 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textit{Versteasch du mi?} Computational and Socio-Linguistic Perspectives on GenAI, LLMs, and Non-Standard Language
Mar 30, 2026The design of Large Language Models and generative artificial intelligence has been shown to be "unfair" to less-spoken languages and to deepen the digital language divide. Critical sociolinguistic work has also argued that these technologies are not only made possible by prior socio-historical processes of linguistic standardisation, often grounded in European nationalist and colonial projects, but also exacerbate epistemologies of language as "monolithic, monolingual, syntactically standardized systems of meaning". In our paper, we draw on earlier work on the intersections of technology and language policy and bring our respective expertise in critical sociolinguistics and computational linguistics to bear on an interrogation of these arguments. We take two different complexes of non-standard linguistic varieties in our respective repertoires--South Tyrolean dialects, which are widely used in informal communication in South Tyrol, Italy, as well as varieties of Kurdish--as starting points to an interdisciplinary exploration of the intersections between GenAI and linguistic variation and standardisation. We discuss both how LLMs can be made to deal with nonstandard language from a technical perspective, and whether, when or how this can contribute to "democratic and decolonial digital and machine learning strategies", which has direct policy implications.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Polylingual Wordnet
Mar 04, 2019
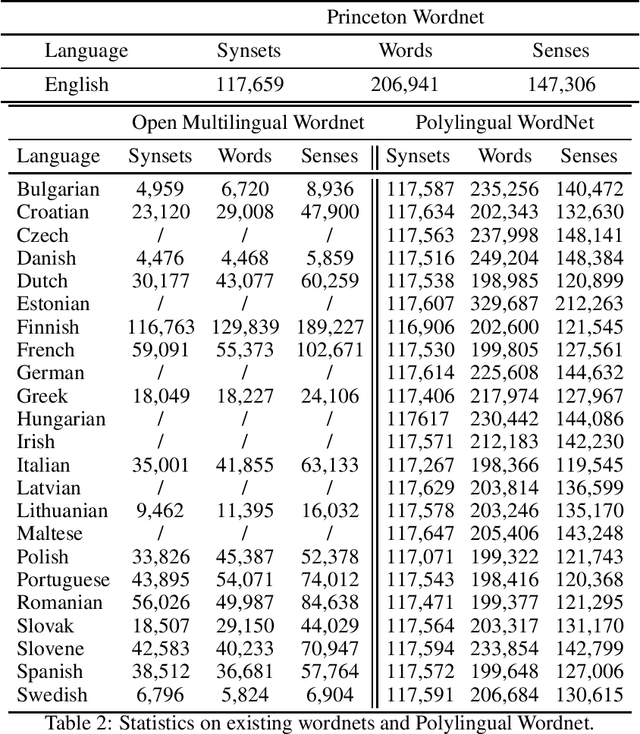
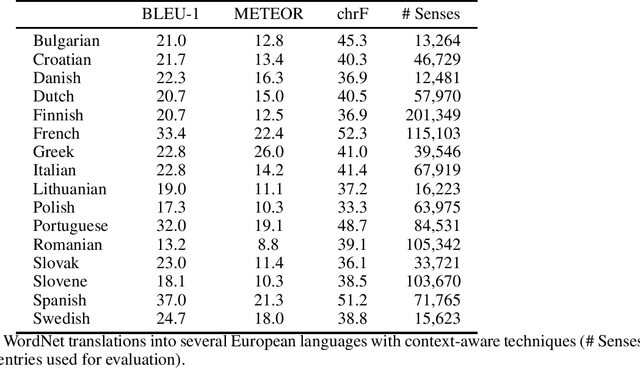
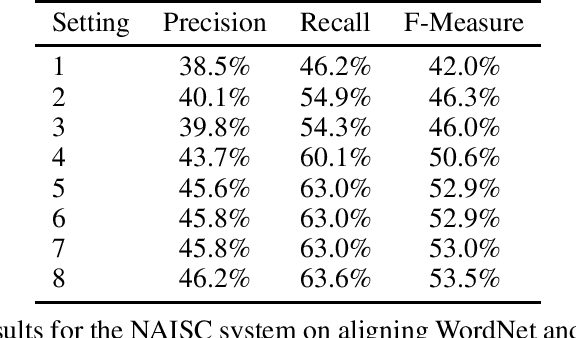
Princeton WordNet is one of the most important resources for natural language processing, but is only available for English. While it has been translated using the expand approach to many other languages, this is an expensive manual process. Therefore it would be beneficial to have a high-quality automatic translation approach that would support NLP techniques, which rely on WordNet in new languages. The translation of wordnets is fundamentally complex because of the need to translate all senses of a word including low frequency senses, which is very challenging for current machine translation approaches. For this reason we leverage existing translations of WordNet in other languages to identify contextual information for wordnet senses from a large set of generic parallel corpora. We evaluate our approach using 10 translated wordnets for European languages. Our experiment shows a significant improvement over translation without any contextual information. Furthermore, we evaluate how the choice of pivot languages affects performance of multilingual word sense disambiguation.