 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPORTANT-Net: Integrated MRI Multi-Parameter Reinforcement Fusion Generator with Attention Network for Synthesizing Absent Data
Feb 03, 2023Magnetic resonance imaging (MRI) is highly sensitive for lesion detection in the breasts. Sequences obtained with different settings can capture the specific characteristics of lesions. Such multi-parameter MRI information has been shown to improve radiologist performance in lesion classification, as well as improving the performance of artificial intelligence models in various tasks. However, obtaining multi-parameter MRI makes the examination costly in both financial and time perspectives, and there may be safety concerns for special populations, thus making acquisition of the full spectrum of MRI sequences less durable. In this study, different than naive input fusion or feature concatenation from existing MRI parameters, a novel $\textbf{I}$ntegrated MRI $\textbf{M}$ulti-$\textbf{P}$arameter reinf$\textbf{O}$rcement fusion generato$\textbf{R}$ wi$\textbf{T}$h $\textbf{A}$tte$\textbf{NT}$ion Network (IMPORTANT-Net) is developed to generate missing parameters. First, the parameter reconstruction module is used to encode and restore the existing MRI parameters to obtain the corresponding latent representation information at any scale level. Then the multi-parameter fusion with attention module enables the interaction of the encoded information from different parameters through a set of algorithmic strategies, and applies different weights to the information through the attention mechanism after information fusion to obtain refined representation information. Finally, a reinforcement fusion scheme embedded in a $V^{-}$-shape generation module is used to combine the hierarchical representations to generate the missing MRI parameter. Results showed that our IMPORTANT-Net is capable of generating missing MRI parameters and outperforms comparable state-of-the-art networks. Our code is available at https://github.com/Netherlands-Cancer-Institute/MRI_IMPORTANT_NET.
Synthesis-based Imaging-Differentiation Representation Learning for Multi-Sequence 3D/4D MRI
Feb 01, 2023



Multi-sequence MRIs can be necessary for reliable diagnosis in clinical practice due to the complimentary information within sequences. However, redundant information exists across sequences, which interferes with mining efficient representations by modern machine learning or deep learning models. To handle various clinical scenarios, we propose a sequence-to-sequence generation framework (Seq2Seq) for imaging-differentiation representation learning. In this study, not only do we propose arbitrary 3D/4D sequence generation within one model to generate any specified target sequence, but also we are able to rank the importance of each sequence based on a new metric estimating the difficulty of a sequence being generated. Furthermore, we also exploit the generation inability of the model to extract regions that contain unique information for each sequence. We conduct extensive experiments using three datasets including a toy dataset of 20,000 simulated subjects, a brain MRI dataset of 1,251 subjects, and a breast MRI dataset of 2,101 subjects, to demonstrate that (1) our proposed Seq2Seq is efficient and lightweight for complex clinical datasets and can achieve excellent image quality; (2) top-ranking sequences can be used to replace complete sequences with non-inferior performance; (3) combining MRI with our imaging-differentiation map leads to better performance in clinical tasks such as glioblastoma MGMT promoter methylation status prediction and breast cancer pathological complete response status prediction. Our code is available at https://github.com/fiy2W/mri_seq2seq.
On Retrospective k-space Subsampling schemes For Deep MRI Reconstruction
Jan 23, 2023



$\textbf{Purpose:}$ The MRI $k$-space acquisition is time consuming. Traditional techniques aim to acquire accelerated data, which in conjunction with recent DL methods, aid in producing high-fidelity images in truncated times. Conventionally, subsampling the $k$-space is performed by utilizing Cartesian-rectilinear trajectories, which even with the use of DL, provide imprecise reconstructions, though, a plethora of non-rectilinear or non-Cartesian trajectories can be implemented in modern MRI scanners. This work investigates the effect of the $k$-space subsampling scheme on the quality of reconstructed accelerated MRI measurements produced by trained DL models. $\textbf{Methods:}$ The RecurrentVarNet was used as the DL-based MRI-reconstruction architecture. Cartesian fully-sampled multi-coil $k$-space measurements from three datasets with different accelerations were retrospectively subsampled using eight distinct subsampling schemes (four Cartesian-rectilinear, two Cartesian non-rectilinear, two non-Cartesian). Experiments were conducted in two frameworks: Scheme-specific, where a distinct model was trained and evaluated for each dataset-subsampling scheme pair, and multi-scheme, where for each dataset a single model was trained on data randomly subsampled by any of the eight schemes and evaluated on data subsampled by all schemes. $\textbf{Results:}$ In the scheme-specific setting RecurrentVarNets trained and evaluated on non-rectilinearly subsampled data demonstrated superior performance especially for high accelerations, whilst in the multi-scheme setting, reconstruction performance on rectilinearly subsampled data improved when compared to the scheme-specific experiments. $\textbf{Conclusion:}$ Training DL-based MRI reconstruction algorithms on non-rectilinearly subsampled measurements can produce more faithful reconstructions.
FlowNet-PET: Unsupervised Learning to Perform Respiratory Motion Correction in PET Imaging
May 27, 2022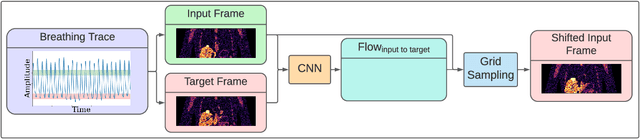
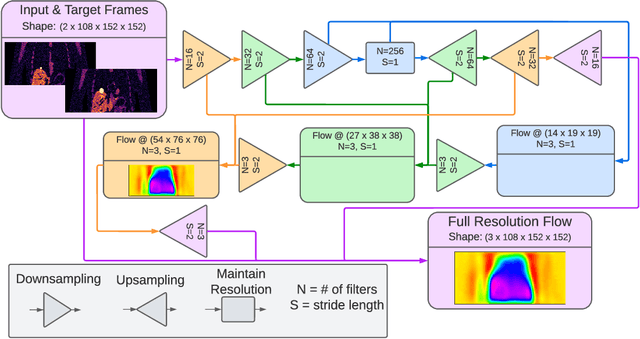
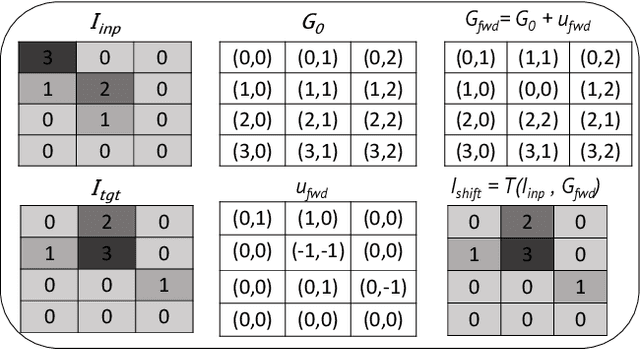
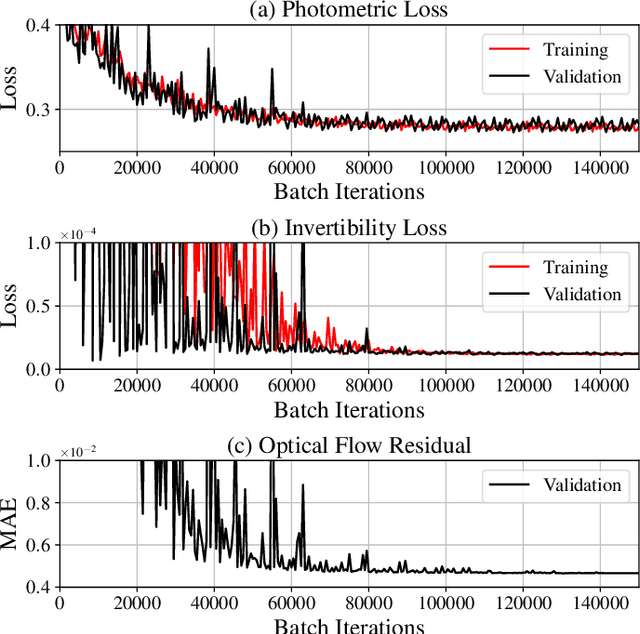
To correct for breathing motion in PET imaging, an interpretable and unsupervised deep learning technique, FlowNet-PET, was constructed. The network was trained to predict the optical flow between two PET frames from different breathing amplitude ranges. As a result, the trained model groups different retrospectively-gated PET images together into a motion-corrected single bin, providing a final image with similar counting statistics as a non-gated image, but without the blurring effects that were initially observed. As a proof-of-concept, FlowNet-PET was applied to anthropomorphic digital phantom data, which provided the possibility to design robust metrics to quantify the corrections. When comparing the predicted optical flows to the ground truths, the median absolute error was found to be smaller than the pixel and slice widths, even for the phantom with a diaphragm movement of 21 mm. The improvements were illustrated by comparing against images without motion and computing the intersection over union (IoU) of the tumors as well as the enclosed activity and coefficient of variation (CoV) within the no-motion tumor volume before and after the corrections were applied. The average relative improvements provided by the network were 54%, 90%, and 76% for the IoU, total activity, and CoV, respectively. The results were then compared against the conventional retrospective phase binning approach. FlowNet-PET achieved similar results as retrospective binning, but only required one sixth of the scan duration. The code and data used for training and analysis has been made publicly available (https://github.com/teaghan/FlowNet_PET).
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Recurrent Variational Network: A Deep Learning Inverse Problem Solver applied to the task of Accelerated MRI Reconstruction
Nov 18, 2021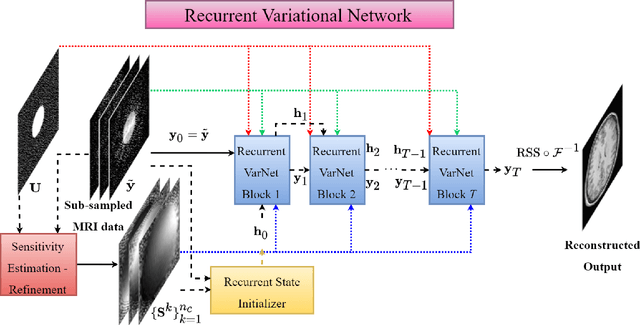
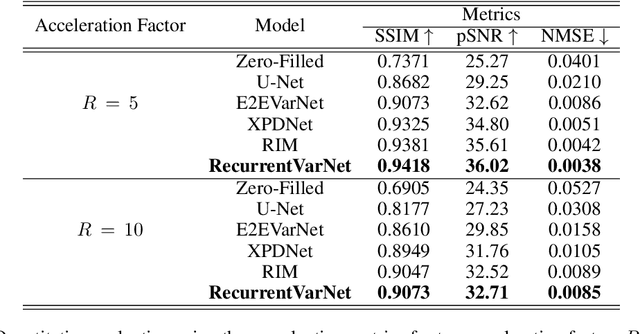
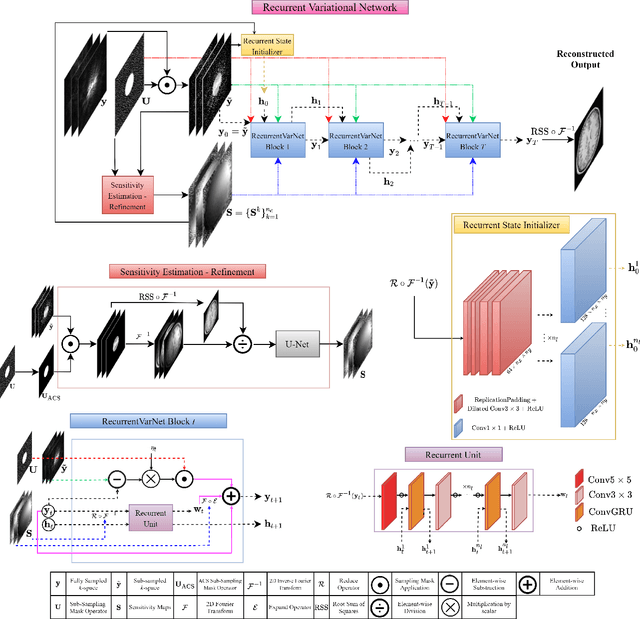

Magnetic Resonance Imaging can produce detailed images of the anatomy and physiology of the human body that can assist doctors in diagnosing and treating pathologies such as tumours. However, MRI suffers from very long acquisition times that make it susceptible to patient motion artifacts and limit its potential to deliver dynamic treatments. Conventional approaches such as Parallel Imaging and Compressed Sensing allow for an increase in MRI acquisition speed by reconstructing MR images by acquiring less MRI data using multiple receiver coils. Recent advancements in Deep Learning combined with Parallel Imaging and Compressed Sensing techniques have the potential to produce high-fidelity reconstructions from highly accelerated MRI data. In this work we present a novel Deep Learning-based Inverse Problem solver applied to the task of accelerated MRI reconstruction, called Recurrent Variational Network (RecurrentVarNet) by exploiting the properties of Convolution Recurrent Networks and unrolled algorithms for solving Inverse Problems. The RecurrentVarNet consists of multiple blocks, each responsible for one unrolled iteration of the gradient descent optimization algorithm for solving inverse problems. Contrary to traditional approaches, the optimization steps are performed in the observation domain ($k$-space) instead of the image domain. Each recurrent block of RecurrentVarNet refines the observed $k$-space and is comprised of a data consistency term and a recurrent unit which takes as input a learned hidden state and the prediction of the previous block. Our proposed method achieves new state of the art qualitative and quantitative reconstruction results on 5-fold and 10-fold accelerated data from a public multi-channel brain dataset, outperforming previous conventional and deep learning-based approaches. We will release all models code and baselines on our public repository.
Subpixel object segmentation using wavelets and multi resolution analysis
Oct 28, 2021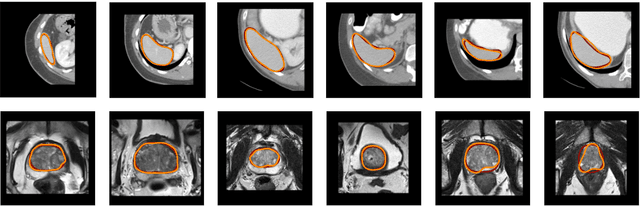
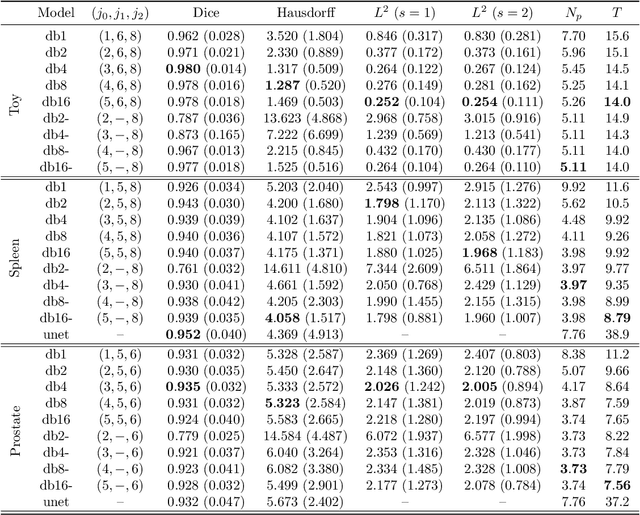
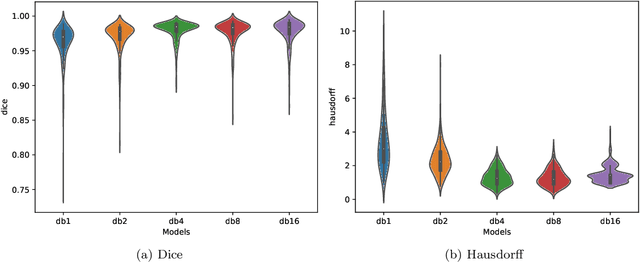

We propose a novel deep learning framework for fast prediction of boundaries of two-dimensional simply connected domains using wavelets and Multi Resolution Analysis (MRA). The boundaries are modelled as (piecewise) smooth closed curves using wavelets and the so-called Pyramid Algorithm. Our network architecture is a hybrid analog of the U-Net, where the down-sampling path is a two-dimensional encoder with learnable filters, and the upsampling path is a one-dimensional decoder, which builds curves up from low to high resolution levels. Any wavelet basis induced by a MRA can be used. This flexibility allows for incorporation of priors on the smoothness of curves. The effectiveness of the proposed method is demonstrated by delineating boundaries of simply connected domains (organs) in medical images using Debauches wavelets and comparing performance with a U-Net baseline. Our model demonstrates up to 5x faster inference speed compared to the U-Net, while maintaining similar performance in terms of Dice score and Hausdorff distance.
WeakSTIL: Weak whole-slide image level stromal tumor infiltrating lymphocyte scores are all you need
Sep 13, 2021
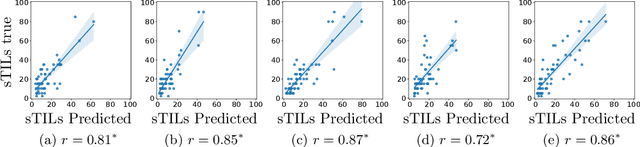
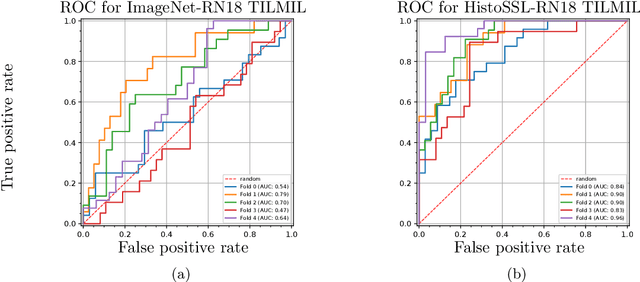
We present WeakSTIL, an interpretable two-stage weak label deep learning pipeline for scoring the percentage of stromal tumor infiltrating lymphocytes (sTIL%) in H&E-stained whole-slide images (WSIs) of breast cancer tissue. The sTIL% score is a prognostic and predictive biomarker for many solid tumor types. However, due to the high labeling efforts and high intra- and interobserver variability within and between expert annotators, this biomarker is currently not used in routine clinical decision making. WeakSTIL compresses tiles of a WSI using a feature extractor pre-trained with self-supervised learning on unlabeled histopathology data and learns to predict precise sTIL% scores for each tile in the tumor bed by using a multiple instance learning regressor that only requires a weak WSI-level label. By requiring only a weak label, we overcome the large annotation efforts required to train currently existing TIL detection methods. We show that WeakSTIL is at least as good as other TIL detection methods when predicting the WSI-level sTIL% score, reaching a coefficient of determination of $0.45\pm0.15$ when compared to scores generated by an expert pathologist, and an AUC of $0.89\pm0.05$ when treating it as the clinically interesting sTIL-high vs sTIL-low classification task. Additionally, we show that the intermediate tile-level predictions of WeakSTIL are highly interpretable, which suggests that WeakSTIL pays attention to latent features related to the number of TILs and the tissue type. In the future, WeakSTIL may be used to provide consistent and interpretable sTIL% predictions to stratify breast cancer patients into targeted therapy arms.
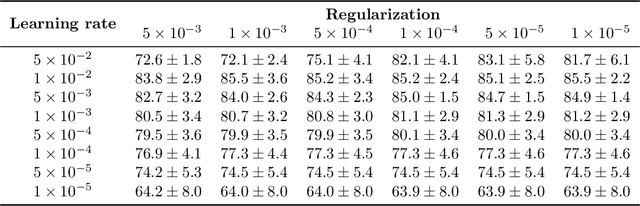
Deep MRI Reconstruction with Radial Subsampling
Aug 20, 2021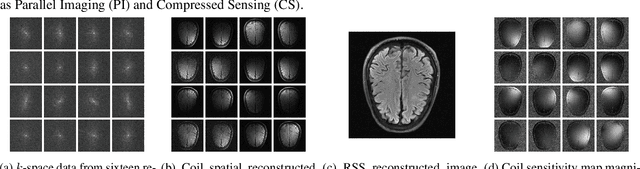
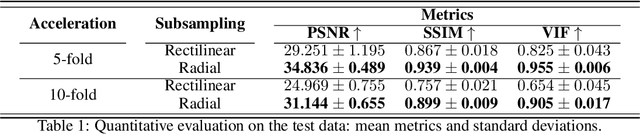
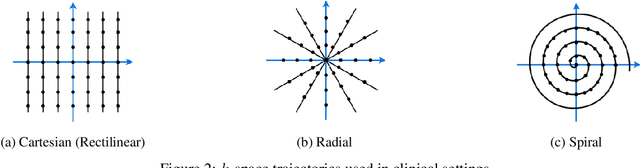

In spite of its extensive adaptation in almost every medical diagnostic and examinatorial application, Magnetic Resonance Imaging (MRI) is still a slow imaging modality which limits its use for dynamic imaging. In recent years, Parallel Imaging (PI) and Compressed Sensing (CS) have been utilised to accelerate the MRI acquisition. In clinical settings, subsampling the k-space measurements during scanning time using Cartesian trajectories, such as rectilinear sampling, is currently the most conventional CS approach applied which, however, is prone to producing aliased reconstructions. With the advent of the involvement of Deep Learning (DL) in accelerating the MRI, reconstructing faithful images from subsampled data became increasingly promising. Retrospectively applying a subsampling mask onto the k-space data is a way of simulating the accelerated acquisition of k-space data in real clinical setting. In this paper we compare and provide a review for the effect of applying either rectilinear or radial retrospective subsampling on the quality of the reconstructions outputted by trained deep neural networks. With the same choice of hyper-parameters, we train and evaluate two distinct Recurrent Inference Machines (RIMs), one for each type of subsampling. The qualitative and quantitative results of our experiments indicate that the model trained on data with radial subsampling attains higher performance and learns to estimate reconstructions with higher fidelity paving the way for other DL approaches to involve radial subsampling.
DeepSMILE: Self-supervised heterogeneity-aware multiple instance learning for DNA damage response defect classification directly from H&E whole-slide images
Jul 28, 2021
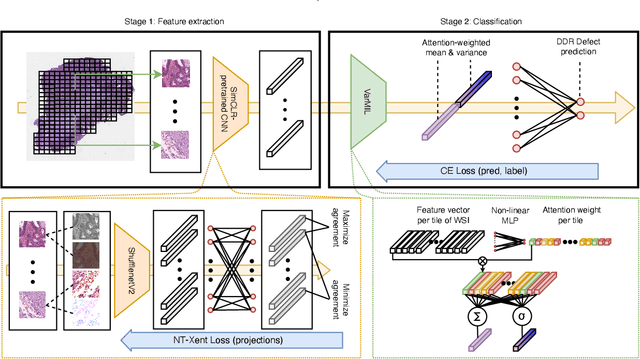
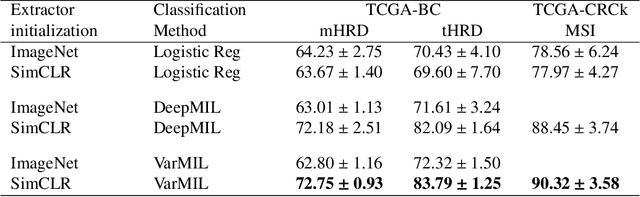
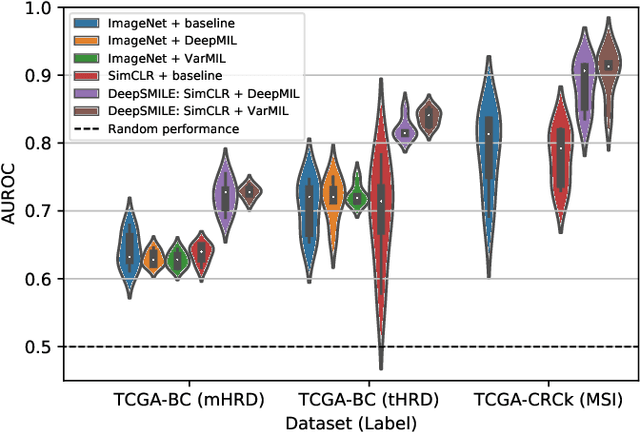
We propose a Deep learning-based weak label learning method for analysing whole slide images (WSIs) of Hematoxylin and Eosin (H&E) stained tumorcells not requiring pixel-level or tile-level annotations using Self-supervised pre-training and heterogeneity-aware deep Multiple Instance LEarning (DeepSMILE). We apply DeepSMILE to the task of Homologous recombination deficiency (HRD) and microsatellite instability (MSI) prediction. We utilize contrastive self-supervised learning to pre-train a feature extractor on histopathology tiles of cancer tissue. Additionally, we use variability-aware deep multiple instance learning to learn the tile feature aggregation function while modeling tumor heterogeneity. Compared to state-of-the-art genomic label classification methods, DeepSMILE improves classification performance for HRD from $70.43\pm4.10\%$ to $83.79\pm1.25\%$ AUC and MSI from $78.56\pm6.24\%$ to $90.32\pm3.58\%$ AUC in a multi-center breast and colorectal cancer dataset, respectively. These improvements suggest we can improve genomic label classification performance without collecting larger datasets. In the future, this may reduce the need for expensive genome sequencing techniques, provide personalized therapy recommendations based on widely available WSIs of cancer tissue, and improve patient care with quicker treatment decisions - also in medical centers without access to genome sequencing resources.