 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Question Answering Models through Text Generation
Apr 12, 2020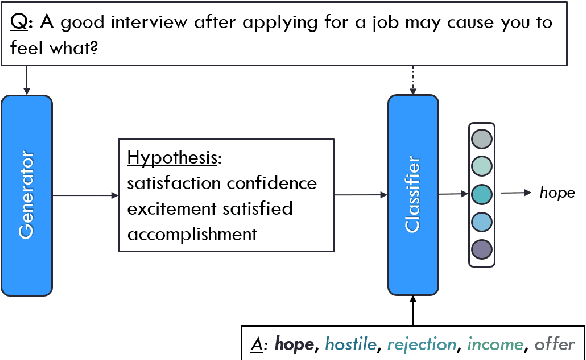
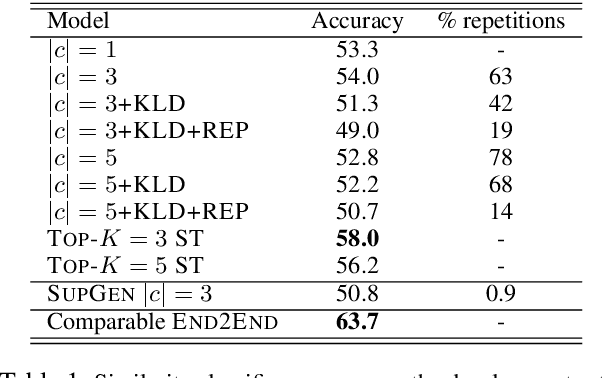

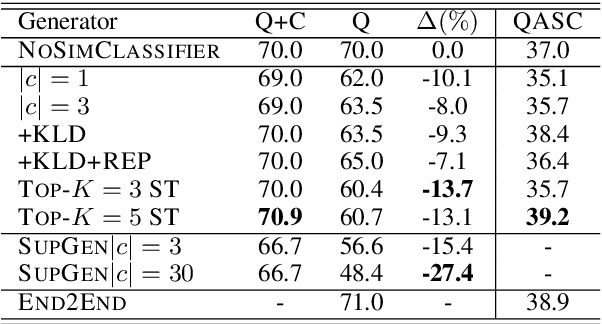
Large pre-trained language models (LMs) have been shown to perform surprisingly well when fine-tuned on tasks that require commonsense and world knowledge. However, in end-to-end architectures, it is difficult to explain what is the knowledge in the LM that allows it to make a correct prediction. In this work, we propose a model for multi-choice question answering, where a LM-based generator generates a textual hypothesis that is later used by a classifier to answer the question. The hypothesis provides a window into the information used by the fine-tuned LM that can be inspected by humans. A key challenge in this setup is how to constrain the model to generate hypotheses that are meaningful to humans. We tackle this by (a) joint training with a simple similarity classifier that encourages meaningful hypotheses, and (b) by adding loss functions that encourage natural text without repetitions. We show on several tasks that our model reaches performance that is comparable to end-to-end architectures, while producing hypotheses that elucidate the knowledge used by the LM for answering the question.
Weakly-supervised Semantic Parsing with Abstract Examples
May 24, 2018


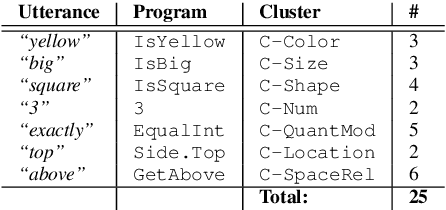
Training semantic parsers from weak supervision (denotations) rather than strong supervision (programs) complicates training in two ways. First, a large search space of potential programs needs to be explored at training time to find a correct program. Second, spurious programs that accidentally lead to a correct denotation add noise to training. In this work we propose that in closed worlds with clear semantic types, one can substantially alleviate these problems by utilizing an abstract representation, where tokens in both the language utterance and program are lifted to an abstract form. We show that these abstractions can be defined with a handful of lexical rules and that they result in sharing between different examples that alleviates the difficulties in training. To test our approach, we develop the first semantic parser for CNLVR, a challenging visual reasoning dataset, where the search space is large and overcoming spuriousness is critical, because denotations are either TRUE or FALSE, and thus random programs are likely to lead to a correct denotation. Our method substantially improves performance, and reaches 82.5% accuracy, a 14.7% absolute accuracy improvement compared to the best reported accuracy so far.