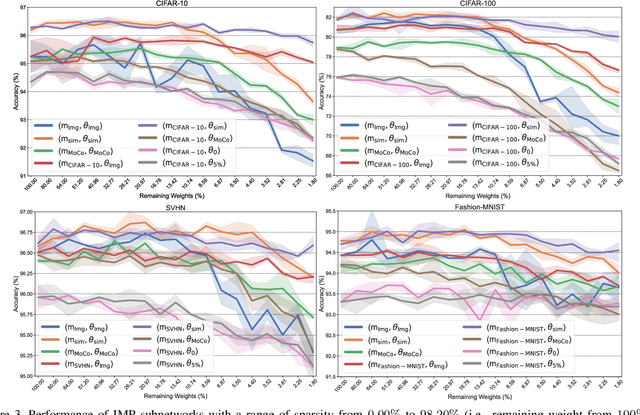
The computer vision world has been re-gaining enthusiasm in various pre-trained models, including both classical ImageNet supervised pre-training and recently emerged self-supervised pre-training such as simCLR and MoCo. Pre-trained weights often boost a wide range of downstream tasks including classification, detection, and segmentation. Latest studies suggest that the pre-training benefits from gigantic model capacity. We are hereby curious and ask: after pre-training, does a pre-trained model indeed have to stay large for its universal downstream transferability? In this paper, we examine the supervised and self-supervised pre-trained models through the lens of lottery ticket hypothesis (LTH). LTH identifies highly sparse matching subnetworks that can be trained in isolation from (nearly) scratch, to reach the full models' performance. We extend the scope of LTH to questioning whether matching subnetworks still exist in the pre-training models, that enjoy the same downstream transfer performance. Our extensive experiments convey an overall positive message: from all pre-trained weights obtained by ImageNet classification, simCLR and MoCo, we are consistently able to locate such matching subnetworks at 59.04% to 96.48% sparsity that transfer universally to multiple downstream tasks, whose performance see no degradation compared to using full pre-trained weights. Further analyses reveal that subnetworks found from different pre-training tend to yield diverse mask structures and perturbation sensitivities. We conclude that the core LTH observations remain generally relevant in the pre-training paradigm of computer vision, but more delicate discussions are needed in some cases. Codes and pre-trained models will be made available at: https://github.com/VITA-Group/CV_LTH_Pre-training.
Revisiting "Qualitatively Characterizing Neural Network Optimization Problems"
Dec 12, 2020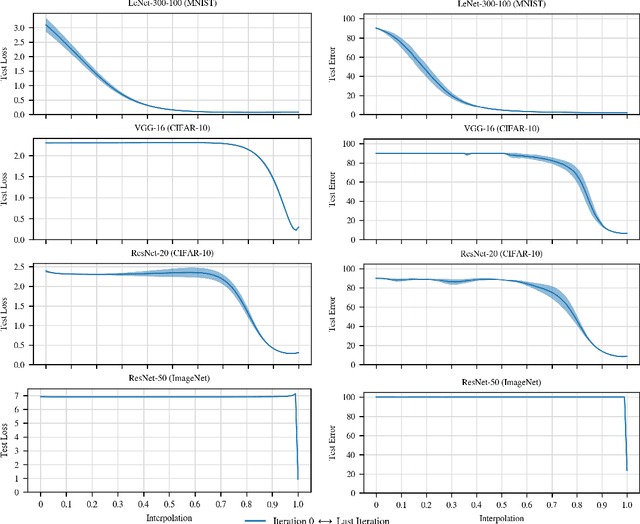
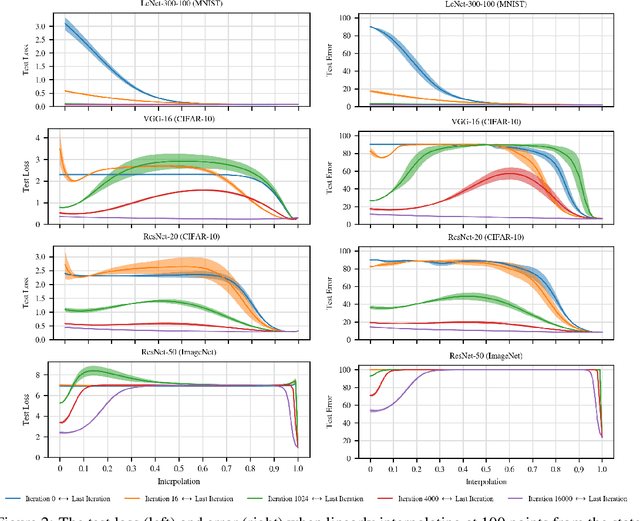
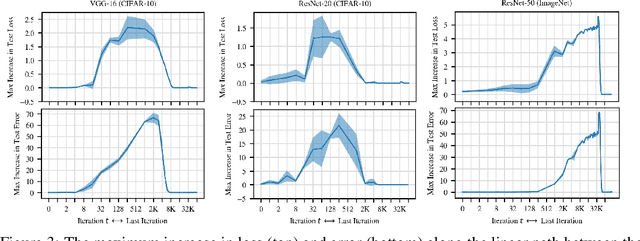
We revisit and extend the experiments of Goodfellow et al. (2014), who showed that - for then state-of-the-art networks - "the objective function has a simple, approximately convex shape" along the linear path between initialization and the trained weights. We do not find this to be the case for modern networks on CIFAR-10 and ImageNet. Instead, although loss is roughly monotonically non-increasing along this path, it remains high until close to the optimum. In addition, training quickly becomes linearly separated from the optimum by loss barriers. We conclude that, although Goodfellow et al.'s findings describe the "relatively easy to optimize" MNIST setting, behavior is qualitatively different in modern settings.
Are all negatives created equal in contrastive instance discrimination?
Oct 25, 2020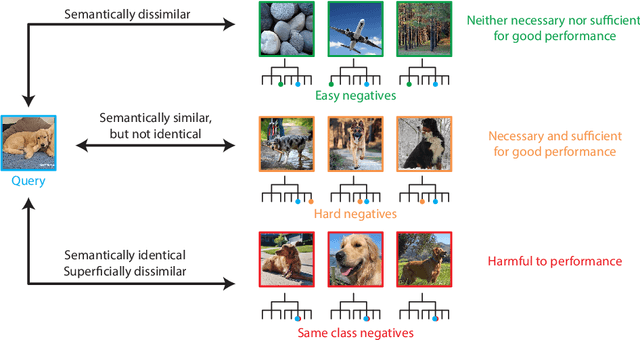
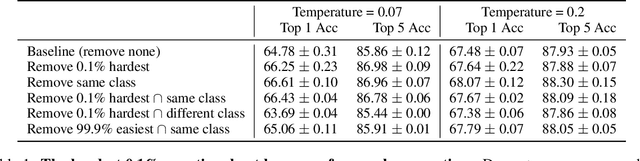
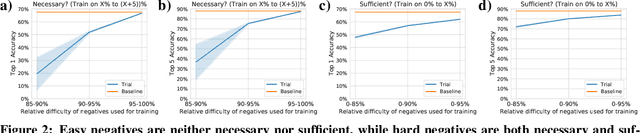
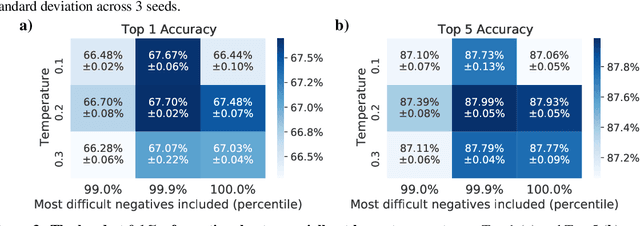
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.
Pruning Neural Networks at Initialization: Why are We Missing the Mark?
Sep 18, 2020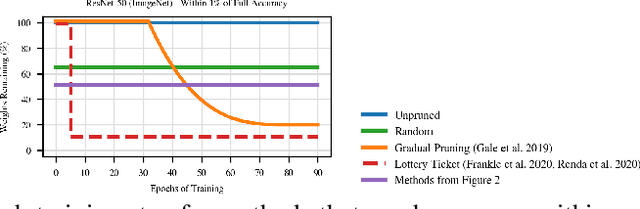

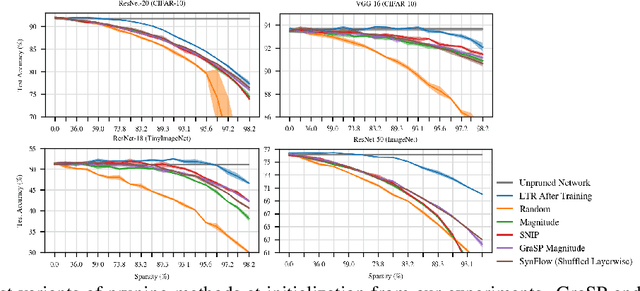
Recent work has explored the possibility of pruning neural networks at initialization. We assess proposals for doing so: SNIP (Lee et al., 2019), GraSP (Wang et al., 2020), SynFlow (Tanaka et al., 2020), and magnitude pruning. Although these methods surpass the trivial baseline of random pruning, they remain below the accuracy of magnitude pruning after training, and we endeavor to understand why. We show that, unlike pruning after training, accuracy is the same or higher when randomly shuffling which weights these methods prune within each layer or sampling new initial values. As such, the per-weight pruning decisions made by these methods can be replaced by a per-layer choice of the fraction of weights to prune. This property undermines the claimed justifications for these methods and suggests broader challenges with the underlying pruning heuristics, the desire to prune at initialization, or both.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks
Jul 23, 2020In natural language processing (NLP), enormous pre-trained models like BERT have become the standard starting point for training on a range of downstream tasks, and similar trends are emerging in other areas of deep learning. In parallel, work on the lottery ticket hypothesis has shown that models for NLP and computer vision contain smaller matching subnetworks capable of training in isolation to full accuracy and transferring to other tasks. In this work, we combine these observations to assess whether such trainable, transferrable subnetworks exist in pre-trained BERT models. For a range of downstream tasks, we indeed find matching subnetworks at 40% to 90% sparsity. We find these subnetworks at (pre-trained) initialization, a deviation from prior NLP research where they emerge only after some amount of training. Subnetworks found on the masked language modeling task (the same task used to pre-train the model) transfer universally; those found on other tasks transfer in a limited fashion if at all. As large-scale pre-training becomes an increasingly central paradigm in deep learning, our results demonstrate that the main lottery ticket observations remain relevant in this context. Codes available at https://github.com/TAMU-VITA/BERT-Tickets.
On the Predictability of Pruning Across Scales
Jun 19, 2020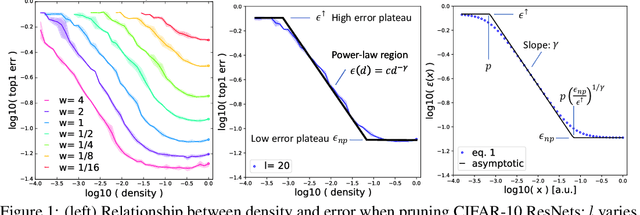
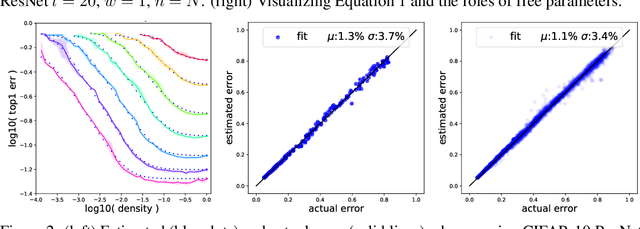
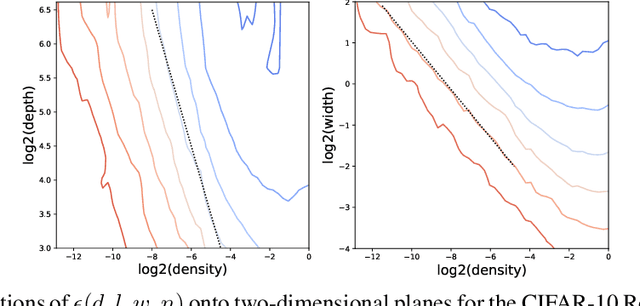
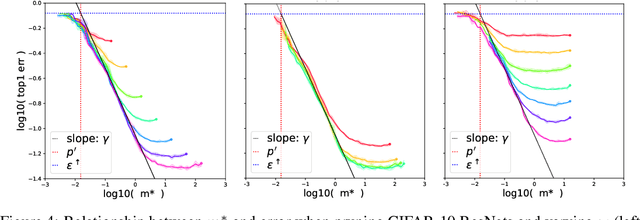
We show that the error of magnitude-pruned networks follows a scaling law, and that this law is of a fundamentally different nature than that of unpruned networks. We functionally approximate the error of the pruned networks, showing that it is predictable in terms of an invariant tying width, depth, and pruning level, such that networks of vastly different sparsities are freely interchangeable. We demonstrate the accuracy of this functional approximation over scales spanning orders of magnitude in depth, width, dataset size, and sparsity for CIFAR-10 and ImageNet. As neural networks become ever larger and more expensive to train, our findings enable a framework for reasoning conceptually and analytically about pruning.
What is the State of Neural Network Pruning?
Mar 06, 2020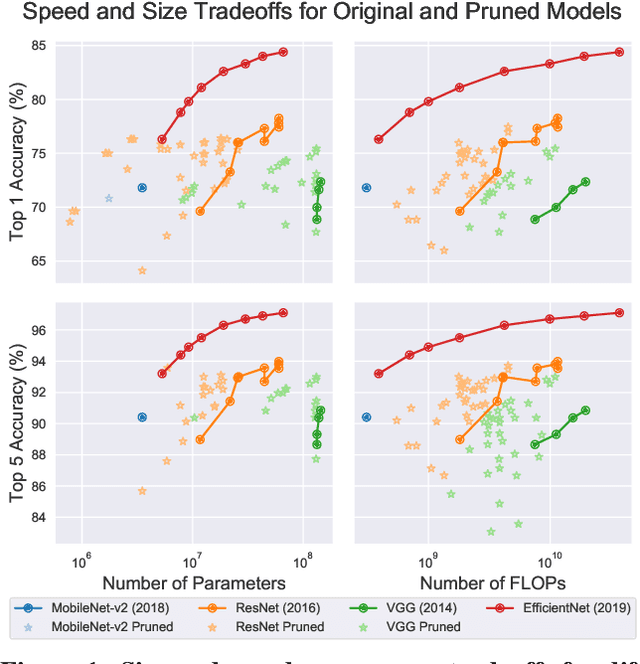
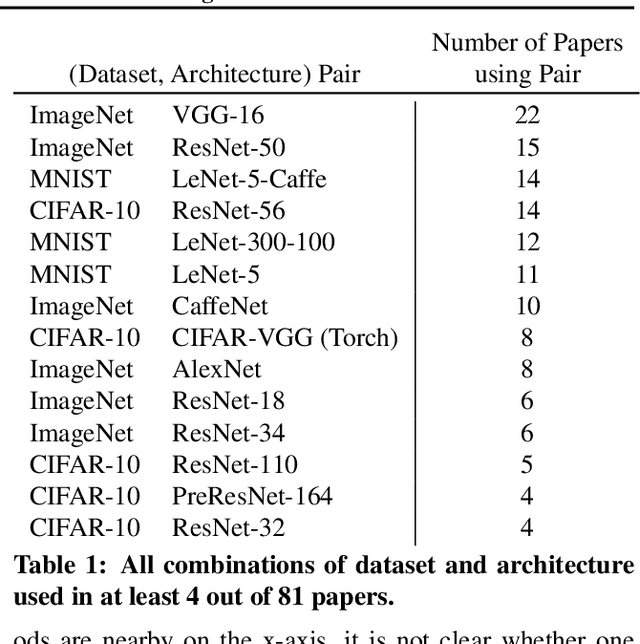
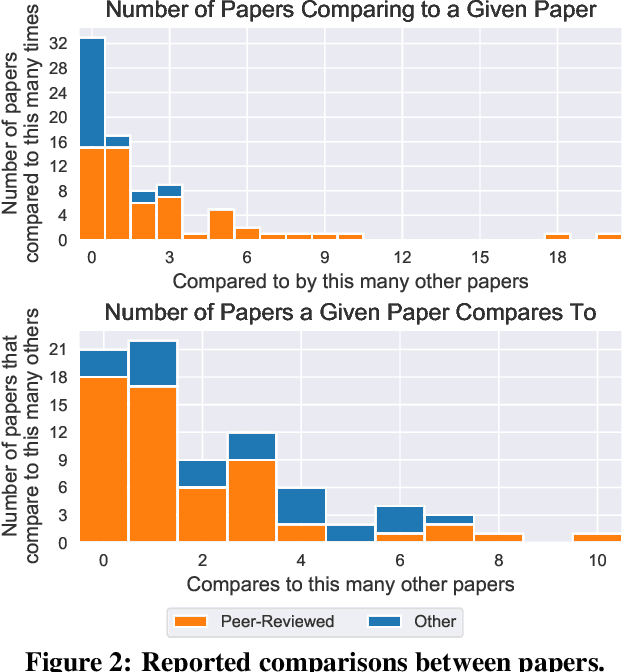
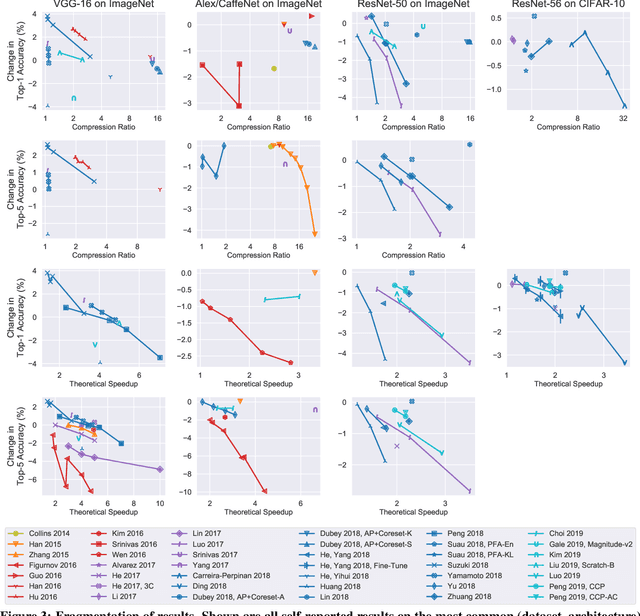
Neural network pruning---the task of reducing the size of a network by removing parameters---has been the subject of a great deal of work in recent years. We provide a meta-analysis of the literature, including an overview of approaches to pruning and consistent findings in the literature. After aggregating results across 81 papers and pruning hundreds of models in controlled conditions, our clearest finding is that the community suffers from a lack of standardized benchmarks and metrics. This deficiency is substantial enough that it is hard to compare pruning techniques to one another or determine how much progress the field has made over the past three decades. To address this situation, we identify issues with current practices, suggest concrete remedies, and introduce ShrinkBench, an open-source framework to facilitate standardized evaluations of pruning methods. We use ShrinkBench to compare various pruning techniques and show that its comprehensive evaluation can prevent common pitfalls when comparing pruning methods.
Comparing Rewinding and Fine-tuning in Neural Network Pruning
Mar 05, 2020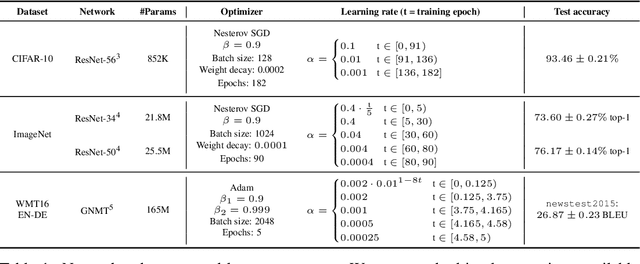
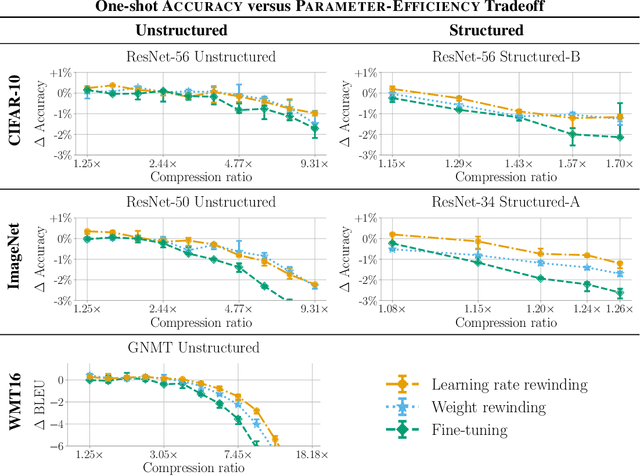
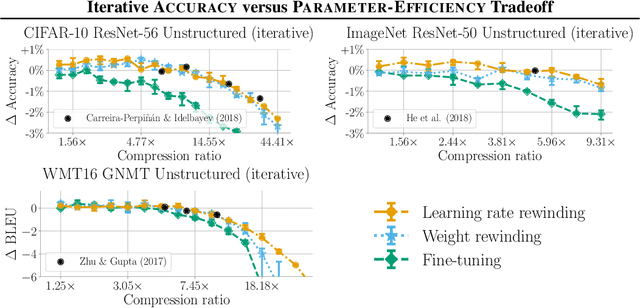
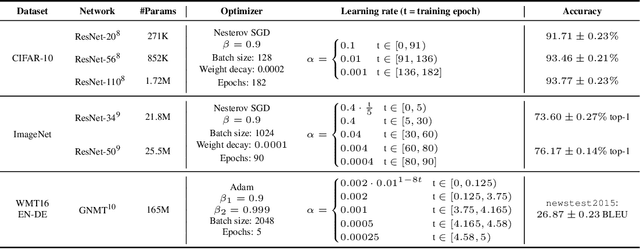
Many neural network pruning algorithms proceed in three steps: train the network to completion, remove unwanted structure to compress the network, and retrain the remaining structure to recover lost accuracy. The standard retraining technique, fine-tuning, trains the unpruned weights from their final trained values using a small fixed learning rate. In this paper, we compare fine-tuning to alternative retraining techniques. Weight rewinding (as proposed by Frankle et al., (2019)), rewinds unpruned weights to their values from earlier in training and retrains them from there using the original training schedule. Learning rate rewinding (which we propose) trains the unpruned weights from their final values using the same learning rate schedule as weight rewinding. Both rewinding techniques outperform fine-tuning, forming the basis of a network-agnostic pruning algorithm that matches the accuracy and compression ratios of several more network-specific state-of-the-art techniques.
Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs
Feb 29, 2020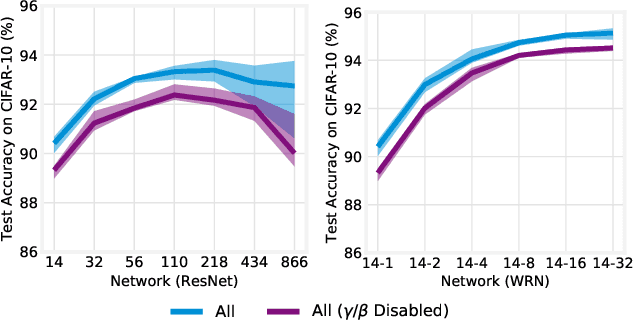
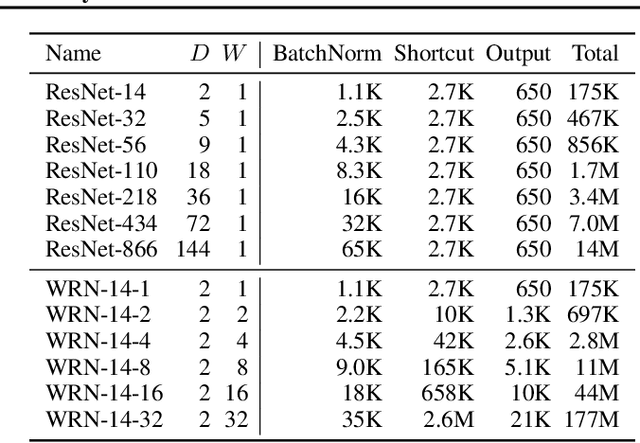
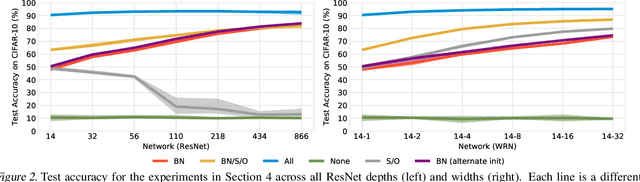
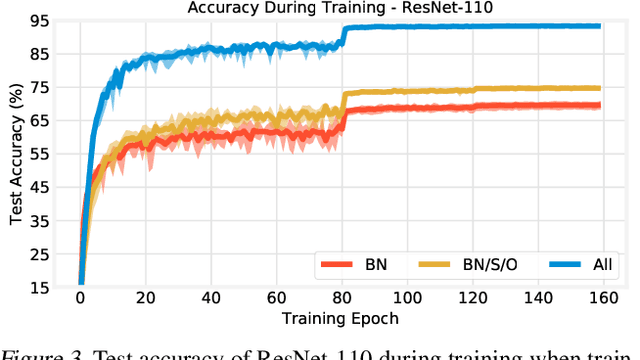
Batch normalization (BatchNorm) has become an indispensable tool for training deep neural networks, yet it is still poorly understood. Although previous work has typically focused on its normalization component, BatchNorm also adds two per-feature trainable parameters: a coefficient and a bias. However, the role and expressive power of these parameters remains unclear. To study this question, we investigate the performance achieved when training only these parameters and freezing all others at their random initializations. We find that doing so leads to surprisingly high performance. For example, a sufficiently deep ResNet reaches 83% accuracy on CIFAR-10 in this configuration. Interestingly, BatchNorm achieves this performance in part by naturally learning to disable around a third of the random features without any changes to the training objective. Not only do these results highlight the under-appreciated role of the affine parameters in BatchNorm, but - in a broader sense - they characterize the expressive power of neural networks constructed simply by shifting and rescaling random features.