 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Problems in Cooperative AI
Dec 15, 2020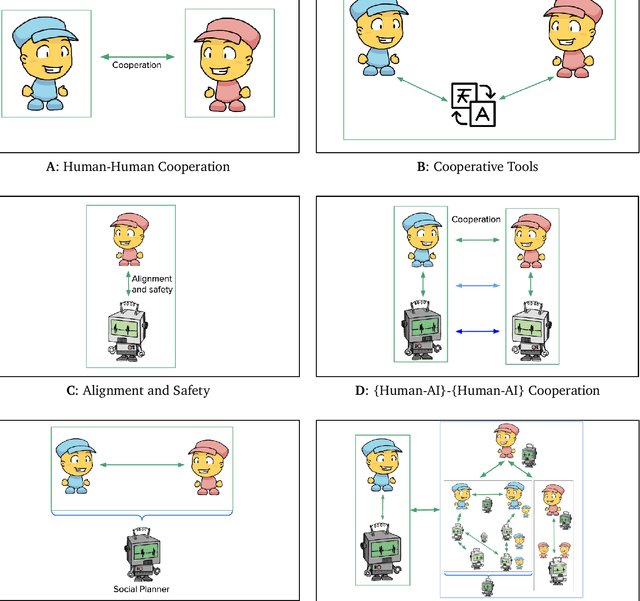

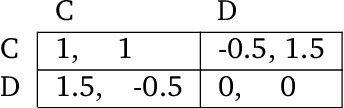
Problems of cooperation--in which agents seek ways to jointly improve their welfare--are ubiquitous and important. They can be found at scales ranging from our daily routines--such as driving on highways, scheduling meetings, and working collaboratively--to our global challenges--such as peace, commerce, and pandemic preparedness. Arguably, the success of the human species is rooted in our ability to cooperate. Since machines powered by artificial intelligence are playing an ever greater role in our lives, it will be important to equip them with the capabilities necessary to cooperate and to foster cooperation. We see an opportunity for the field of artificial intelligence to explicitly focus effort on this class of problems, which we term Cooperative AI. The objective of this research would be to study the many aspects of the problems of cooperation and to innovate in AI to contribute to solving these problems. Central goals include building machine agents with the capabilities needed for cooperation, building tools to foster cooperation in populations of (machine and/or human) agents, and otherwise conducting AI research for insight relevant to problems of cooperation. This research integrates ongoing work on multi-agent systems, game theory and social choice, human-machine interaction and alignment, natural-language processing, and the construction of social tools and platforms. However, Cooperative AI is not the union of these existing areas, but rather an independent bet about the productivity of specific kinds of conversations that involve these and other areas. We see opportunity to more explicitly focus on the problem of cooperation, to construct unified theory and vocabulary, and to build bridges with adjacent communities working on cooperation, including in the natural, social, and behavioural sciences.
DeepMind Lab2D
Dec 12, 2020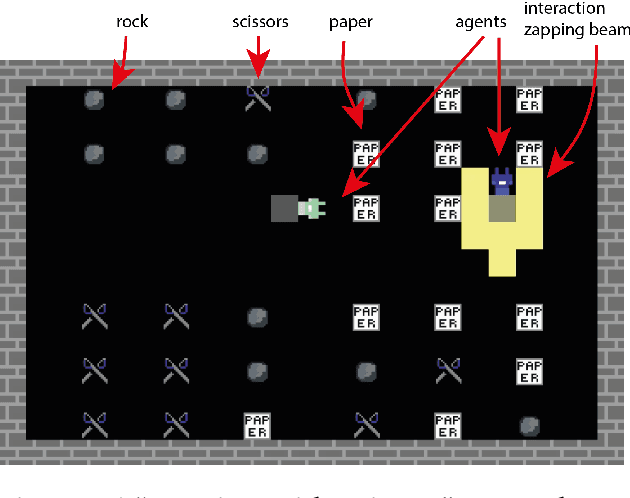
We present DeepMind Lab2D, a scalable environment simulator for artificial intelligence research that facilitates researcher-led experimentation with environment design. DeepMind Lab2D was built with the specific needs of multi-agent deep reinforcement learning researchers in mind, but it may also be useful beyond that particular subfield.
Negotiating Team Formation Using Deep Reinforcement Learning
Oct 20, 2020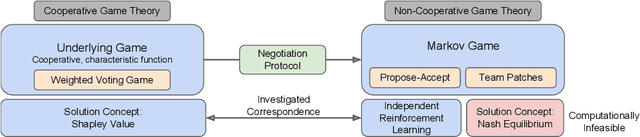
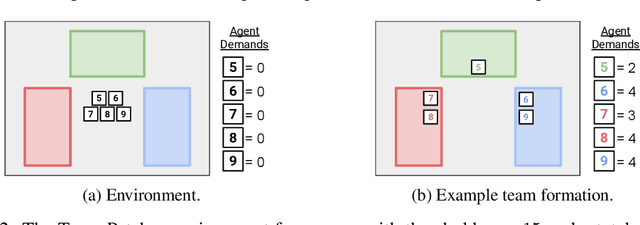
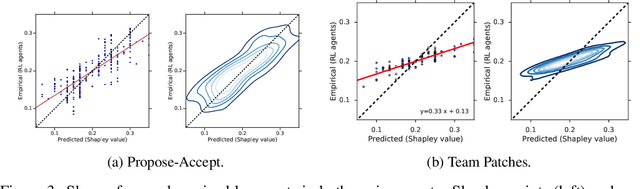
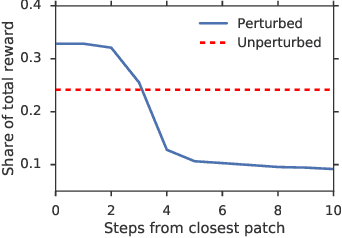
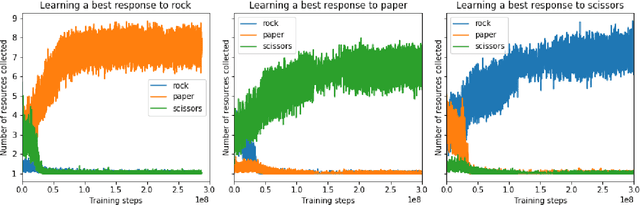
When autonomous agents interact in the same environment, they must often cooperate to achieve their goals. One way for agents to cooperate effectively is to form a team, make a binding agreement on a joint plan, and execute it. However, when agents are self-interested, the gains from team formation must be allocated appropriately to incentivize agreement. Various approaches for multi-agent negotiation have been proposed, but typically only work for particular negotiation protocols. More general methods usually require human input or domain-specific data, and so do not scale. To address this, we propose a framework for training agents to negotiate and form teams using deep reinforcement learning. Importantly, our method makes no assumptions about the specific negotiation protocol, and is instead completely experience driven. We evaluate our approach on both non-spatial and spatially extended team-formation negotiation environments, demonstrating that our agents beat hand-crafted bots and reach negotiation outcomes consistent with fair solutions predicted by cooperative game theory. Additionally, we investigate how the physical location of agents influences negotiation outcomes.
Learning to Resolve Alliance Dilemmas in Many-Player Zero-Sum Games
Feb 27, 2020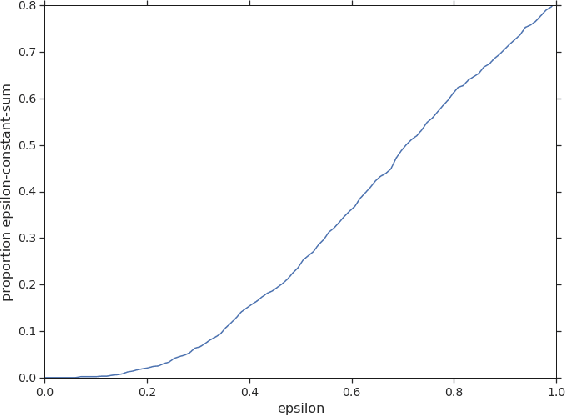
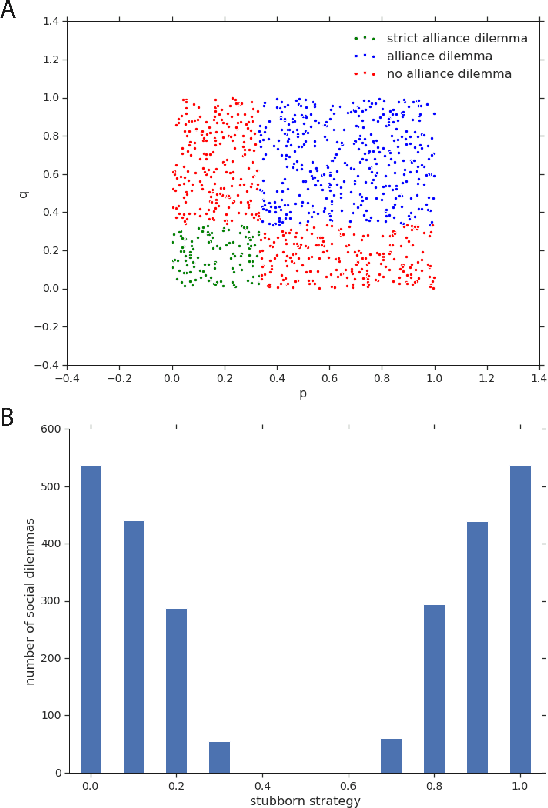
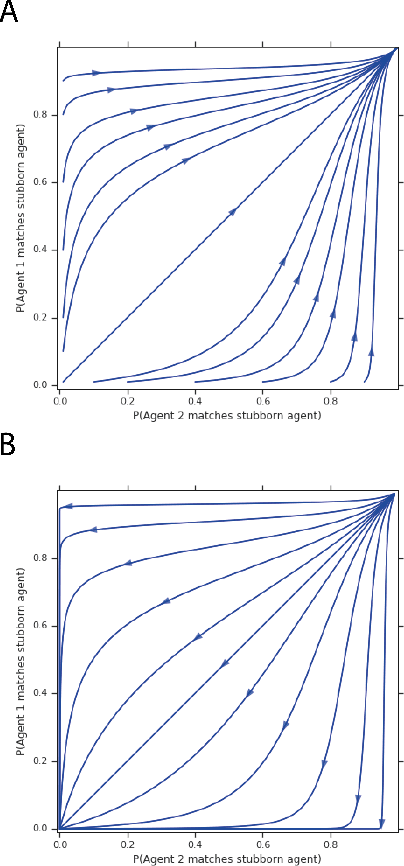
Zero-sum games have long guided artificial intelligence research, since they possess both a rich strategy space of best-responses and a clear evaluation metric. What's more, competition is a vital mechanism in many real-world multi-agent systems capable of generating intelligent innovations: Darwinian evolution, the market economy and the AlphaZero algorithm, to name a few. In two-player zero-sum games, the challenge is usually viewed as finding Nash equilibrium strategies, safeguarding against exploitation regardless of the opponent. While this captures the intricacies of chess or Go, it avoids the notion of cooperation with co-players, a hallmark of the major transitions leading from unicellular organisms to human civilization. Beyond two players, alliance formation often confers an advantage; however this requires trust, namely the promise of mutual cooperation in the face of incentives to defect. Successful play therefore requires adaptation to co-players rather than the pursuit of non-exploitability. Here we argue that a systematic study of many-player zero-sum games is a crucial element of artificial intelligence research. Using symmetric zero-sum matrix games, we demonstrate formally that alliance formation may be seen as a social dilemma, and empirically that na\"ive multi-agent reinforcement learning therefore fails to form alliances. We introduce a toy model of economic competition, and show how reinforcement learning may be augmented with a peer-to-peer contract mechanism to discover and enforce alliances. Finally, we generalize our agent model to incorporate temporally-extended contracts, presenting opportunities for further work.
Social diversity and social preferences in mixed-motive reinforcement learning
Feb 12, 2020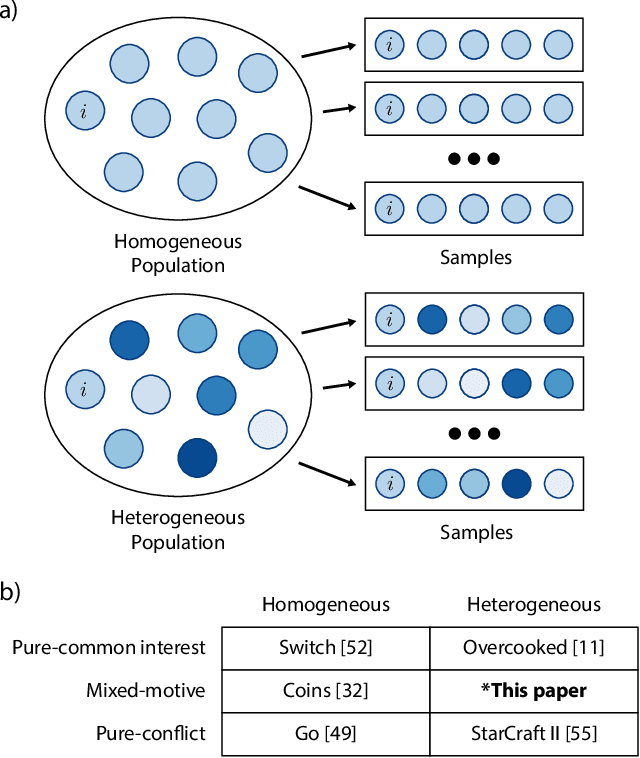
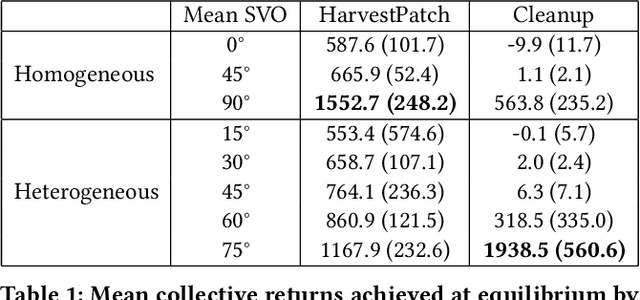
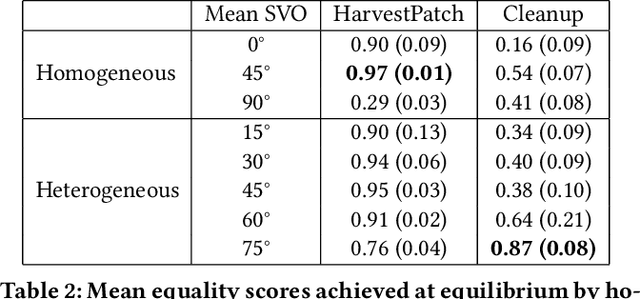
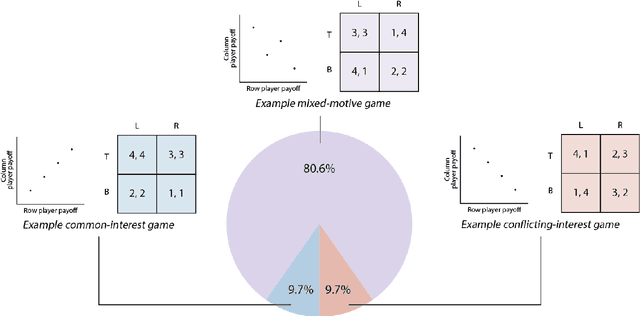
Recent research on reinforcement learning in pure-conflict and pure-common interest games has emphasized the importance of population heterogeneity. In contrast, studies of reinforcement learning in mixed-motive games have primarily leveraged homogeneous approaches. Given the defining characteristic of mixed-motive games--the imperfect correlation of incentives between group members--we study the effect of population heterogeneity on mixed-motive reinforcement learning. We draw on interdependence theory from social psychology and imbue reinforcement learning agents with Social Value Orientation (SVO), a flexible formalization of preferences over group outcome distributions. We subsequently explore the effects of diversity in SVO on populations of reinforcement learning agents in two mixed-motive Markov games. We demonstrate that heterogeneity in SVO generates meaningful and complex behavioral variation among agents similar to that suggested by interdependence theory. Empirical results in these mixed-motive dilemmas suggest agents trained in heterogeneous populations develop particularly generalized, high-performing policies relative to those trained in homogeneous populations.
Silly rules improve the capacity of agents to learn stable enforcement and compliance behaviors
Jan 25, 2020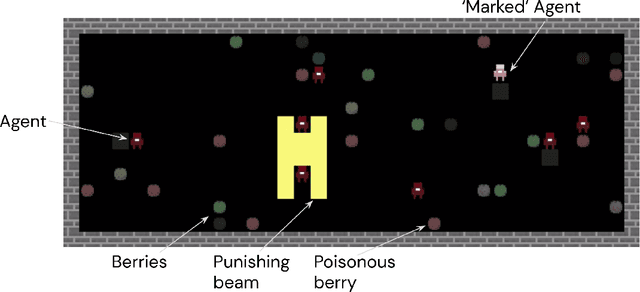
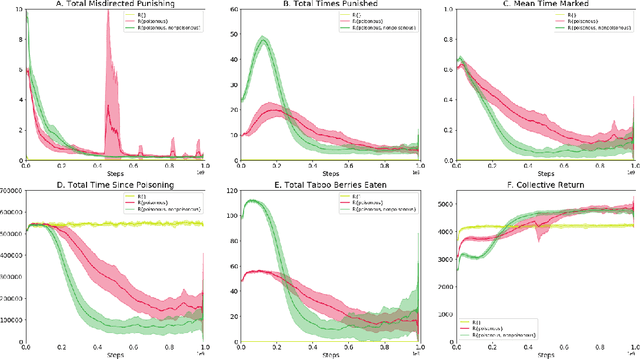
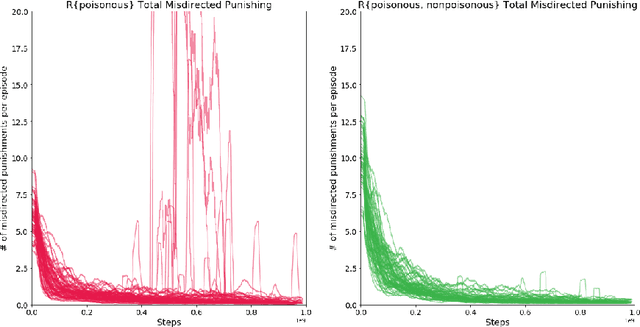

How can societies learn to enforce and comply with social norms? Here we investigate the learning dynamics and emergence of compliance and enforcement of social norms in a foraging game, implemented in a multi-agent reinforcement learning setting. In this spatiotemporally extended game, individuals are incentivized to implement complex berry-foraging policies and punish transgressions against social taboos covering specific berry types. We show that agents benefit when eating poisonous berries is taboo, meaning the behavior is punished by other agents, as this helps overcome a credit-assignment problem in discovering delayed health effects. Critically, however, we also show that introducing an additional taboo, which results in punishment for eating a harmless berry, improves the rate and stability with which agents learn to punish taboo violations and comply with taboos. Counterintuitively, our results show that an arbitrary taboo (a "silly rule") can enhance social learning dynamics and achieve better outcomes in the middle stages of learning. We discuss the results in the context of studying normativity as a group-level emergent phenomenon.
Options as responses: Grounding behavioural hierarchies in multi-agent RL
Jun 06, 2019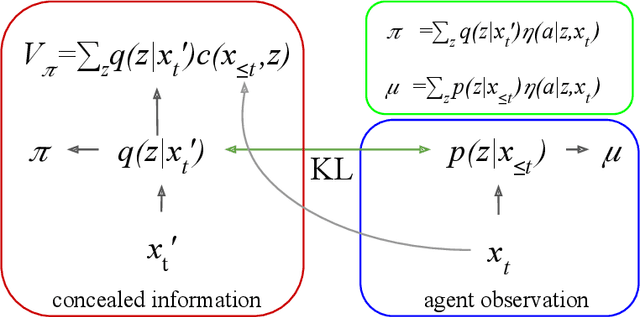
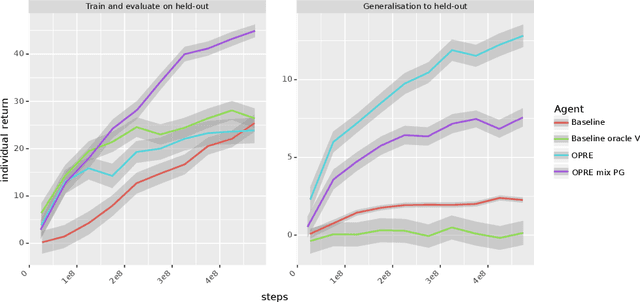
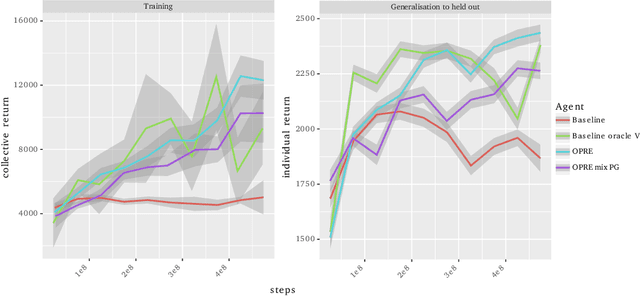
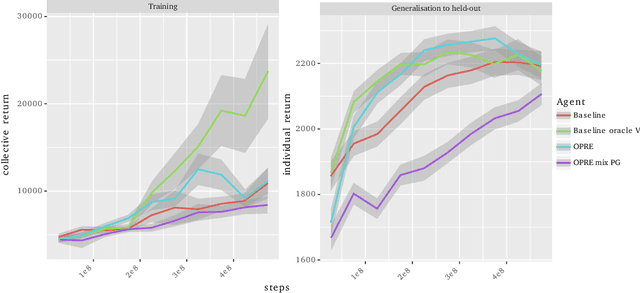
We propose a novel hierarchical agent architecture for multi-agent reinforcement learning with concealed information. The hierarchy is grounded in the concealed information about other players, which resolves "the chicken or the egg" nature of option discovery. We factorise the value function over a latent representation of the concealed information and then re-use this latent space to factorise the policy into options. Low-level policies (options) are trained to respond to particular states of other agents grouped by the latent representation, while the top level (meta-policy) learns to infer the latent representation from its own observation thereby to select the right option. This grounding facilitates credit assignment across the levels of hierarchy. We show that this helps generalisation---performance against a held-out set of pre-trained competitors, while training in self- or population-play---and resolution of social dilemmas in self-play.
Interval timing in deep reinforcement learning agents
May 31, 2019
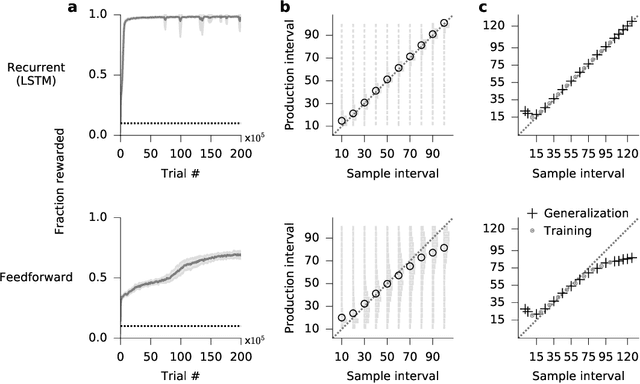
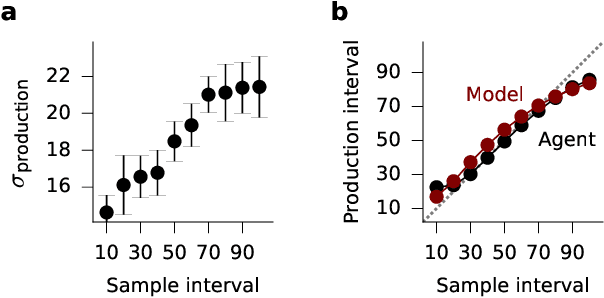
The measurement of time is central to intelligent behavior. We know that both animals and artificial agents can successfully use temporal dependencies to select actions. In artificial agents, little work has directly addressed (1) which architectural components are necessary for successful development of this ability, (2) how this timing ability comes to be represented in the units and actions of the agent, and (3) whether the resulting behavior of the system converges on solutions similar to those of biology. Here we studied interval timing abilities in deep reinforcement learning agents trained end-to-end on an interval reproduction paradigm inspired by experimental literature on mechanisms of timing. We characterize the strategies developed by recurrent and feedforward agents, which both succeed at temporal reproduction using distinct mechanisms, some of which bear specific and intriguing similarities to biological systems. These findings advance our understanding of how agents come to represent time, and they highlight the value of experimentally inspired approaches to characterizing agent abilities.
Learning Reciprocity in Complex Sequential Social Dilemmas
Mar 19, 2019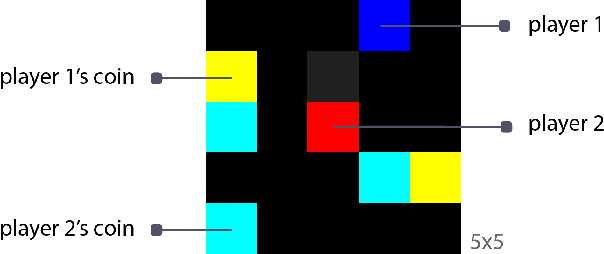
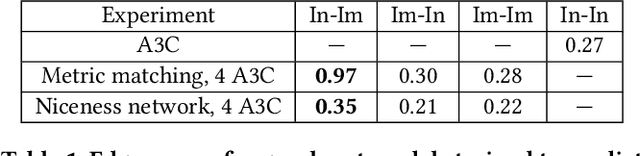
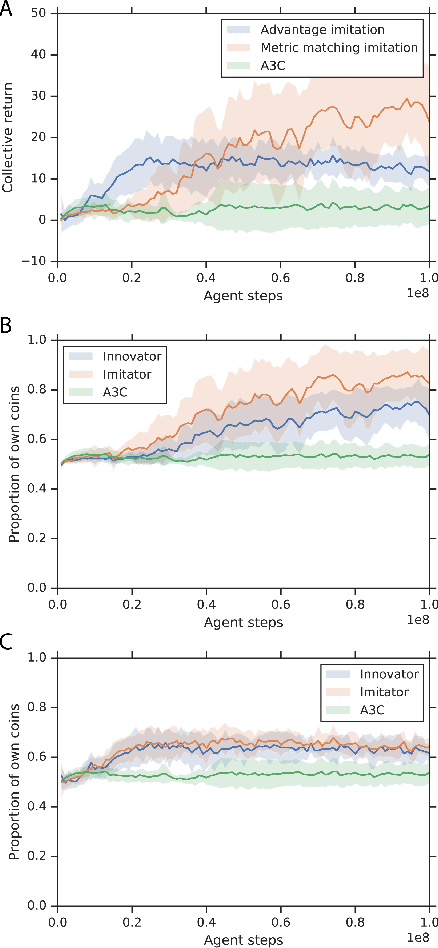
Reciprocity is an important feature of human social interaction and underpins our cooperative nature. What is more, simple forms of reciprocity have proved remarkably resilient in matrix game social dilemmas. Most famously, the tit-for-tat strategy performs very well in tournaments of Prisoner's Dilemma. Unfortunately this strategy is not readily applicable to the real world, in which options to cooperate or defect are temporally and spatially extended. Here, we present a general online reinforcement learning algorithm that displays reciprocal behavior towards its co-players. We show that it can induce pro-social outcomes for the wider group when learning alongside selfish agents, both in a $2$-player Markov game, and in $5$-player intertemporal social dilemmas. We analyse the resulting policies to show that the reciprocating agents are strongly influenced by their co-players' behavior.
Autocurricula and the Emergence of Innovation from Social Interaction: A Manifesto for Multi-Agent Intelligence Research
Mar 11, 2019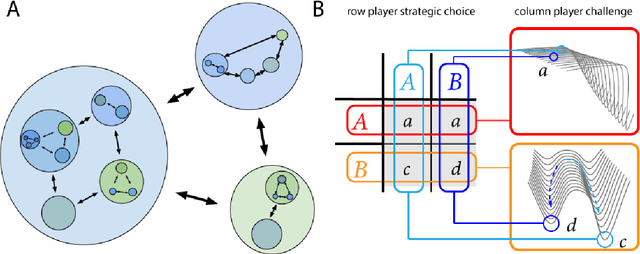
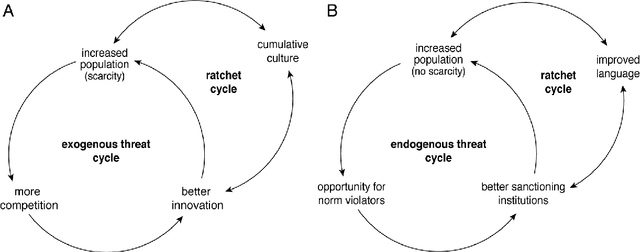
Evolution has produced a multi-scale mosaic of interacting adaptive units. Innovations arise when perturbations push parts of the system away from stable equilibria into new regimes where previously well-adapted solutions no longer work. Here we explore the hypothesis that multi-agent systems sometimes display intrinsic dynamics arising from competition and cooperation that provide a naturally emergent curriculum, which we term an autocurriculum. The solution of one social task often begets new social tasks, continually generating novel challenges, and thereby promoting innovation. Under certain conditions these challenges may become increasingly complex over time, demanding that agents accumulate ever more innovations.