 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Data Dimensionality on Neural Network Prunability
Dec 01, 2022



Practitioners prune neural networks for efficiency gains and generalization improvements, but few scrutinize the factors determining the prunability of a neural network the maximum fraction of weights that pruning can remove without compromising the model's test accuracy. In this work, we study the properties of input data that may contribute to the prunability of a neural network. For high dimensional input data such as images, text, and audio, the manifold hypothesis suggests that these high dimensional inputs approximately lie on or near a significantly lower dimensional manifold. Prior work demonstrates that the underlying low dimensional structure of the input data may affect the sample efficiency of learning. In this paper, we investigate whether the low dimensional structure of the input data affects the prunability of a neural network.
Reduce, Reuse, Recycle: Improving Training Efficiency with Distillation
Nov 01, 2022Methods for improving the efficiency of deep network training (i.e. the resources required to achieve a given level of model quality) are of immediate benefit to deep learning practitioners. Distillation is typically used to compress models or improve model quality, but it's unclear if distillation actually improves training efficiency. Can the quality improvements of distillation be converted into training speed-ups, or do they simply increase final model quality with no resource savings? We conducted a series of experiments to investigate whether and how distillation can be used to accelerate training using ResNet-50 trained on ImageNet and BERT trained on C4 with a masked language modeling objective and evaluated on GLUE, using common enterprise hardware (8x NVIDIA A100). We found that distillation can speed up training by up to 1.96x in ResNet-50 trained on ImageNet and up to 1.42x on BERT when evaluated on GLUE. Furthermore, distillation for BERT yields optimal results when it is only performed for the first 20-50% of training. We also observed that training with distillation is almost always more efficient than training without distillation, even when using the poorest-quality model as a teacher, in both ResNet-50 and BERT. Finally, we found that it's possible to gain the benefit of distilling from an ensemble of teacher models, which has O(n) runtime cost, by randomly sampling a single teacher from the pool of teacher models on each step, which only has a O(1) runtime cost. Taken together, these results show that distillation can substantially improve training efficiency in both image classification and language modeling, and that a few simple optimizations to distillation protocols can further enhance these efficiency improvements.
Pruning's Effect on Generalization Through the Lens of Training and Regularization
Oct 25, 2022



Practitioners frequently observe that pruning improves model generalization. A long-standing hypothesis based on bias-variance trade-off attributes this generalization improvement to model size reduction. However, recent studies on over-parameterization characterize a new model size regime, in which larger models achieve better generalization. Pruning models in this over-parameterized regime leads to a contradiction -- while theory predicts that reducing model size harms generalization, pruning to a range of sparsities nonetheless improves it. Motivated by this contradiction, we re-examine pruning's effect on generalization empirically. We show that size reduction cannot fully account for the generalization-improving effect of standard pruning algorithms. Instead, we find that pruning leads to better training at specific sparsities, improving the training loss over the dense model. We find that pruning also leads to additional regularization at other sparsities, reducing the accuracy degradation due to noisy examples over the dense model. Pruning extends model training time and reduces model size. These two factors improve training and add regularization respectively. We empirically demonstrate that both factors are essential to fully explaining pruning's impact on generalization.
* 49 pages, 20 figures
Unmasking the Lottery Ticket Hypothesis: What's Encoded in a Winning Ticket's Mask?
Oct 06, 2022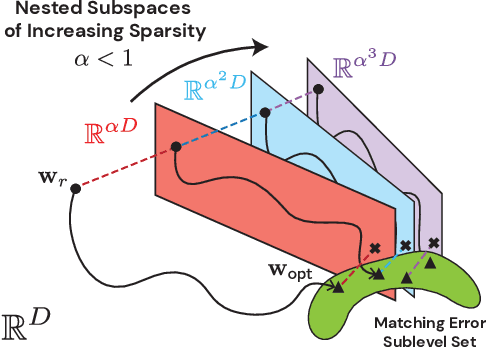
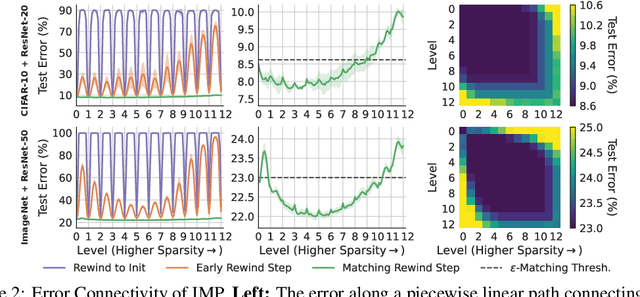
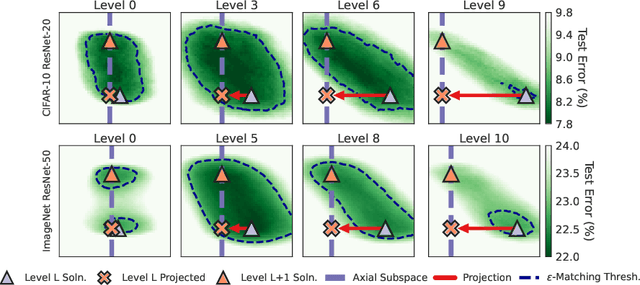
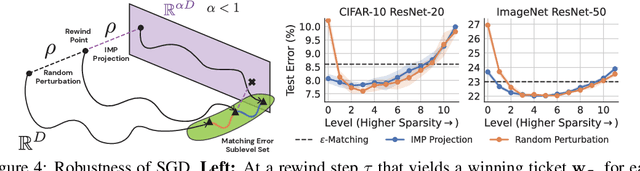
Modern deep learning involves training costly, highly overparameterized networks, thus motivating the search for sparser networks that can still be trained to the same accuracy as the full network (i.e. matching). Iterative magnitude pruning (IMP) is a state of the art algorithm that can find such highly sparse matching subnetworks, known as winning tickets. IMP operates by iterative cycles of training, masking smallest magnitude weights, rewinding back to an early training point, and repeating. Despite its simplicity, the underlying principles for when and how IMP finds winning tickets remain elusive. In particular, what useful information does an IMP mask found at the end of training convey to a rewound network near the beginning of training? How does SGD allow the network to extract this information? And why is iterative pruning needed? We develop answers in terms of the geometry of the error landscape. First, we find that$\unicode{x2014}$at higher sparsities$\unicode{x2014}$pairs of pruned networks at successive pruning iterations are connected by a linear path with zero error barrier if and only if they are matching. This indicates that masks found at the end of training convey the identity of an axial subspace that intersects a desired linearly connected mode of a matching sublevel set. Second, we show SGD can exploit this information due to a strong form of robustness: it can return to this mode despite strong perturbations early in training. Third, we show how the flatness of the error landscape at the end of training determines a limit on the fraction of weights that can be pruned at each iteration of IMP. Finally, we show that the role of retraining in IMP is to find a network with new small weights to prune. Overall, these results make progress toward demystifying the existence of winning tickets by revealing the fundamental role of error landscape geometry.
Non-Determinism and the Lawlessness of ML Code
Jun 23, 2022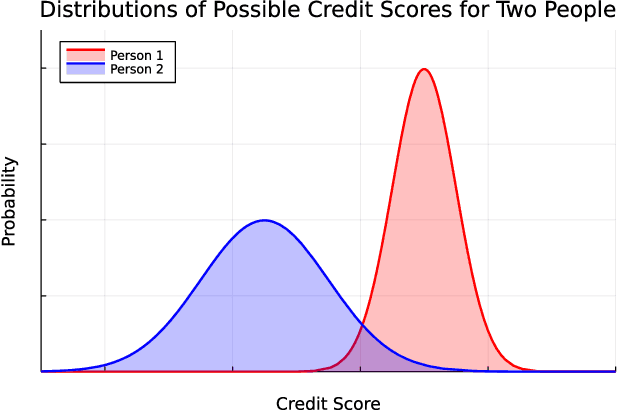
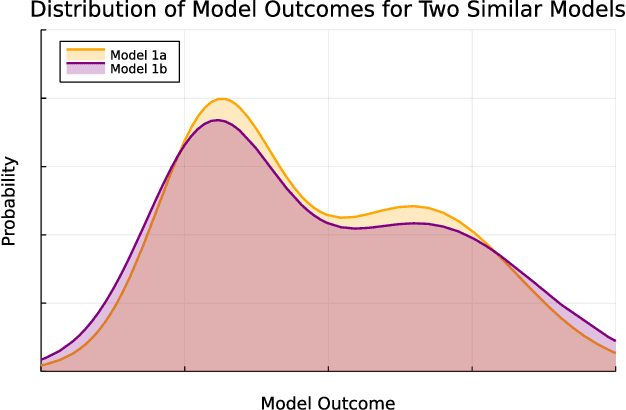
Legal literature on machine learning (ML) tends to focus on harms, and as a result tends to reason about individual model outcomes and summary error rates. This focus on model-level outcomes and errors has masked important aspects of ML that are rooted in its inherent non-determinism. We show that the effects of non-determinism, and consequently its implications for the law, instead become clearer from the perspective of reasoning about ML outputs as probability distributions over possible outcomes. This distributional viewpoint accounts for non-determinism by emphasizing the possible outcomes of ML. Importantly, this type of reasoning is not exclusive with current legal reasoning; it complements (and in fact can strengthen) analyses concerning individual, concrete outcomes for specific automated decisions. By clarifying the important role of non-determinism, we demonstrate that ML code falls outside of the cyberlaw frame of treating "code as law," as this frame assumes that code is deterministic. We conclude with a brief discussion of what work ML can do to constrain the potentially harm-inducing effects of non-determinism, and we clarify where the law must do work to bridge the gap between its current individual-outcome focus and the distributional approach that we recommend.
Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks
Jun 02, 2022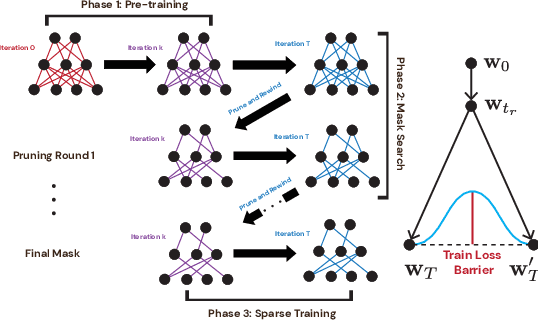
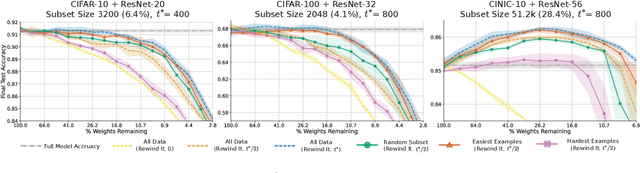

A striking observation about iterative magnitude pruning (IMP; Frankle et al. 2020) is that $\unicode{x2014}$ after just a few hundred steps of dense training $\unicode{x2014}$ the method can find a sparse sub-network that can be trained to the same accuracy as the dense network. However, the same does not hold at step 0, i.e. random initialization. In this work, we seek to understand how this early phase of pre-training leads to a good initialization for IMP both through the lens of the data distribution and the loss landscape geometry. Empirically we observe that, holding the number of pre-training iterations constant, training on a small fraction of (randomly chosen) data suffices to obtain an equally good initialization for IMP. We additionally observe that by pre-training only on "easy" training data, we can decrease the number of steps necessary to find a good initialization for IMP compared to training on the full dataset or a randomly chosen subset. Finally, we identify novel properties of the loss landscape of dense networks that are predictive of IMP performance, showing in particular that more examples being linearly mode connected in the dense network correlates well with good initializations for IMP. Combined, these results provide new insight into the role played by the early phase training in IMP.
Fast Benchmarking of Accuracy vs. Training Time with Cyclic Learning Rates
Jun 02, 2022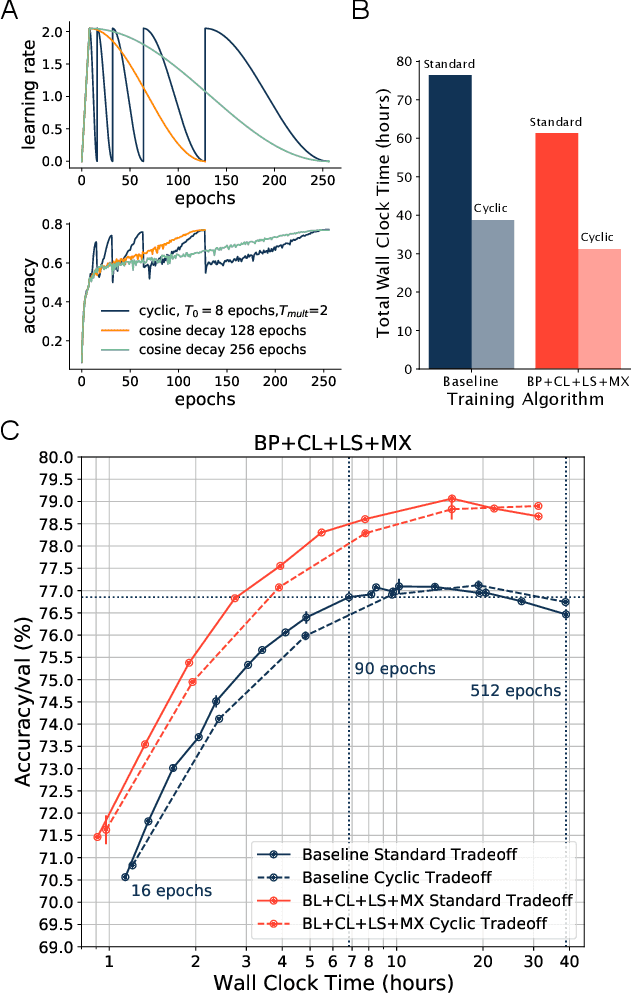
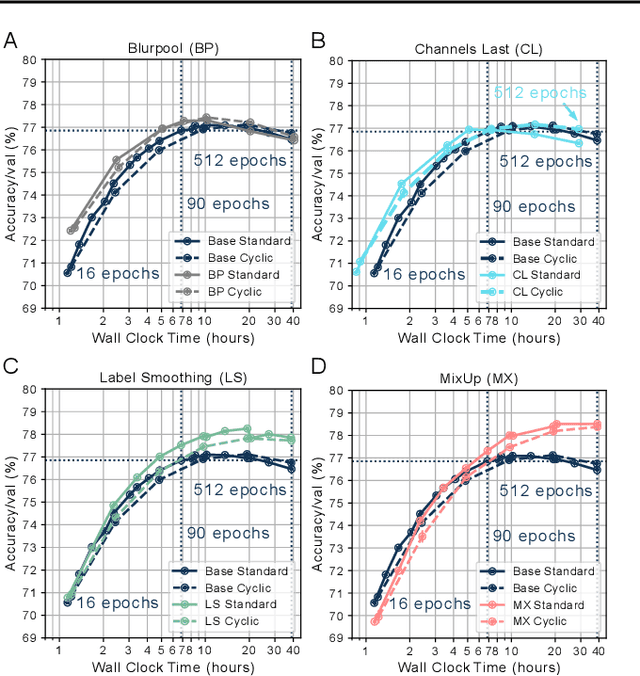
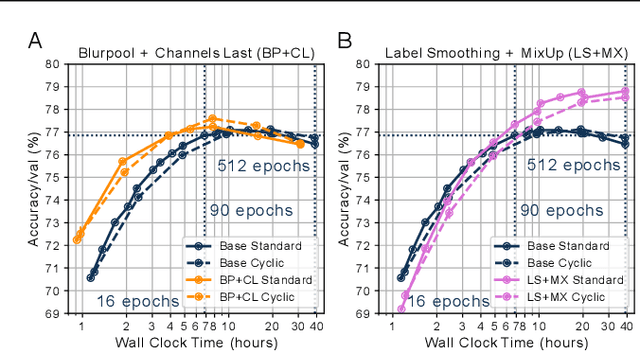
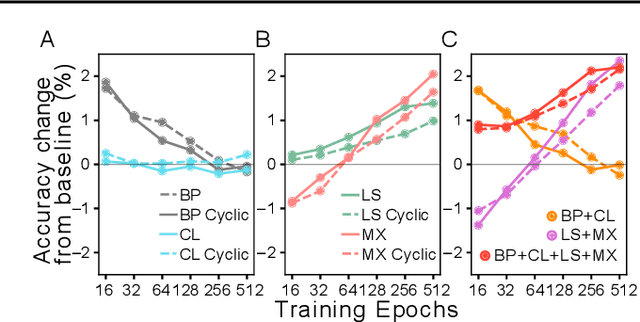
Benchmarking the tradeoff between neural network accuracy and training time is computationally expensive. Here we show how a multiplicative cyclic learning rate schedule can be used to construct a tradeoff curve in a single training run. We generate cyclic tradeoff curves for combinations of training methods such as Blurpool, Channels Last, Label Smoothing and MixUp, and highlight how these cyclic tradeoff curves can be used to evaluate the effects of algorithmic choices on network training efficiency.
Strengthening Subcommunities: Towards Sustainable Growth in AI Research
Apr 18, 2022AI's rapid growth has been felt acutely by scholarly venues, leading to growing pains within the peer review process. These challenges largely center on the inability of specific subareas to identify and evaluate work that is appropriate according to criteria relevant to each subcommunity as determined by stakeholders of that subarea. We set forth a proposal that re-focuses efforts within these subcommunities through a decentralization of the reviewing and publication process. Through this re-centering effort, we hope to encourage each subarea to confront the issues specific to their process of academic publication and incentivization. This model has historically been successful for several subcommunities in AI, and we highlight those instances as examples for how the broader field can continue to evolve despite its continually growing size.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021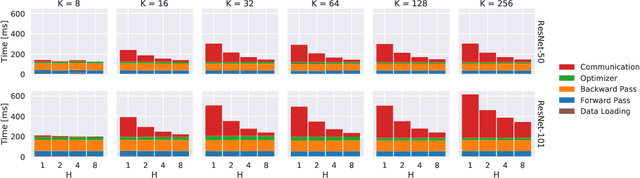
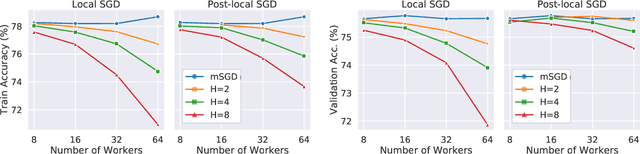
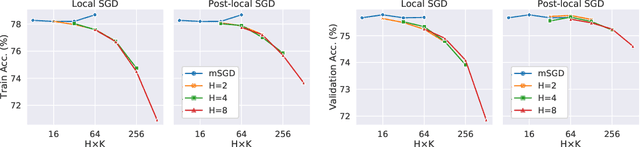
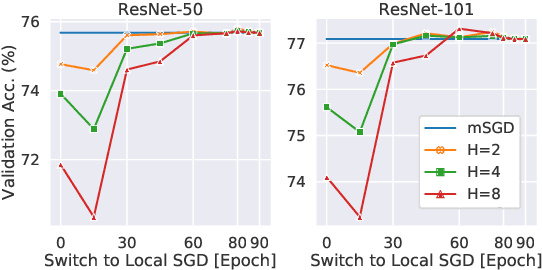
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
What can linear interpolation of neural network loss landscapes tell us?
Jun 30, 2021
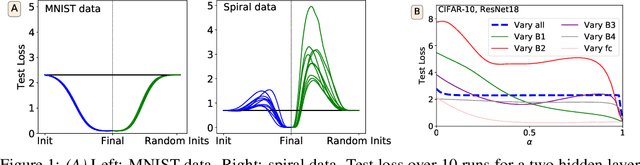
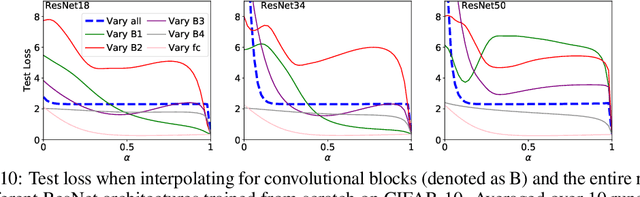
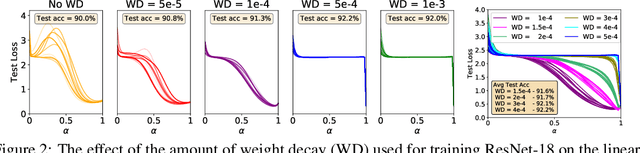
Studying neural network loss landscapes provides insights into the nature of the underlying optimization problems. Unfortunately, loss landscapes are notoriously difficult to visualize in a human-comprehensible fashion. One common way to address this problem is to plot linear slices of the landscape, for example from the initial state of the network to the final state after optimization. On the basis of this analysis, prior work has drawn broader conclusions about the difficulty of the optimization problem. In this paper, we put inferences of this kind to the test, systematically evaluating how linear interpolation and final performance vary when altering the data, choice of initialization, and other optimizer and architecture design choices. Further, we use linear interpolation to study the role played by individual layers and substructures of the network. We find that certain layers are more sensitive to the choice of initialization and optimizer hyperparameter settings, and we exploit these observations to design custom optimization schemes. However, our results cast doubt on the broader intuition that the presence or absence of barriers when interpolating necessarily relates to the success of optimization.