 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Global Neural Discourse Parser
Sep 08, 2020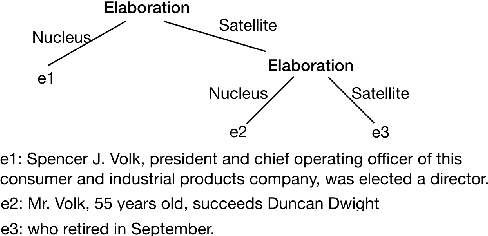
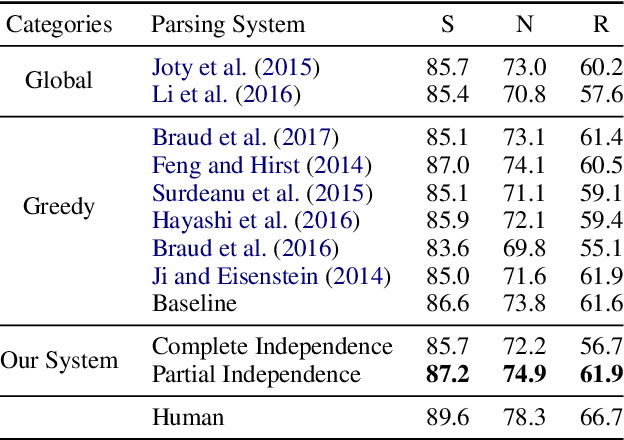
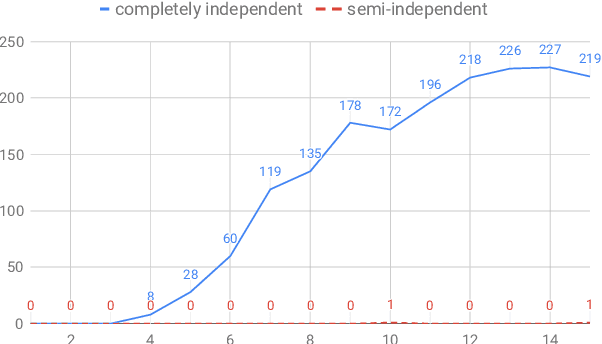
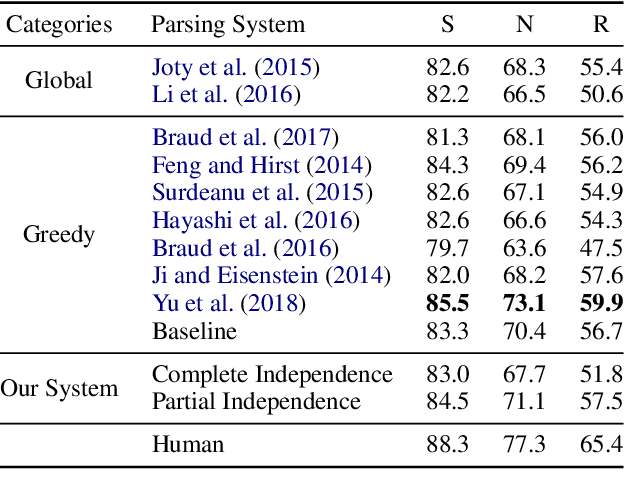
Discourse parsing is largely dominated by greedy parsers with manually-designed features, while global parsing is rare due to its computational expense. In this paper, we propose a simple chart-based neural discourse parser that does not require any manually-crafted features and is based on learned span representations only. To overcome the computational challenge, we propose an independence assumption between the label assigned to a node in the tree and the splitting point that separates its children, which results in tractable decoding. We empirically demonstrate that our model achieves the best performance among global parsers, and comparable performance to state-of-art greedy parsers, using only learned span representations.
Latent Compositional Representations Improve Systematic Generalization in Grounded Question Answering
Jul 01, 2020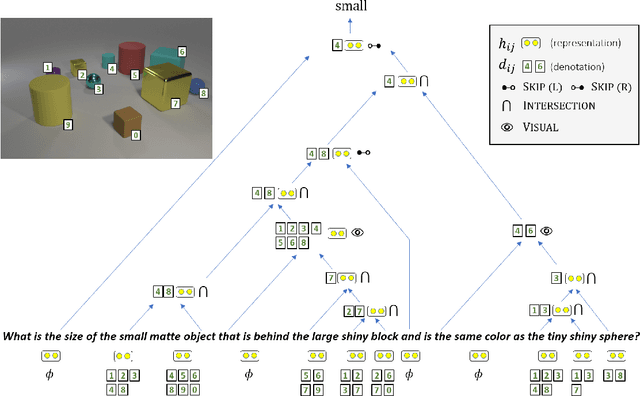


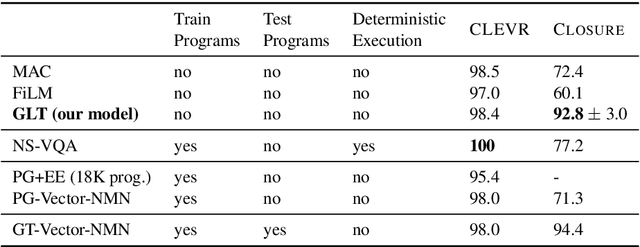
Answering questions that involve multi-step reasoning requires decomposing them and using the answers of intermediate steps to reach the final answer. However, state-of-the-art models in grounded question answering often do not explicitly perform decomposition, leading to difficulties in generalization to out-of-distribution examples. In this work, we propose a model that computes a representation and denotation for all question spans in a bottom-up, compositional manner using a CKY-style parser. Our model effectively induces latent trees, driven by end-to-end (the answer) supervision only. We show that this inductive bias towards tree structures dramatically improves systematic generalization to out-of-distribution examples compared to strong baselines on an arithmetic expressions benchmark as well as on CLOSURE, a dataset that focuses on systematic generalization of models for grounded question answering. On this challenging dataset, our model reaches an accuracy of 92.8%, significantly higher than prior models that almost perfectly solve the task on a random, in-distribution split.
Teaching Pre-Trained Models to Systematically Reason Over Implicit Knowledge
Jun 19, 2020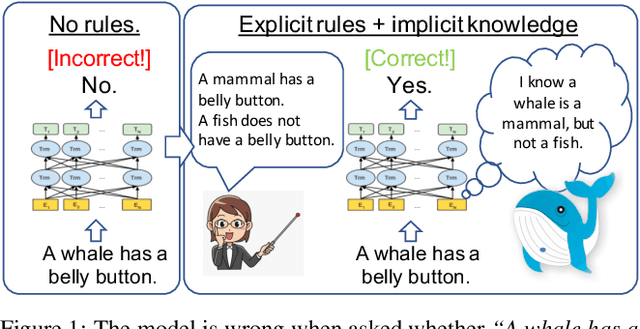
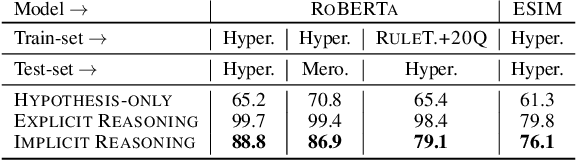
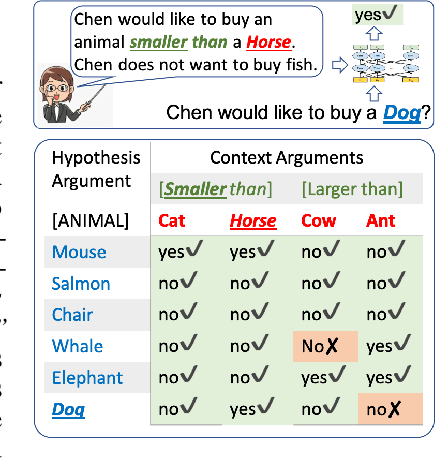
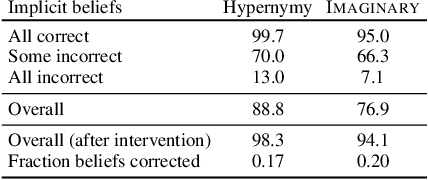
To what extent can a neural network systematically reason over symbolic facts? Evidence suggests that large pre-trained language models (LMs) acquire some reasoning capacity, but this ability is difficult to control. Recently, it has been shown that Transformer-based models succeed in consistent reasoning over explicit symbolic facts, under a "closed-world" assumption. However, in an open-domain setup, it is desirable to tap into the vast reservoir of implicit knowledge already encoded in the parameters of pre-trained LMs. In this work, we provide a first demonstration that LMs can be trained to reliably perform systematic reasoning combining both implicit, pre-trained knowledge and explicit natural language statements. To do this, we describe a procedure for automatically generating datasets that teach a model new reasoning skills, and demonstrate that models learn to effectively perform inference which involves implicit taxonomic and world knowledge, chaining and counting. Finally, we show that "teaching" models to reason generalizes beyond the training distribution: they successfully compose the usage of multiple reasoning skills in single examples. Our work paves a path towards open-domain systems that constantly improve by interacting with users who can instantly correct a model by adding simple natural language statements.
GMAT: Global Memory Augmentation for Transformers
Jun 05, 2020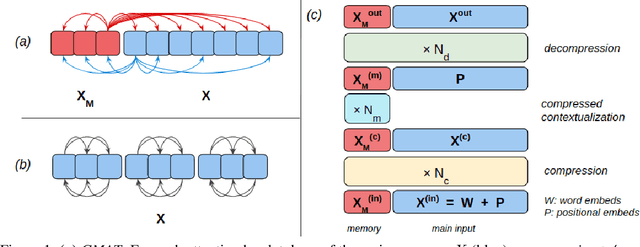
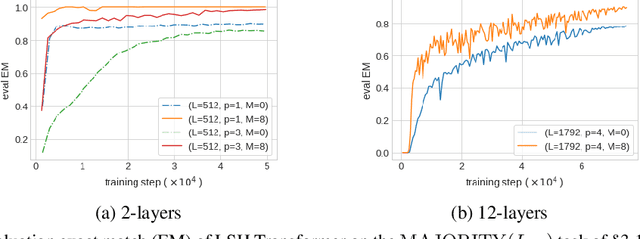
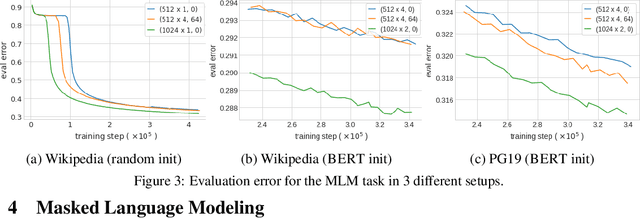

Transformer-based models have become ubiquitous in natural language processing thanks to their large capacity, innate parallelism and high performance. The contextualizing component of a Transformer block is the $\textit{pairwise dot-product}$ attention that has a large $\Omega(L^2)$ memory requirement for length $L$ sequences, limiting its ability to process long documents. This has been the subject of substantial interest recently, where multiple approximations were proposed to reduce the quadratic memory requirement using sparse attention matrices. In this work, we propose to augment sparse Transformer blocks with a dense attention-based $\textit{global memory}$ of length $M$ ($\ll L$) which provides an aggregate global view of the entire input sequence to each position. Our augmentation has a manageable $O(M\cdot(L+M))$ memory overhead, and can be seamlessly integrated with prior sparse solutions. Moreover, global memory can also be used for sequence compression, by representing a long input sequence with the memory representations only. We empirically show that our method leads to substantial improvement on a range of tasks, including (a) synthetic tasks that require global reasoning, (b) masked language modeling, and (c) reading comprehension.
Obtaining Faithful Interpretations from Compositional Neural Networks
May 02, 2020
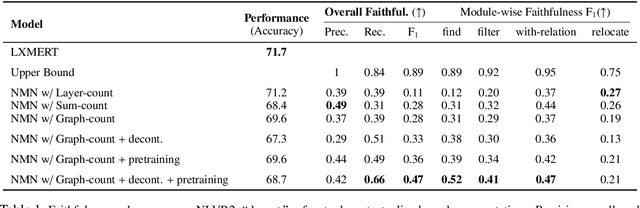
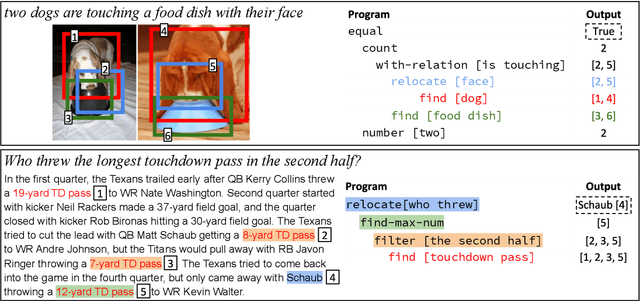
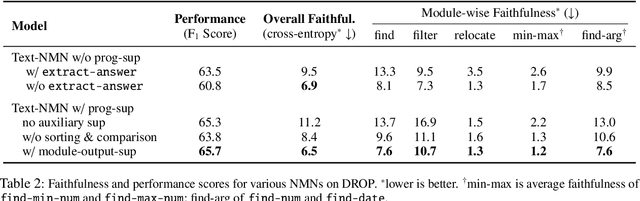
Neural module networks (NMNs) are a popular approach for modeling compositionality: they achieve high accuracy when applied to problems in language and vision, while reflecting the compositional structure of the problem in the network architecture. However, prior work implicitly assumed that the structure of the network modules, describing the abstract reasoning process, provides a faithful explanation of the model's reasoning; that is, that all modules perform their intended behaviour. In this work, we propose and conduct a systematic evaluation of the intermediate outputs of NMNs on NLVR2 and DROP, two datasets which require composing multiple reasoning steps. We find that the intermediate outputs differ from the expected output, illustrating that the network structure does not provide a faithful explanation of model behaviour. To remedy that, we train the model with auxiliary supervision and propose particular choices for module architecture that yield much better faithfulness, at a minimal cost to accuracy.
Evaluating the Evaluation of Diversity in Natural Language Generation
Apr 26, 2020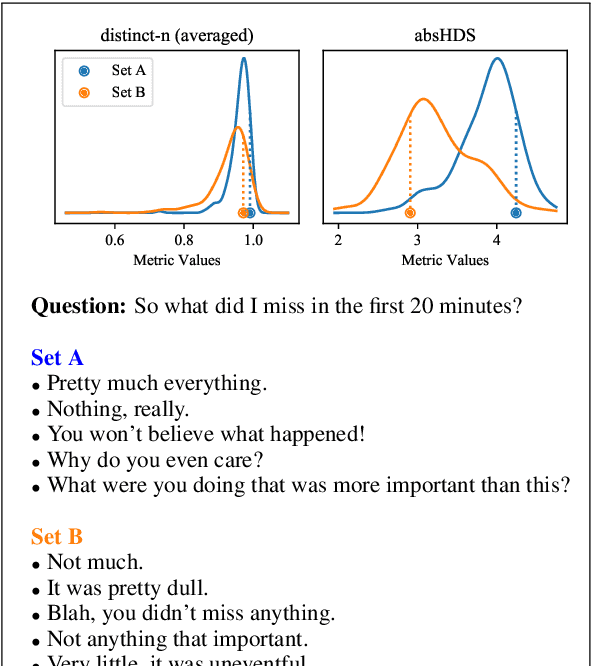

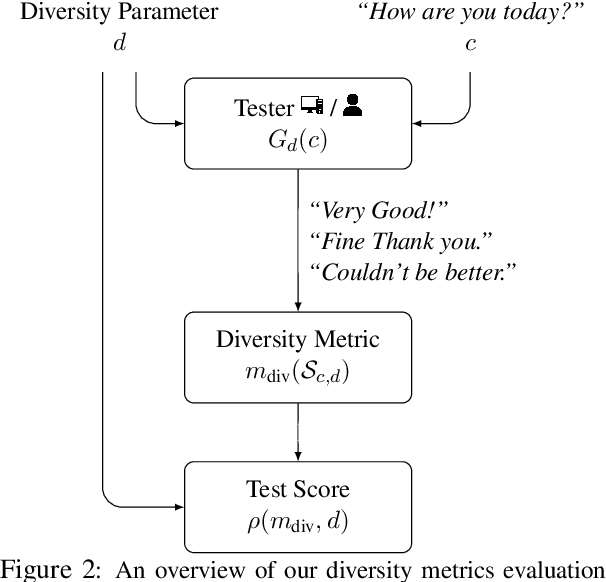
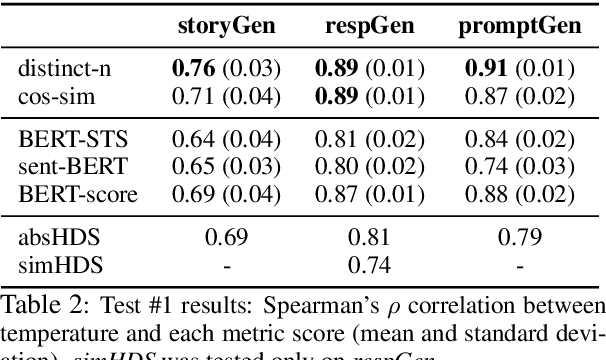
Despite growing interest in natural language generation (NLG) models that produce diverse outputs, there is currently no principled method for evaluating the diversity of an NLG system. In this work, we propose a framework for evaluating diversity metrics. The framework measures the correlation between a proposed diversity metric and a diversity parameter, a single parameter that controls some aspect of diversity in generated text. For example, a diversity parameter might be a binary variable used to instruct crowdsourcing workers to generate text with either low or high content diversity. We demonstrate the utility of our framework by: (a) establishing best practices for eliciting diversity judgments from humans, (b) showing that humans substantially outperform automatic metrics in estimating content diversity, and (c) demonstrating that existing methods for controlling diversity by tuning a "decoding parameter" mostly affect form but not meaning. Our framework can advance the understanding of different diversity metrics, an essential step on the road towards better NLG systems.
Explaining Question Answering Models through Text Generation
Apr 12, 2020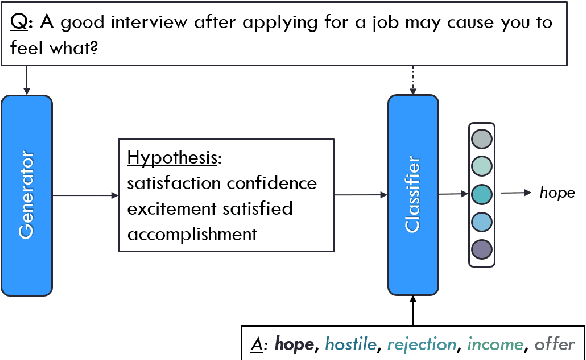
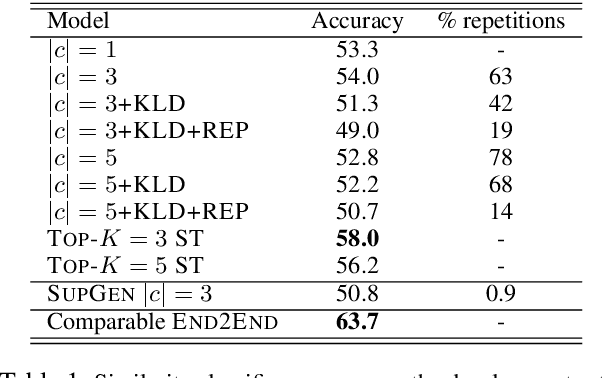

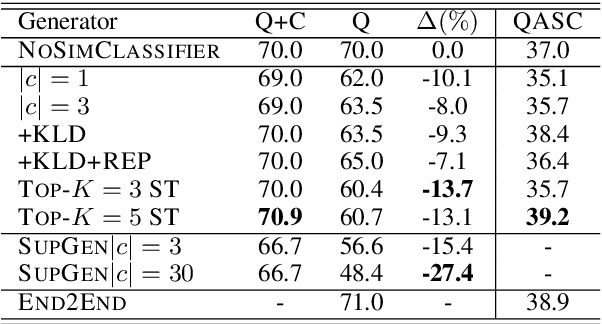
Large pre-trained language models (LMs) have been shown to perform surprisingly well when fine-tuned on tasks that require commonsense and world knowledge. However, in end-to-end architectures, it is difficult to explain what is the knowledge in the LM that allows it to make a correct prediction. In this work, we propose a model for multi-choice question answering, where a LM-based generator generates a textual hypothesis that is later used by a classifier to answer the question. The hypothesis provides a window into the information used by the fine-tuned LM that can be inspected by humans. A key challenge in this setup is how to constrain the model to generate hypotheses that are meaningful to humans. We tackle this by (a) joint training with a simple similarity classifier that encourages meaningful hypotheses, and (b) by adding loss functions that encourage natural text without repetitions. We show on several tasks that our model reaches performance that is comparable to end-to-end architectures, while producing hypotheses that elucidate the knowledge used by the LM for answering the question.
Injecting Numerical Reasoning Skills into Language Models
Apr 09, 2020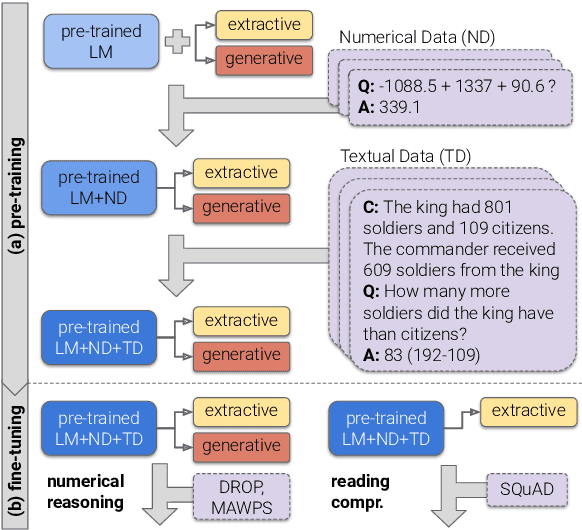

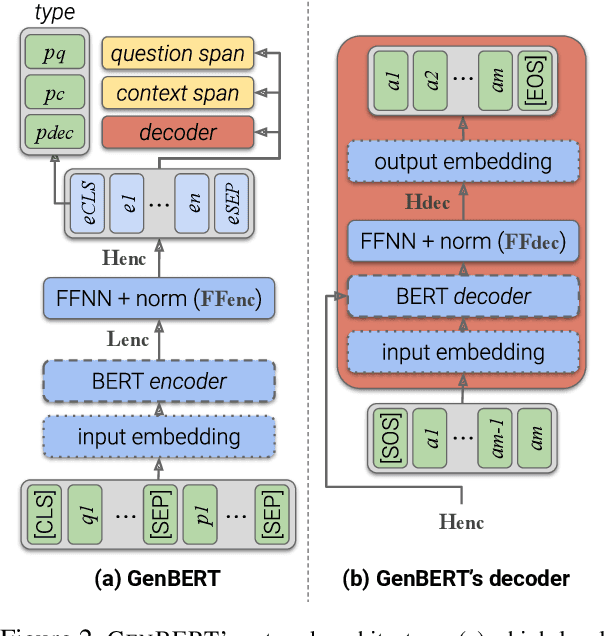

Large pre-trained language models (LMs) are known to encode substantial amounts of linguistic information. However, high-level reasoning skills, such as numerical reasoning, are difficult to learn from a language-modeling objective only. Consequently, existing models for numerical reasoning have used specialized architectures with limited flexibility. In this work, we show that numerical reasoning is amenable to automatic data generation, and thus one can inject this skill into pre-trained LMs, by generating large amounts of data, and training in a multi-task setup. We show that pre-training our model, GenBERT, on this data, dramatically improves performance on DROP (49.3 $\rightarrow$ 72.3 F1), reaching performance that matches state-of-the-art models of comparable size, while using a simple and general-purpose encoder-decoder architecture. Moreover, GenBERT generalizes well to math word problem datasets, while maintaining high performance on standard RC tasks. Our approach provides a general recipe for injecting skills into large pre-trained LMs, whenever the skill is amenable to automatic data augmentation.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
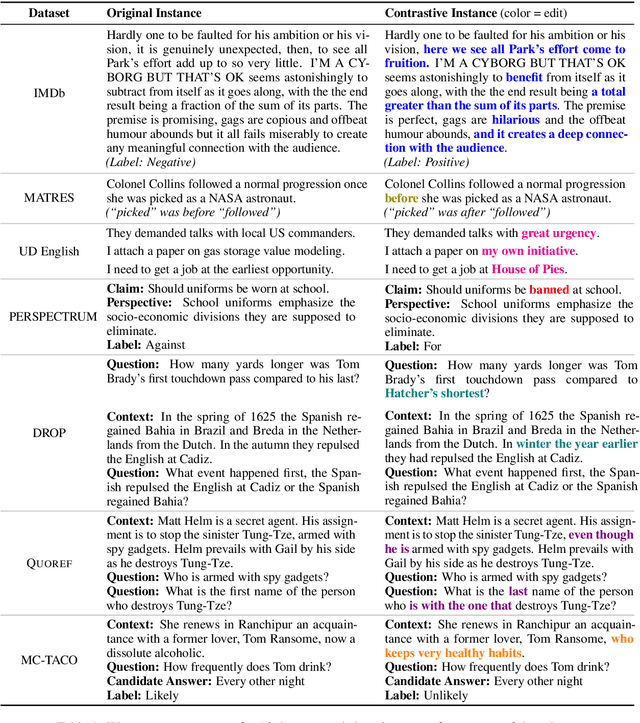
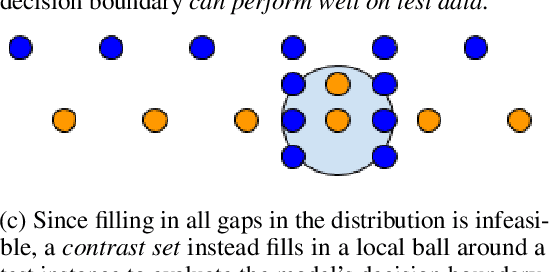
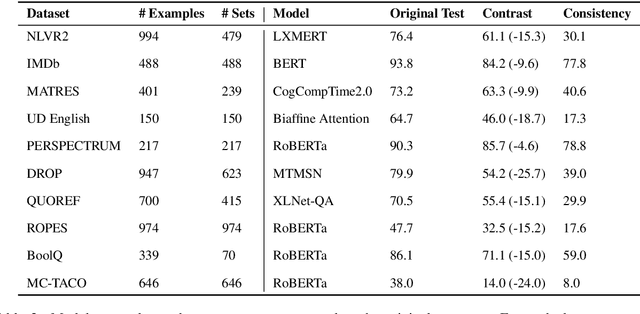
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Break It Down: A Question Understanding Benchmark
Jan 31, 2020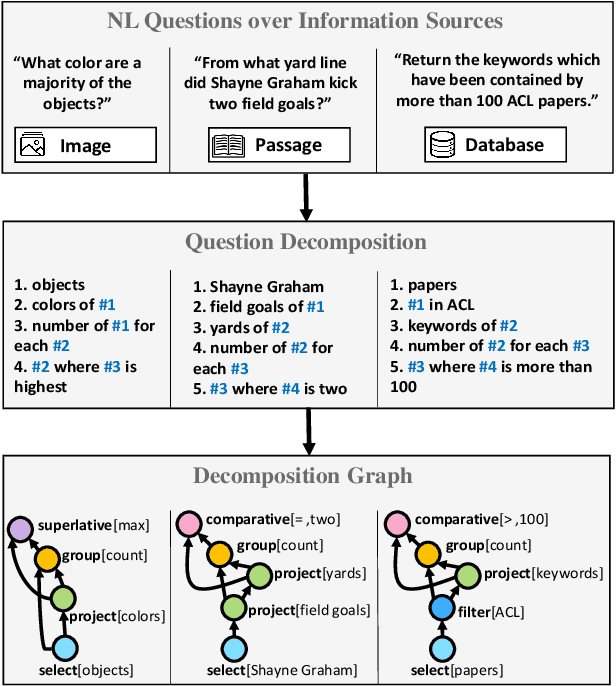
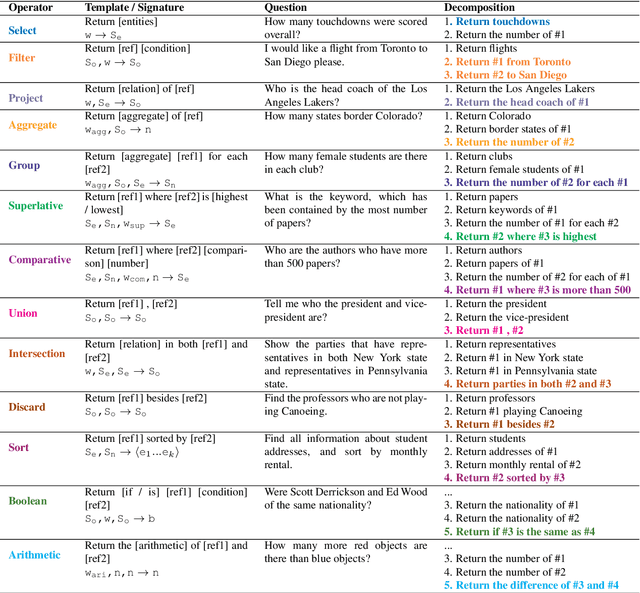
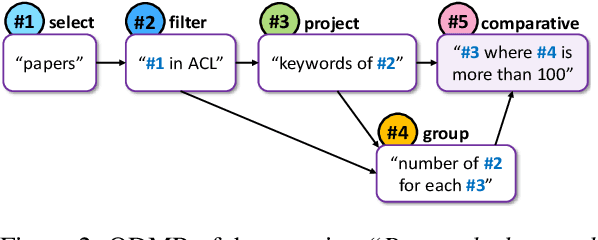

Understanding natural language questions entails the ability to break down a question into the requisite steps for computing its answer. In this work, we introduce a Question Decomposition Meaning Representation (QDMR) for questions. QDMR constitutes the ordered list of steps, expressed through natural language, that are necessary for answering a question. We develop a crowdsourcing pipeline, showing that quality QDMRs can be annotated at scale, and release the Break dataset, containing over 83K pairs of questions and their QDMRs. We demonstrate the utility of QDMR by showing that (a) it can be used to improve open-domain question answering on the HotpotQA dataset, (b) it can be deterministically converted to a pseudo-SQL formal language, which can alleviate annotation in semantic parsing applications. Last, we use Break to train a sequence-to-sequence model with copying that parses questions into QDMR structures, and show that it substantially outperforms several natural baselines.