 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Rewriting as a Quality Multiplier: Evidence from Portuguese Continued Pretraining
Mar 25, 2026Synthetic data generation through document rewriting has emerged as a promising technique for improving language model pretraining, yet most studies focus on English and do not systematically control for the quality of the source data being rewritten. We present a controlled study of how synthetic rewriting interacts with source data quality in the context of Portuguese continued pretraining. Starting from ClassiCC-PT, a Portuguese corpus annotated with STEM and Educational quality scores, we construct two 10B-token subsets at different quality levels and rewrite each into four styles using a 7B instruction-tuned model, producing approximately 40B tokens of synthetic data per condition. We train two English-centric base models (1.1B and 7B parameters) on each condition and evaluate on PoETa V2, a comprehensive 44-task Portuguese benchmark. At the 7B scale, rewriting high-quality data yields a +3.4 NPM gain over the same data unmodified, while rewriting low-quality data provides only +0.5 NPM. At the 1.1B scale, this interaction is weaker, with unmodified low-quality data performing comparably to rewritten high-quality data. Our results demonstrate that synthetic rewriting acts primarily as a quality multiplier rather than a substitute for data curation, and that this effect is scale-dependent.
Curió-Edu 7B: Examining Data Selection Impacts in LLM Continued Pretraining
Dec 14, 2025Continued pretraining extends a language model's capabilities by further exposing it to additional data, often tailored to a specific linguistic or domain context. This strategy has emerged as an efficient alternative to full retraining when adapting general-purpose models to new settings. In this work, we investigate this paradigm through Curió 7B, a 7-billion-parameter model derived from LLaMA-2 and trained on 100 billion Portuguese tokens from the ClassiCC-PT corpus - the most extensive Portuguese-specific continued-pretraining effort above the three-billion-parameter scale to date. Beyond scale, we investigate whether quantity alone suffices or whether data quality plays a decisive role in linguistic adaptation. To this end, we introduce Curió-Edu 7B, a variant trained exclusively on the educational and STEM-filtered subset of the same corpus, totaling just 10 billion tokens. Despite using only 10% of the data and 20% of the computation, Curió-Edu 7B surpasses the full-corpus model in our evaluations, demonstrating that data selection can be fundamental even when adapting models with limited prior exposure to the target language. The developed models are available at https://huggingface.co/collections/ClassiCC-Corpus/curio-edu
Multi-channel MR Reconstruction (MC-MRRec) Challenge -- Comparing Accelerated MR Reconstruction Models and Assessing Their Genereralizability to Datasets Collected with Different Coils
Nov 10, 2020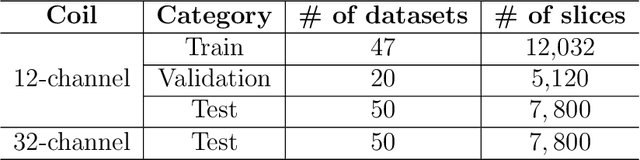
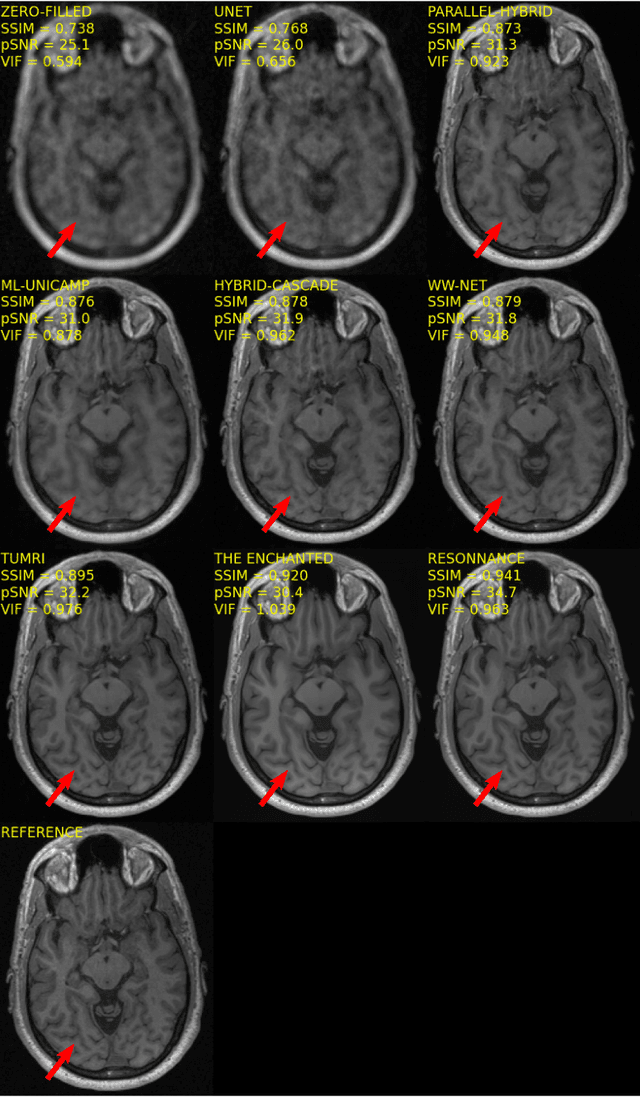
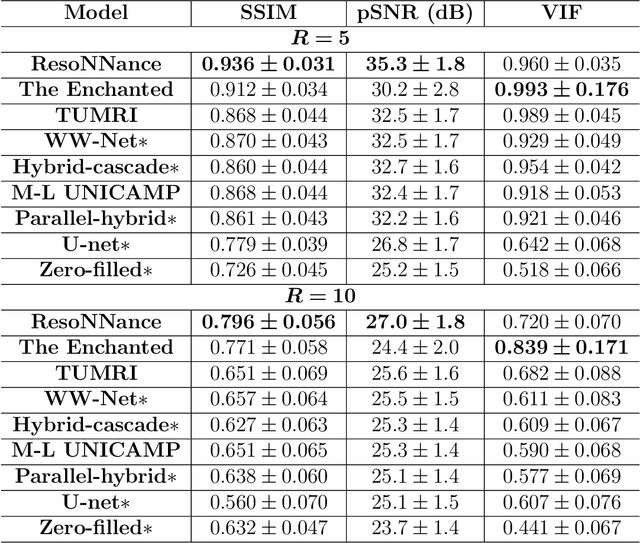
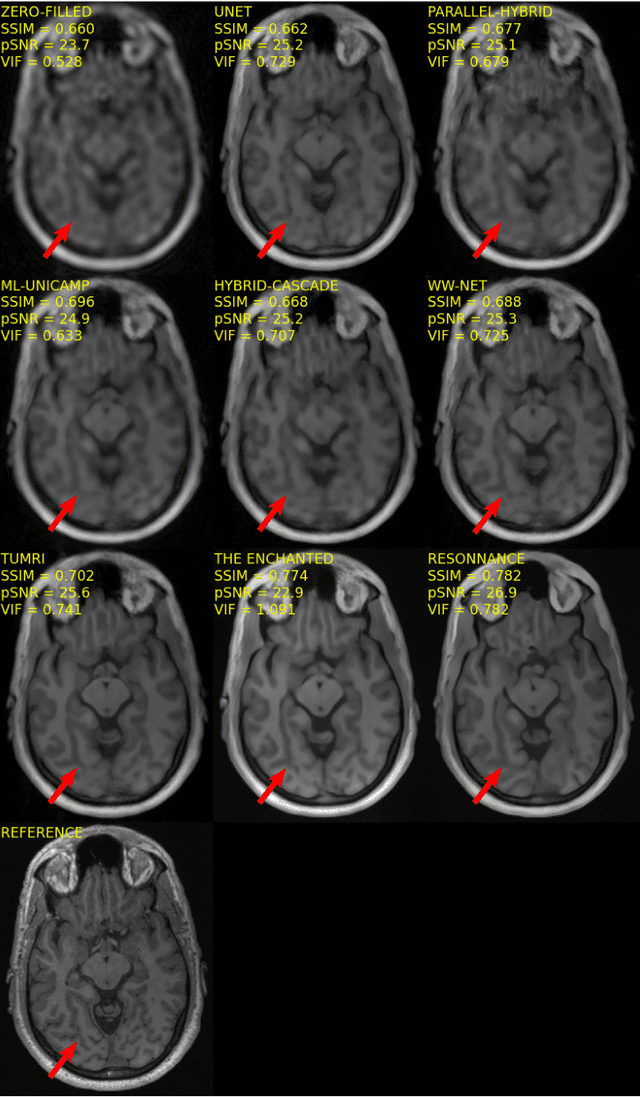
The 2020 Multi-channel Magnetic Resonance Reconstruction (MC-MRRec) Challenge had two primary goals: 1) compare different MR image reconstruction models on a large dataset and 2) assess the generalizability of these models to datasets acquired with a different number of receiver coils (i.e., multiple channels). The challenge had two tracks: Track 01 focused on assessing models trained and tested with 12-channel data. Track 02 focused on assessing models trained with 12-channel data and tested on both 12-channel and 32-channel data. While the challenge is ongoing, here we describe the first edition of the challenge and summarise submissions received prior to 5 September 2020. Track 01 had five baseline models and received four independent submissions. Track 02 had two baseline models and received two independent submissions. This manuscript provides relevant comparative information on the current state-of-the-art of MR reconstruction and highlights the challenges of obtaining generalizable models that are required prior to clinical adoption. Both challenge tracks remain open and will provide an objective performance assessment for future submissions. Subsequent editions of the challenge are proposed to investigate new concepts and strategies, such as the integration of potentially available longitudinal information during the MR reconstruction process. An outline of the proposed second edition of the challenge is presented in this manuscript.