 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpand Neurons, Not Parameters
Oct 06, 2025



This work demonstrates how increasing the number of neurons in a network without increasing its number of non-zero parameters improves performance. We show that this gain corresponds with a decrease in interference between multiple features that would otherwise share the same neurons. To reduce such entanglement at a fixed non-zero parameter count, we introduce Fixed Parameter Expansion (FPE): replace a neuron with multiple children and partition the parent's weights disjointly across them, so that each child inherits a non-overlapping subset of connections. On symbolic tasks, specifically Boolean code problems, clause-aligned FPE systematically reduces polysemanticity metrics and yields higher task accuracy. Notably, random splits of neuron weights approximate these gains, indicating that reduced collisions, not precise assignment, are a primary driver. Consistent with the superposition hypothesis, the benefits of FPE grow with increasing interference: when polysemantic load is high, accuracy improvements are the largest. Transferring these insights to real models (classifiers over CLIP embeddings and deeper multilayer networks) we find that widening networks while maintaining a constant non-zero parameter count consistently increases accuracy. These results identify an interpretability-grounded mechanism to leverage width against superposition, improving performance without increasing the number of non-zero parameters. Such a direction is well matched to modern accelerators, where memory movement of non-zero parameters, rather than raw compute, is the dominant bottleneck.
Frontier AI Regulation: Managing Emerging Risks to Public Safety
Jul 11, 2023Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
Tools for Verifying Neural Models' Training Data
Jul 02, 2023



It is important that consumers and regulators can verify the provenance of large neural models to evaluate their capabilities and risks. We introduce the concept of a "Proof-of-Training-Data": any protocol that allows a model trainer to convince a Verifier of the training data that produced a set of model weights. Such protocols could verify the amount and kind of data and compute used to train the model, including whether it was trained on specific harmful or beneficial data sources. We explore efficient verification strategies for Proof-of-Training-Data that are compatible with most current large-model training procedures. These include a method for the model-trainer to verifiably pre-commit to a random seed used in training, and a method that exploits models' tendency to temporarily overfit to training data in order to detect whether a given data-point was included in training. We show experimentally that our verification procedures can catch a wide variety of attacks, including all known attacks from the Proof-of-Learning literature.
What does it take to catch a Chinchilla? Verifying Rules on Large-Scale Neural Network Training via Compute Monitoring
Mar 20, 2023


As advanced machine learning systems' capabilities begin to play a significant role in geopolitics and societal order, it may become imperative that (1) governments be able to enforce rules on the development of advanced ML systems within their borders, and (2) countries be able to verify each other's compliance with potential future international agreements on advanced ML development. This work analyzes one mechanism to achieve this, by monitoring the computing hardware used for large-scale NN training. The framework's primary goal is to provide governments high confidence that no actor uses large quantities of specialized ML chips to execute a training run in violation of agreed rules. At the same time, the system does not curtail the use of consumer computing devices, and maintains the privacy and confidentiality of ML practitioners' models, data, and hyperparameters. The system consists of interventions at three stages: (1) using on-chip firmware to occasionally save snapshots of the the neural network weights stored in device memory, in a form that an inspector could later retrieve; (2) saving sufficient information about each training run to prove to inspectors the details of the training run that had resulted in the snapshotted weights; and (3) monitoring the chip supply chain to ensure that no actor can avoid discovery by amassing a large quantity of un-tracked chips. The proposed design decomposes the ML training rule verification problem into a series of narrow technical challenges, including a new variant of the Proof-of-Learning problem [Jia et al. '21].
Strengthening Subcommunities: Towards Sustainable Growth in AI Research
Apr 18, 2022AI's rapid growth has been felt acutely by scholarly venues, leading to growing pains within the peer review process. These challenges largely center on the inability of specific subareas to identify and evaluate work that is appropriate according to criteria relevant to each subcommunity as determined by stakeholders of that subarea. We set forth a proposal that re-focuses efforts within these subcommunities through a decentralization of the reviewing and publication process. Through this re-centering effort, we hope to encourage each subarea to confront the issues specific to their process of academic publication and incentivization. This model has historically been successful for several subcommunities in AI, and we highlight those instances as examples for how the broader field can continue to evolve despite its continually growing size.
Learning From Strategic Agents: Accuracy, Improvement, and Causality
Feb 24, 2020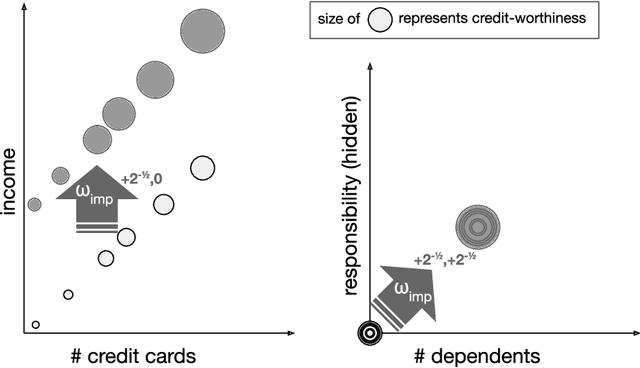
In many predictive decision-making scenarios, such as credit scoring and academic testing, a decision-maker must construct a model (predicting some outcome) that accounts for agents' incentives to "game" their features in order to receive better decisions. Whereas the strategic classification literature generally assumes that agents' outcomes are not causally dependent on their features (and thus strategic behavior is a form of lying), we join concurrent work in modeling agents' outcomes as a function of their changeable attributes. Our formulation is the first to incorporate a crucial phenomenon: when agents act to change observable features, they may as a side effect perturb hidden features that causally affect their true outcomes. We consider three distinct desiderata for a decision-maker's model: accurately predicting agents' post-gaming outcomes (accuracy), incentivizing agents to improve these outcomes (improvement), and, in the linear setting, estimating the visible coefficients of the true causal model (causal precision). As our main contribution, we provide the first algorithms for learning accuracy-optimizing, improvement-optimizing, and causal-precision-optimizing linear regression models directly from data, without prior knowledge of agents' possible actions. These algorithms circumvent the hardness result of Miller et al. (2019) by allowing the decision maker to observe agents' responses to a sequence of decision rules, in effect inducing agents to perform causal interventions for free.
Extracting Incentives from Black-Box Decisions
Oct 13, 2019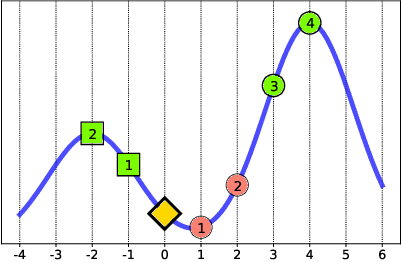
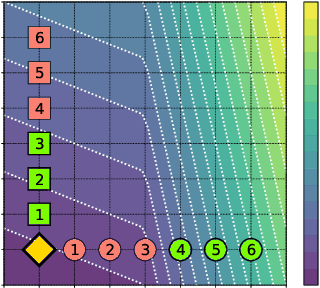
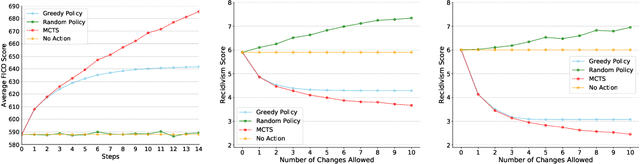
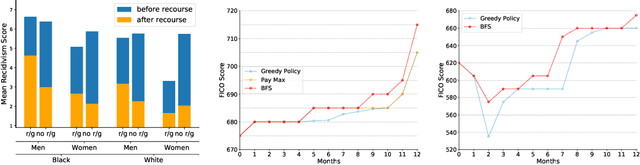
An algorithmic decision-maker incentivizes people to act in certain ways to receive better decisions. These incentives can dramatically influence subjects' behaviors and lives, and it is important that both decision-makers and decision-recipients have clarity on which actions are incentivized by the chosen model. While for linear functions, the changes a subject is incentivized to make may be clear, we prove that for many non-linear functions (e.g. neural networks, random forests), classical methods for interpreting the behavior of models (e.g. input gradients) provide poor advice to individuals on which actions they should take. In this work, we propose a mathematical framework for understanding algorithmic incentives as the challenge of solving a Markov Decision Process, where the state includes the set of input features, and the reward is a function of the model's output. We can then leverage the many toolkits for solving MDPs (e.g. tree-based planning, reinforcement learning) to identify the optimal actions each individual is incentivized to take to improve their decision under a given model. We demonstrate the utility of our method by estimating the maximally-incentivized actions in two real-world settings: a recidivism risk predictor we train using ProPublica's COMPAS dataset, and an online credit scoring tool published by the Fair Isaac Corporation (FICO).