 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Learned Iterative Soft Thresholding Algorithm with matrix factorization
Jun 02, 2017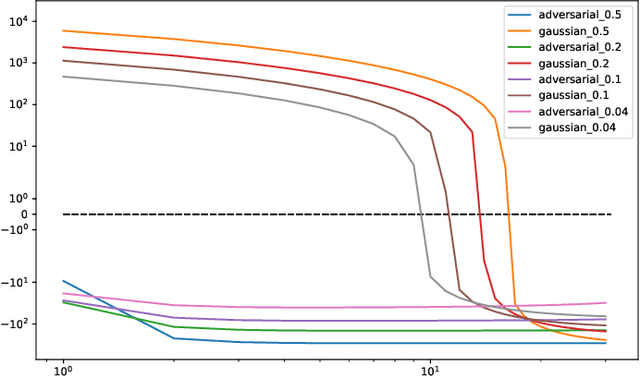

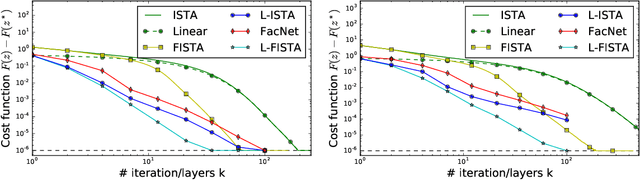
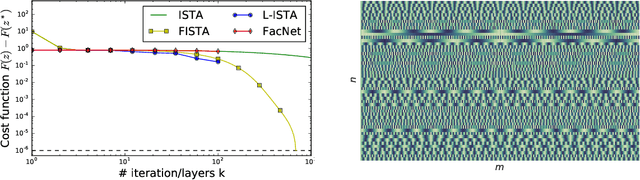
Sparse coding is a core building block in many data analysis and machine learning pipelines. Typically it is solved by relying on generic optimization techniques, such as the Iterative Soft Thresholding Algorithm and its accelerated version (ISTA, FISTA). These methods are optimal in the class of first-order methods for non-smooth, convex functions. However, they do not exploit the particular structure of the problem at hand nor the input data distribution. An acceleration using neural networks, coined LISTA, was proposed in Gregor and Le Cun (2010), which showed empirically that one could achieve high quality estimates with few iterations by modifying the parameters of the proximal splitting appropriately. In this paper we study the reasons for such acceleration. Our mathematical analysis reveals that it is related to a specific matrix factorization of the Gram kernel of the dictionary, which attempts to nearly diagonalise the kernel with a basis that produces a small perturbation of the $\ell_1$ ball. When this factorization succeeds, we prove that the resulting splitting algorithm enjoys an improved convergence bound with respect to the non-adaptive version. Moreover, our analysis also shows that conditions for acceleration occur mostly at the beginning of the iterative process, consistent with numerical experiments. We further validate our analysis by showing that on dictionaries where this factorization does not exist, adaptive acceleration fails.
Topology and Geometry of Half-Rectified Network Optimization
Jun 01, 2017
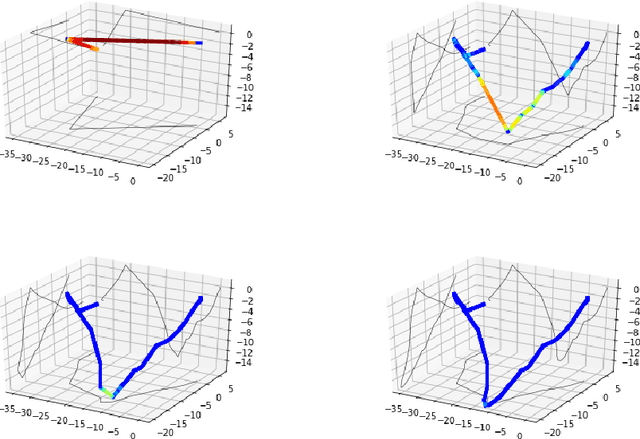
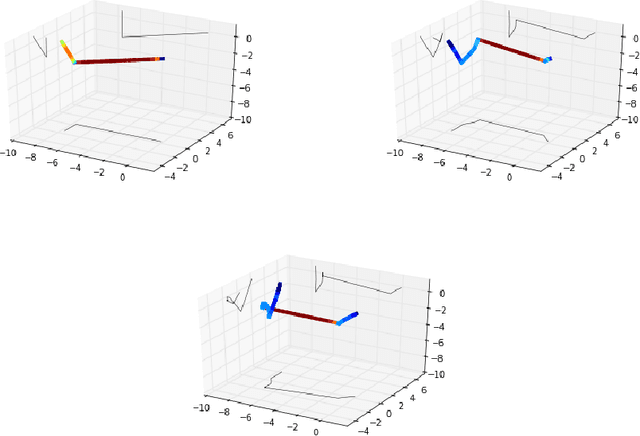
The loss surface of deep neural networks has recently attracted interest in the optimization and machine learning communities as a prime example of high-dimensional non-convex problem. Some insights were recently gained using spin glass models and mean-field approximations, but at the expense of strongly simplifying the nonlinear nature of the model. In this work, we do not make any such assumption and study conditions on the data distribution and model architecture that prevent the existence of bad local minima. Our theoretical work quantifies and formalizes two important \emph{folklore} facts: (i) the landscape of deep linear networks has a radically different topology from that of deep half-rectified ones, and (ii) that the energy landscape in the non-linear case is fundamentally controlled by the interplay between the smoothness of the data distribution and model over-parametrization. Our main theoretical contribution is to prove that half-rectified single layer networks are asymptotically connected, and we provide explicit bounds that reveal the aforementioned interplay. The conditioning of gradient descent is the next challenge we address. We study this question through the geometry of the level sets, and we introduce an algorithm to efficiently estimate the regularity of such sets on large-scale networks. Our empirical results show that these level sets remain connected throughout all the learning phase, suggesting a near convex behavior, but they become exponentially more curvy as the energy level decays, in accordance to what is observed in practice with very low curvature attractors.
Understanding Trainable Sparse Coding via Matrix Factorization
May 29, 2017
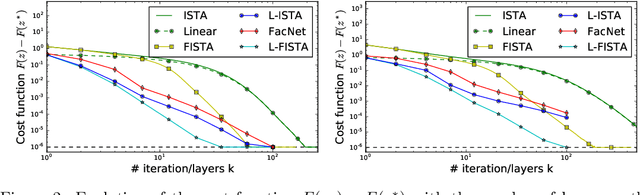
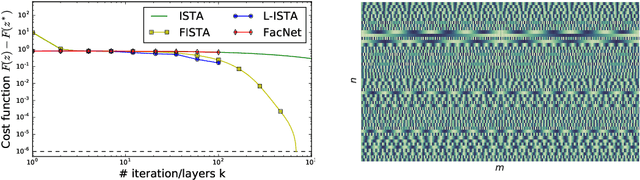
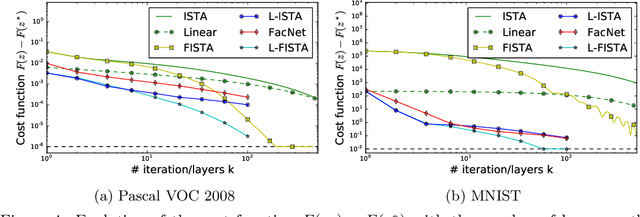
Sparse coding is a core building block in many data analysis and machine learning pipelines. Typically it is solved by relying on generic optimization techniques, that are optimal in the class of first-order methods for non-smooth, convex functions, such as the Iterative Soft Thresholding Algorithm and its accelerated version (ISTA, FISTA). However, these methods don't exploit the particular structure of the problem at hand nor the input data distribution. An acceleration using neural networks was proposed in \cite{Gregor10}, coined LISTA, which showed empirically that one could achieve high quality estimates with few iterations by modifying the parameters of the proximal splitting appropriately. In this paper we study the reasons for such acceleration. Our mathematical analysis reveals that it is related to a specific matrix factorization of the Gram kernel of the dictionary, which attempts to nearly diagonalise the kernel with a basis that produces a small perturbation of the $\ell_1$ ball. When this factorization succeeds, we prove that the resulting splitting algorithm enjoys an improved convergence bound with respect to the non-adaptive version. Moreover, our analysis also shows that conditions for acceleration occur mostly at the beginning of the iterative process, consistent with numerical experiments. We further validate our analysis by showing that on dictionaries where this factorization does not exist, adaptive acceleration fails.
Geometric deep learning: going beyond Euclidean data
May 03, 2017
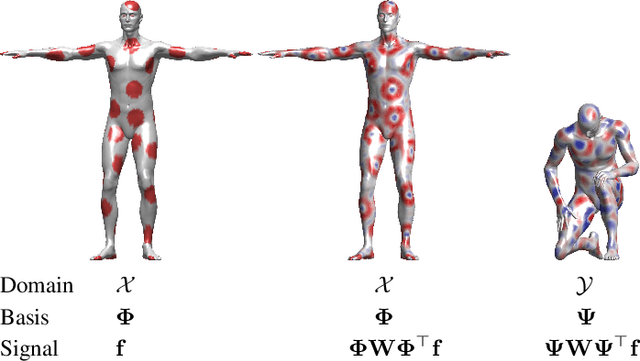
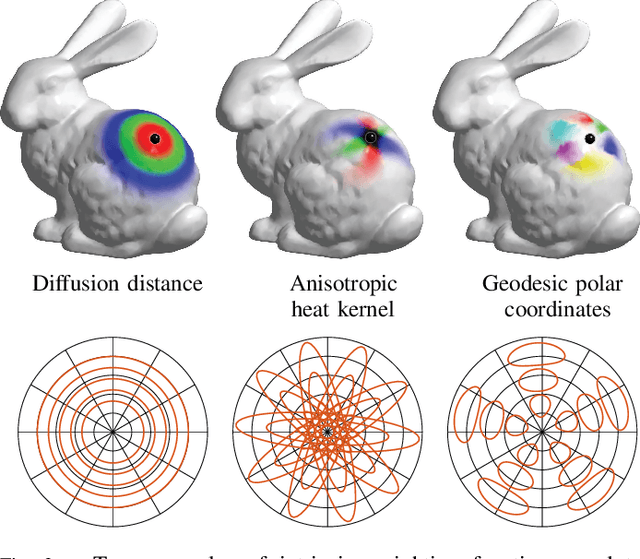
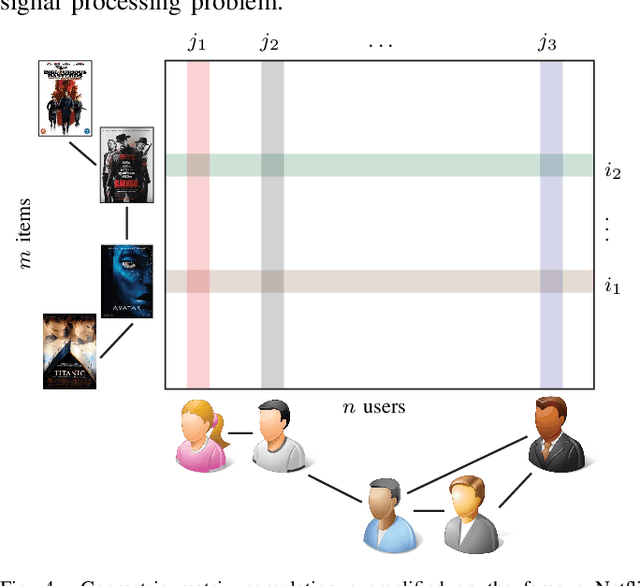
Many scientific fields study data with an underlying structure that is a non-Euclidean space. Some examples include social networks in computational social sciences, sensor networks in communications, functional networks in brain imaging, regulatory networks in genetics, and meshed surfaces in computer graphics. In many applications, such geometric data are large and complex (in the case of social networks, on the scale of billions), and are natural targets for machine learning techniques. In particular, we would like to use deep neural networks, which have recently proven to be powerful tools for a broad range of problems from computer vision, natural language processing, and audio analysis. However, these tools have been most successful on data with an underlying Euclidean or grid-like structure, and in cases where the invariances of these structures are built into networks used to model them. Geometric deep learning is an umbrella term for emerging techniques attempting to generalize (structured) deep neural models to non-Euclidean domains such as graphs and manifolds. The purpose of this paper is to overview different examples of geometric deep learning problems and present available solutions, key difficulties, applications, and future research directions in this nascent field.
Voice Conversion using Convolutional Neural Networks
Oct 27, 2016
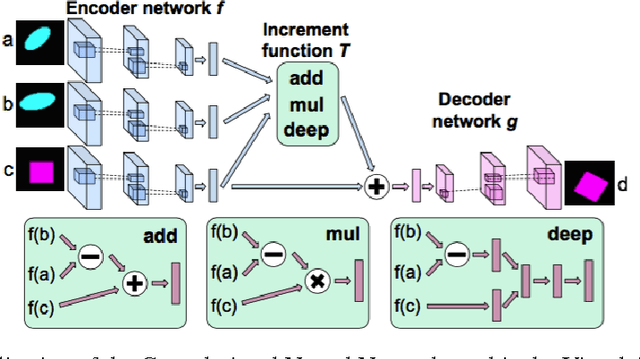
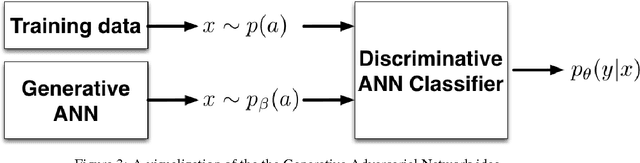
The human auditory system is able to distinguish the vocal source of thousands of speakers, yet not much is known about what features the auditory system uses to do this. Fourier Transforms are capable of capturing the pitch and harmonic structure of the speaker but this alone proves insufficient at identifying speakers uniquely. The remaining structure, often referred to as timbre, is critical to identifying speakers but we understood little about it. In this paper we use recent advances in neural networks in order to manipulate the voice of one speaker into another by transforming not only the pitch of the speaker, but the timbre. We review generative models built with neural networks as well as architectures for creating neural networks that learn analogies. Our preliminary results converting voices from one speaker to another are encouraging.
Video (language) modeling: a baseline for generative models of natural videos
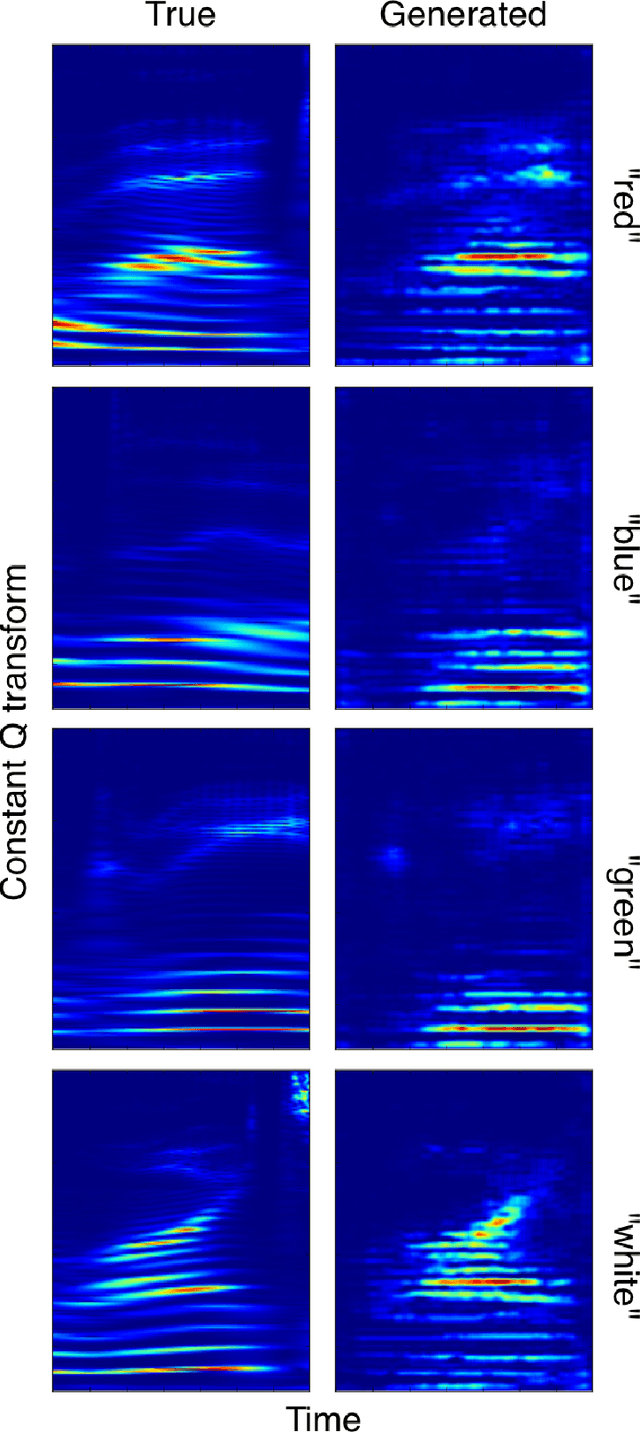
May 04, 2016



We propose a strong baseline model for unsupervised feature learning using video data. By learning to predict missing frames or extrapolate future frames from an input video sequence, the model discovers both spatial and temporal correlations which are useful to represent complex deformations and motion patterns. The models we propose are largely borrowed from the language modeling literature, and adapted to the vision domain by quantizing the space of image patches into a large dictionary. We demonstrate the approach on both a filling and a generation task. For the first time, we show that, after training on natural videos, such a model can predict non-trivial motions over short video sequences.
Super-Resolution with Deep Convolutional Sufficient Statistics
Mar 01, 2016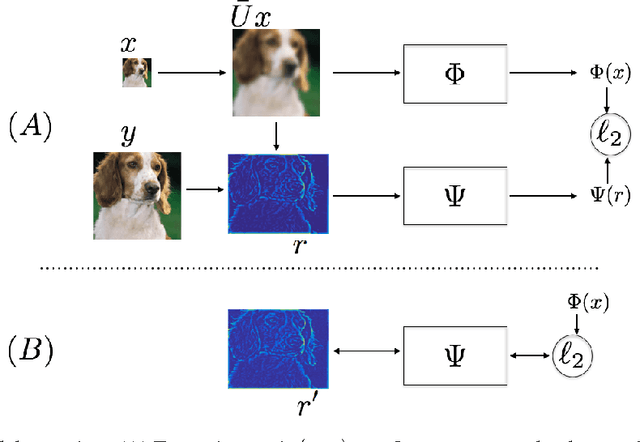

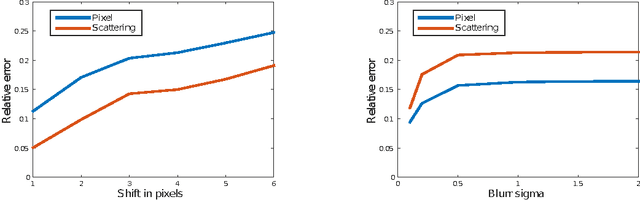

Inverse problems in image and audio, and super-resolution in particular, can be seen as high-dimensional structured prediction problems, where the goal is to characterize the conditional distribution of a high-resolution output given its low-resolution corrupted observation. When the scaling ratio is small, point estimates achieve impressive performance, but soon they suffer from the regression-to-the-mean problem, result of their inability to capture the multi-modality of this conditional distribution. Modeling high-dimensional image and audio distributions is a hard task, requiring both the ability to model complex geometrical structures and textured regions. In this paper, we propose to use as conditional model a Gibbs distribution, where its sufficient statistics are given by deep convolutional neural networks. The features computed by the network are stable to local deformation, and have reduced variance when the input is a stationary texture. These properties imply that the resulting sufficient statistics minimize the uncertainty of the target signals given the degraded observations, while being highly informative. The filters of the CNN are initialized by multiscale complex wavelets, and then we propose an algorithm to fine-tune them by estimating the gradient of the conditional log-likelihood, which bears some similarities with Generative Adversarial Networks. We evaluate experimentally the proposed approach in the image super-resolution task, but the approach is general and could be used in other challenging ill-posed problems such as audio bandwidth extension.
A mathematical motivation for complex-valued convolutional networks
Dec 12, 2015A complex-valued convolutional network (convnet) implements the repeated application of the following composition of three operations, recursively applying the composition to an input vector of nonnegative real numbers: (1) convolution with complex-valued vectors followed by (2) taking the absolute value of every entry of the resulting vectors followed by (3) local averaging. For processing real-valued random vectors, complex-valued convnets can be viewed as "data-driven multiscale windowed power spectra," "data-driven multiscale windowed absolute spectra," "data-driven multiwavelet absolute values," or (in their most general configuration) "data-driven nonlinear multiwavelet packets." Indeed, complex-valued convnets can calculate multiscale windowed spectra when the convnet filters are windowed complex-valued exponentials. Standard real-valued convnets, using rectified linear units (ReLUs), sigmoidal (for example, logistic or tanh) nonlinearities, max. pooling, etc., do not obviously exhibit the same exact correspondence with data-driven wavelets (whereas for complex-valued convnets, the correspondence is much more than just a vague analogy). Courtesy of the exact correspondence, the remarkably rich and rigorous body of mathematical analysis for wavelets applies directly to (complex-valued) convnets.
* 11 pages, 3 figures; this is the retitled version submitted to the journal, "Neural Computation"
Unsupervised Learning of Spatiotemporally Coherent Metrics
Sep 08, 2015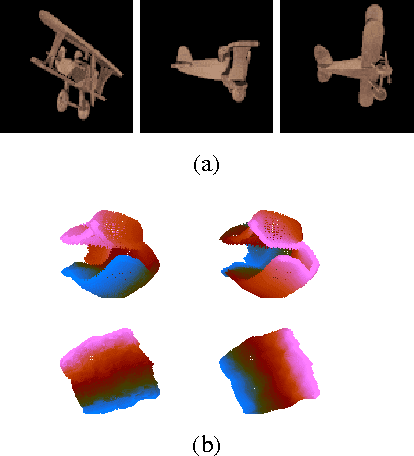

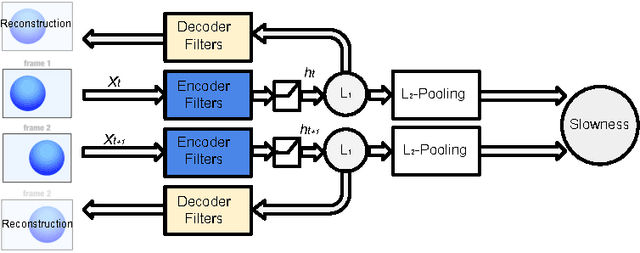
Current state-of-the-art classification and detection algorithms rely on supervised training. In this work we study unsupervised feature learning in the context of temporally coherent video data. We focus on feature learning from unlabeled video data, using the assumption that adjacent video frames contain semantically similar information. This assumption is exploited to train a convolutional pooling auto-encoder regularized by slowness and sparsity. We establish a connection between slow feature learning to metric learning and show that the trained encoder can be used to define a more temporally and semantically coherent metric.
Deep Convolutional Networks on Graph-Structured Data
Jun 16, 2015
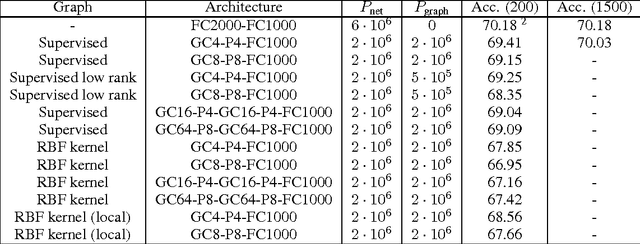
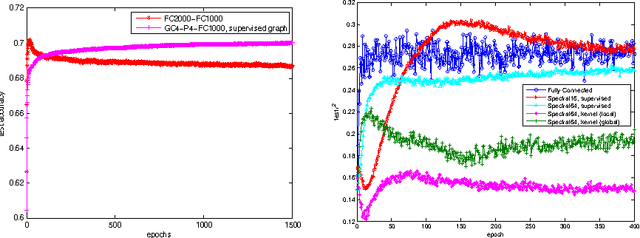

Deep Learning's recent successes have mostly relied on Convolutional Networks, which exploit fundamental statistical properties of images, sounds and video data: the local stationarity and multi-scale compositional structure, that allows expressing long range interactions in terms of shorter, localized interactions. However, there exist other important examples, such as text documents or bioinformatic data, that may lack some or all of these strong statistical regularities. In this paper we consider the general question of how to construct deep architectures with small learning complexity on general non-Euclidean domains, which are typically unknown and need to be estimated from the data. In particular, we develop an extension of Spectral Networks which incorporates a Graph Estimation procedure, that we test on large-scale classification problems, matching or improving over Dropout Networks with far less parameters to estimate.