 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncation Sampling as Language Model Desmoothing
Oct 27, 2022Long samples of text from neural language models can be of poor quality. Truncation sampling algorithms--like top-$p$ or top-$k$ -- address this by setting some words' probabilities to zero at each step. This work provides framing for the aim of truncation, and an improved algorithm for that aim. We propose thinking of a neural language model as a mixture of a true distribution and a smoothing distribution that avoids infinite perplexity. In this light, truncation algorithms aim to perform desmoothing, estimating a subset of the support of the true distribution. Finding a good subset is crucial: we show that top-$p$ unnecessarily truncates high-probability words, for example causing it to truncate all words but Trump for a document that starts with Donald. We introduce $\eta$-sampling, which truncates words below an entropy-dependent probability threshold. Compared to previous algorithms, $\eta$-sampling generates more plausible long English documents according to humans, is better at breaking out of repetition, and behaves more reasonably on a battery of test distributions.
Conditional probing: measuring usable information beyond a baseline
Sep 19, 2021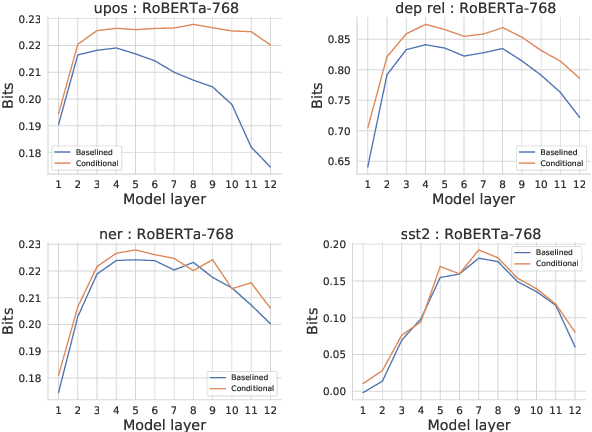
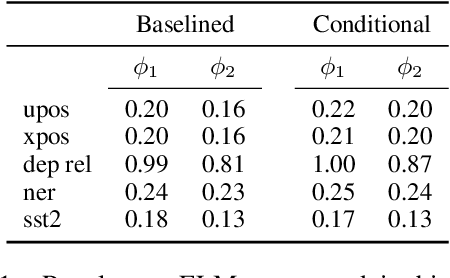
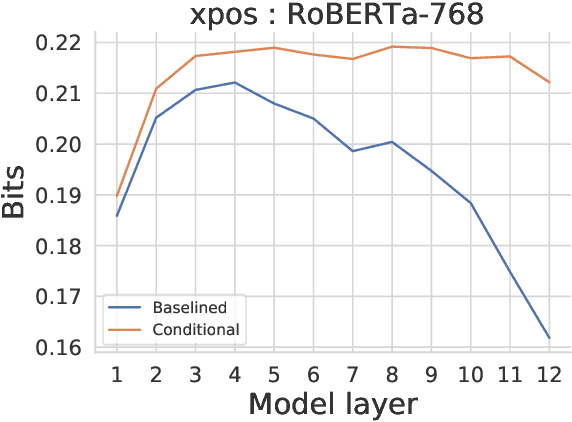
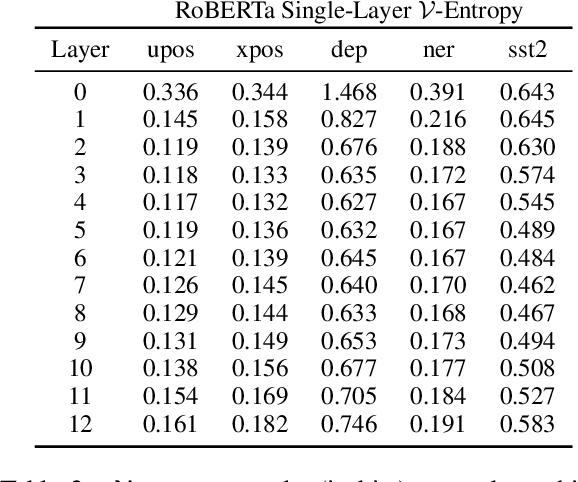
Probing experiments investigate the extent to which neural representations make properties -- like part-of-speech -- predictable. One suggests that a representation encodes a property if probing that representation produces higher accuracy than probing a baseline representation like non-contextual word embeddings. Instead of using baselines as a point of comparison, we're interested in measuring information that is contained in the representation but not in the baseline. For example, current methods can detect when a representation is more useful than the word identity (a baseline) for predicting part-of-speech; however, they cannot detect when the representation is predictive of just the aspects of part-of-speech not explainable by the word identity. In this work, we extend a theory of usable information called $\mathcal{V}$-information and propose conditional probing, which explicitly conditions on the information in the baseline. In a case study, we find that after conditioning on non-contextual word embeddings, properties like part-of-speech are accessible at deeper layers of a network than previously thought.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Refining Targeted Syntactic Evaluation of Language Models
Apr 19, 2021
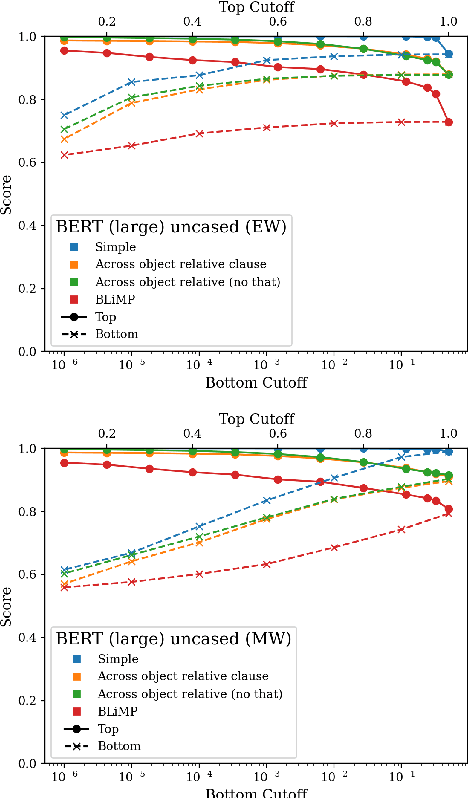
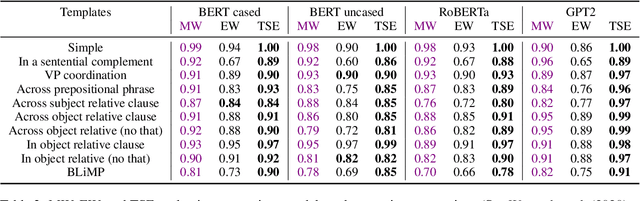
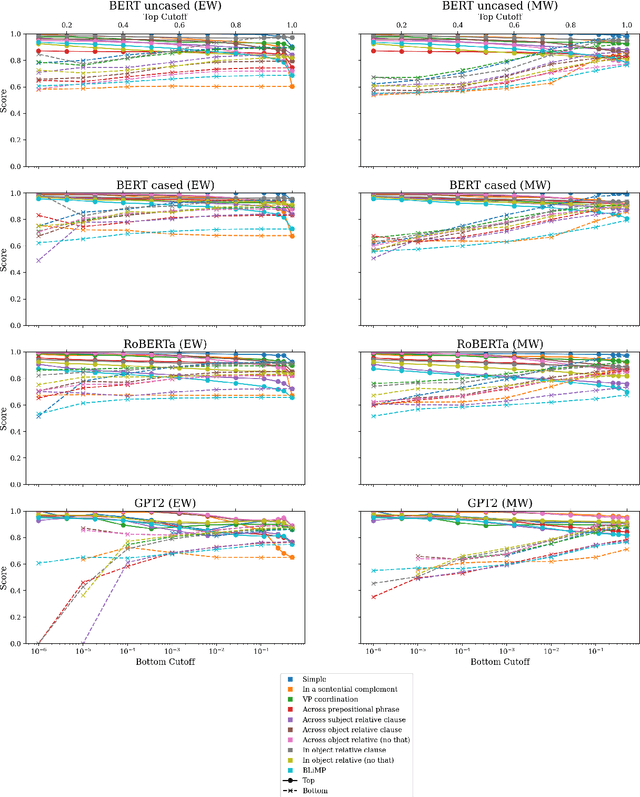
Targeted syntactic evaluation of subject-verb number agreement in English (TSE) evaluates language models' syntactic knowledge using hand-crafted minimal pairs of sentences that differ only in the main verb's conjugation. The method evaluates whether language models rate each grammatical sentence as more likely than its ungrammatical counterpart. We identify two distinct goals for TSE. First, evaluating the systematicity of a language model's syntactic knowledge: given a sentence, can it conjugate arbitrary verbs correctly? Second, evaluating a model's likely behavior: given a sentence, does the model concentrate its probability mass on correctly conjugated verbs, even if only on a subset of the possible verbs? We argue that current implementations of TSE do not directly capture either of these goals, and propose new metrics to capture each goal separately. Under our metrics, we find that TSE overestimates systematicity of language models, but that models score up to 40% better on verbs that they predict are likely in context.
Probing artificial neural networks: insights from neuroscience
Apr 16, 2021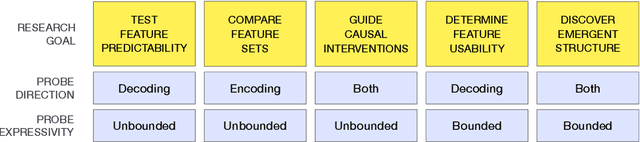
A major challenge in both neuroscience and machine learning is the development of useful tools for understanding complex information processing systems. One such tool is probes, i.e., supervised models that relate features of interest to activation patterns arising in biological or artificial neural networks. Neuroscience has paved the way in using such models through numerous studies conducted in recent decades. In this work, we draw insights from neuroscience to help guide probing research in machine learning. We highlight two important design choices for probes $-$ direction and expressivity $-$ and relate these choices to research goals. We argue that specific research goals play a paramount role when designing a probe and encourage future probing studies to be explicit in stating these goals.
RNNs can generate bounded hierarchical languages with optimal memory
Oct 15, 2020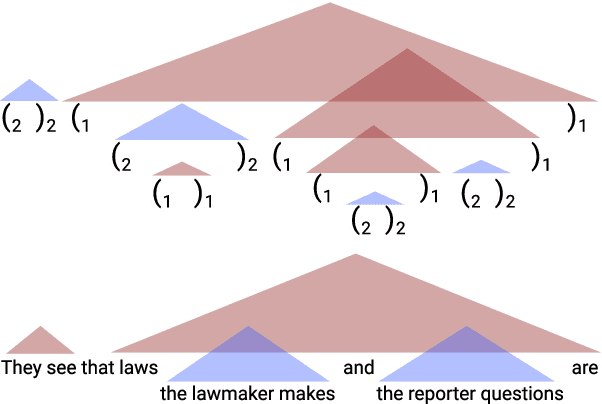
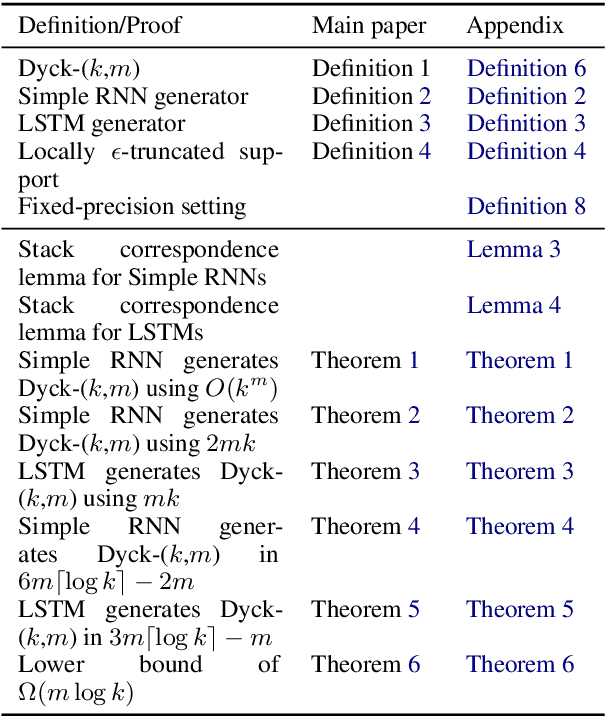
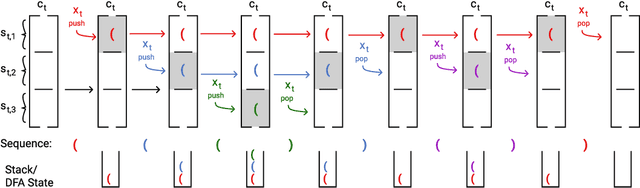
Recurrent neural networks empirically generate natural language with high syntactic fidelity. However, their success is not well-understood theoretically. We provide theoretical insight into this success, proving in a finite-precision setting that RNNs can efficiently generate bounded hierarchical languages that reflect the scaffolding of natural language syntax. We introduce Dyck-($k$,$m$), the language of well-nested brackets (of $k$ types) and $m$-bounded nesting depth, reflecting the bounded memory needs and long-distance dependencies of natural language syntax. The best known results use $O(k^{\frac{m}{2}})$ memory (hidden units) to generate these languages. We prove that an RNN with $O(m \log k)$ hidden units suffices, an exponential reduction in memory, by an explicit construction. Finally, we show that no algorithm, even with unbounded computation, can suffice with $o(m \log k)$ hidden units.
The EOS Decision and Length Extrapolation
Oct 14, 2020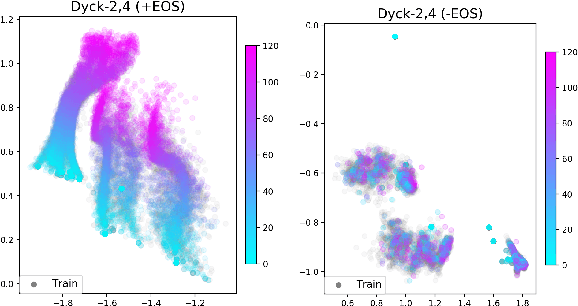

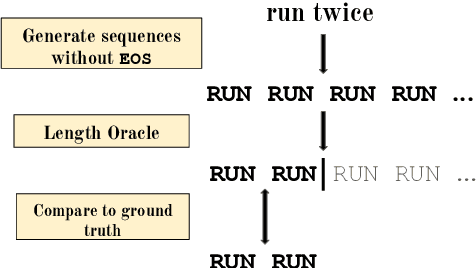

Extrapolation to unseen sequence lengths is a challenge for neural generative models of language. In this work, we characterize the effect on length extrapolation of a modeling decision often overlooked: predicting the end of the generative process through the use of a special end-of-sequence (EOS) vocabulary item. We study an oracle setting - forcing models to generate to the correct sequence length at test time - to compare the length-extrapolative behavior of networks trained to predict EOS (+EOS) with networks not trained to (-EOS). We find that -EOS substantially outperforms +EOS, for example extrapolating well to lengths 10 times longer than those seen at training time in a bracket closing task, as well as achieving a 40% improvement over +EOS in the difficult SCAN dataset length generalization task. By comparing the hidden states and dynamics of -EOS and +EOS models, we observe that +EOS models fail to generalize because they (1) unnecessarily stratify their hidden states by their linear position is a sequence (structures we call length manifolds) or (2) get stuck in clusters (which we refer to as length attractors) once the EOS token is the highest-probability prediction.
Finding Universal Grammatical Relations in Multilingual BERT
May 20, 2020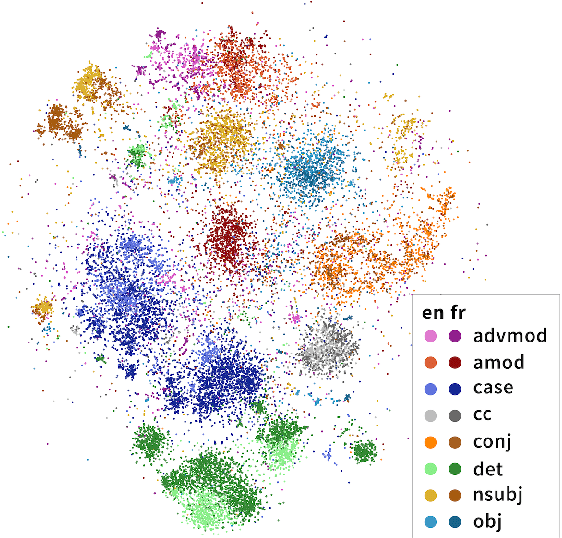
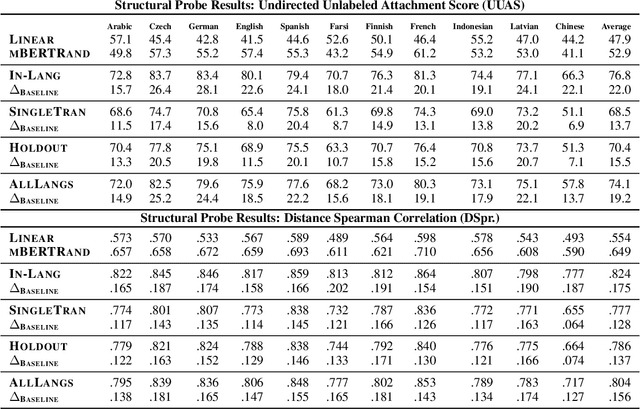
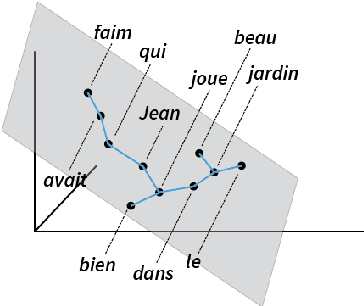
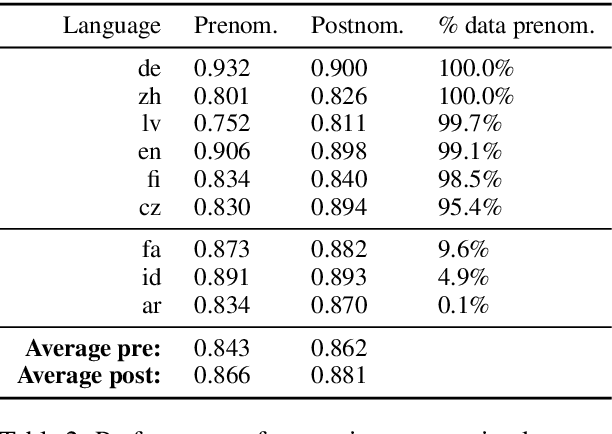
Recent work has found evidence that Multilingual BERT (mBERT), a transformer-based multilingual masked language model, is capable of zero-shot cross-lingual transfer, suggesting that some aspects of its representations are shared cross-lingually. To better understand this overlap, we extend recent work on finding syntactic trees in neural networks' internal representations to the multilingual setting. We show that subspaces of mBERT representations recover syntactic tree distances in languages other than English, and that these subspaces are approximately shared across languages. Motivated by these results, we present an unsupervised analysis method that provides evidence mBERT learns representations of syntactic dependency labels, in the form of clusters which largely agree with the Universal Dependencies taxonomy. This evidence suggests that even without explicit supervision, multilingual masked language models learn certain linguistic universals.
Designing and Interpreting Probes with Control Tasks
Sep 08, 2019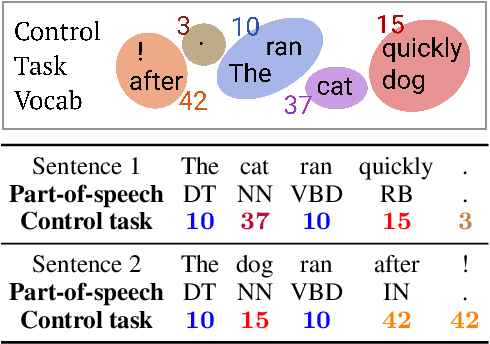
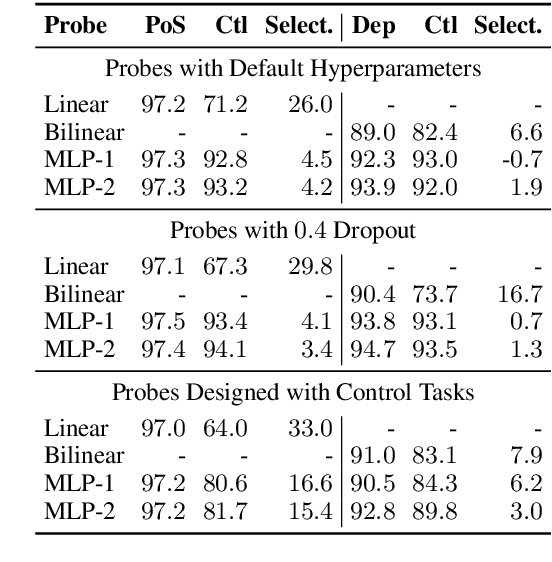
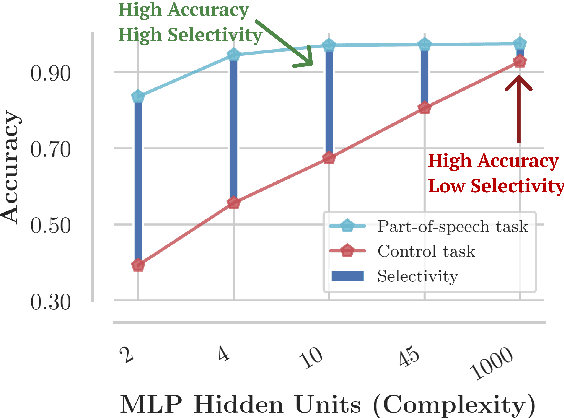
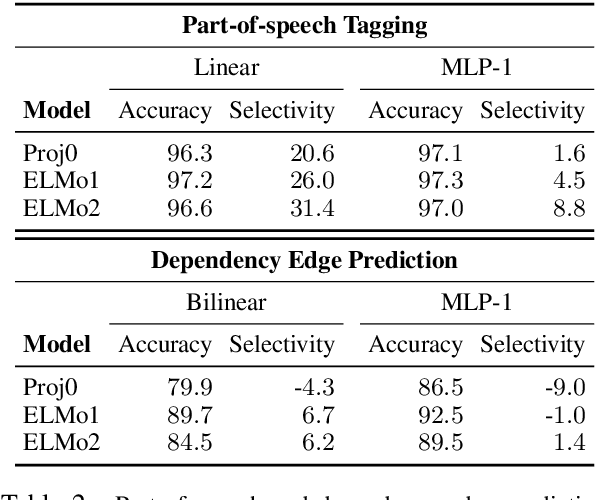
Probes, supervised models trained to predict properties (like parts-of-speech) from representations (like ELMo), have achieved high accuracy on a range of linguistic tasks. But does this mean that the representations encode linguistic structure or just that the probe has learned the linguistic task? In this paper, we propose control tasks, which associate word types with random outputs, to complement linguistic tasks. By construction, these tasks can only be learned by the probe itself. So a good probe, (one that reflects the representation), should be selective, achieving high linguistic task accuracy and low control task accuracy. The selectivity of a probe puts linguistic task accuracy in context with the probe's capacity to memorize from word types. We construct control tasks for English part-of-speech tagging and dependency edge prediction, and show that popular probes on ELMo representations are not selective. We also find that dropout, commonly used to control probe complexity, is ineffective for improving selectivity of MLPs, but that other forms of regularization are effective. Finally, we find that while probes on the first layer of ELMo yield slightly better part-of-speech tagging accuracy than the second, probes on the second layer are substantially more selective, which raises the question of which layer better represents parts-of-speech.
Simple, Fast, Accurate Intent Classification and Slot Labeling
Mar 19, 2019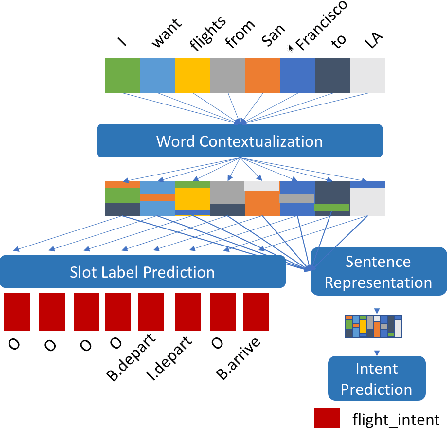
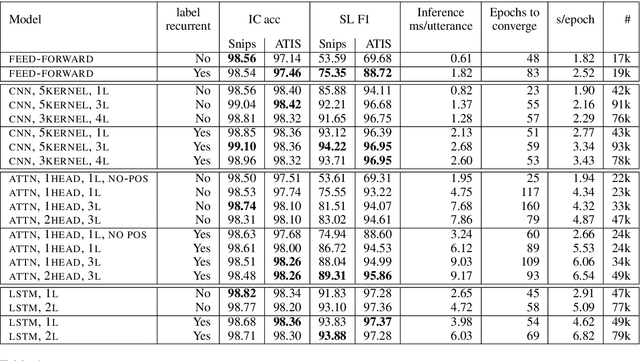
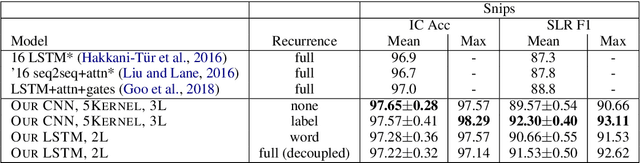

In real-time dialogue systems running at scale, there is a tradeoff between system performance, time taken for training to converge, and time taken to perform inference. In this work, we study modeling tradeoffs intent classification (IC) and slot labeling (SL), focusing on non-recurrent models. We propose a simple, modular family of neural architectures for joint IC+SL. Using this framework, we explore a number of self-attention, convolutional, and recurrent models, contributing a large-scale analysis of modeling paradigms for IC+SL across two datasets. At the same time, we discuss a class of 'label-recurrent' models, proposing that otherwise non-recurrent models with a 10-dimensional representation of the label history provide multi-point SL improvements. As a result of our analysis, we propose a class of label-recurrent, dilated, convolutional IC+SL systems that are accurate, achieving a 30% error reduction in SL over the state-of-the-art performance on the Snips dataset, as well as fast, at 2x the inference and 2/3 to 1/2 the training time of comparable recurrent models.