 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditory Separation of a Conversation from Background via Attentional Gating
May 26, 2019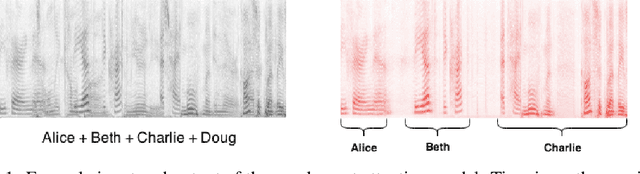
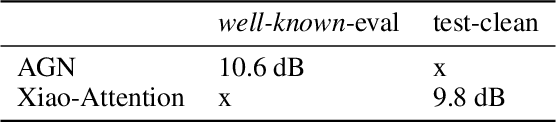
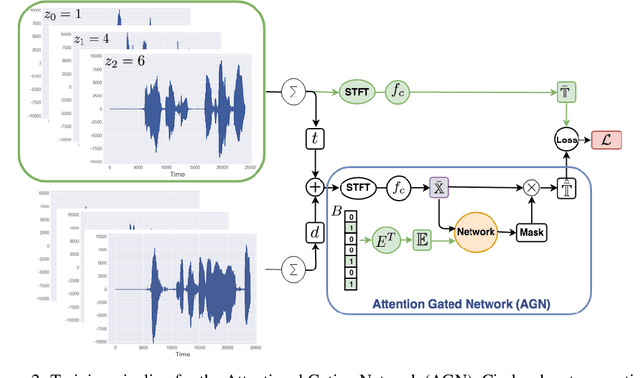
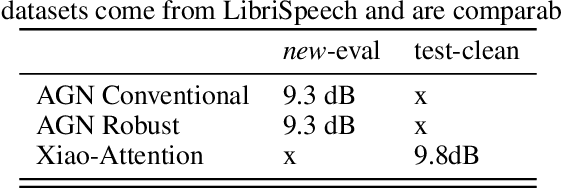
We present a model for separating a set of voices out of a sound mixture containing an unknown number of sources. Our Attentional Gating Network (AGN) uses a variable attentional context to specify which speakers in the mixture are of interest. The attentional context is specified by an embedding vector which modifies the processing of a neural network through an additive bias. Individual speaker embeddings are learned to separate a single speaker while superpositions of the individual speaker embeddings are used to separate sets of speakers. We first evaluate AGN on a traditional single speaker separation task and show an improvement of 9% with respect to comparable models. Then, we introduce a new task to separate an arbitrary subset of voices from a mixture of an unknown-sized set of voices, inspired by the human ability to separate a conversation of interest from background chatter at a cafeteria. We show that AGN is the only model capable of solving this task, performing only 7% worse than on the single speaker separation task.
Generalization Challenges for Neural Architectures in Audio Source Separation
May 27, 2018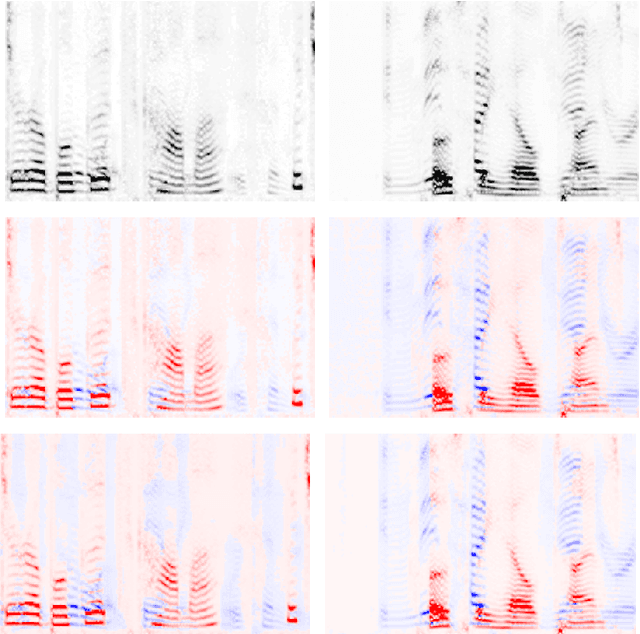

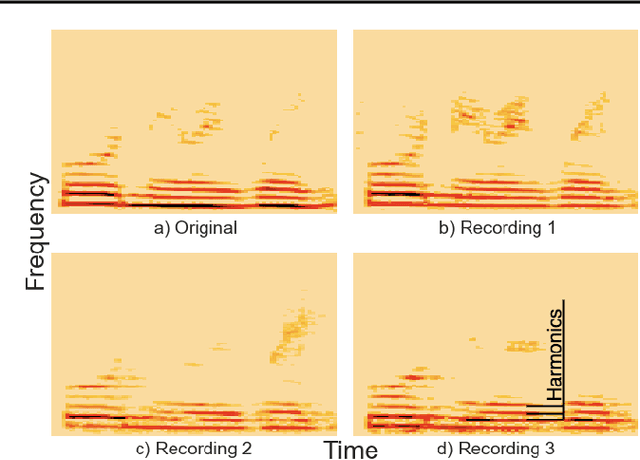
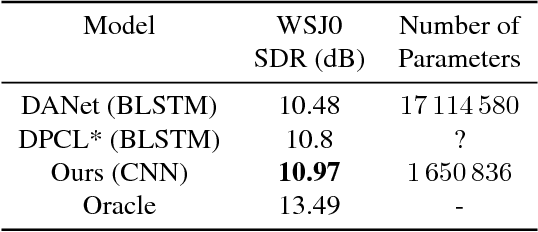
Recent work has shown that recurrent neural networks can be trained to separate individual speakers in a sound mixture with high fidelity. Here we explore convolutional neural network models as an alternative and show that they achieve state-of-the-art results with an order of magnitude fewer parameters. We also characterize and compare the robustness and ability of these different approaches to generalize under three different test conditions: longer time sequences, the addition of intermittent noise, and different datasets not seen during training. For the last condition, we create a new dataset, RealTalkLibri, to test source separation in real-world environments. We show that the acoustics of the environment have significant impact on the structure of the waveform and the overall performance of neural network models, with the convolutional model showing superior ability to generalize to new environments. The code for our study is available at https://github.com/ShariqM/source_separation.
Voice Conversion using Convolutional Neural Networks
Oct 27, 2016
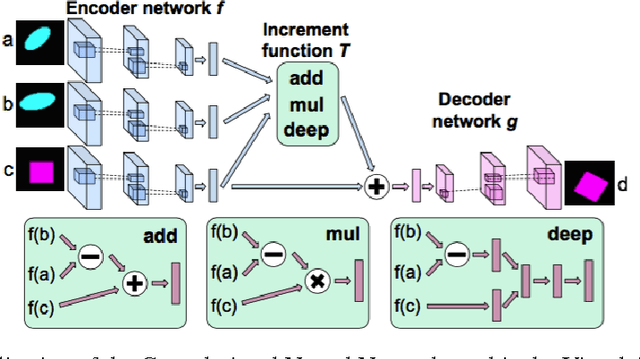
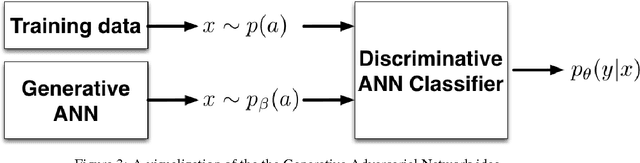
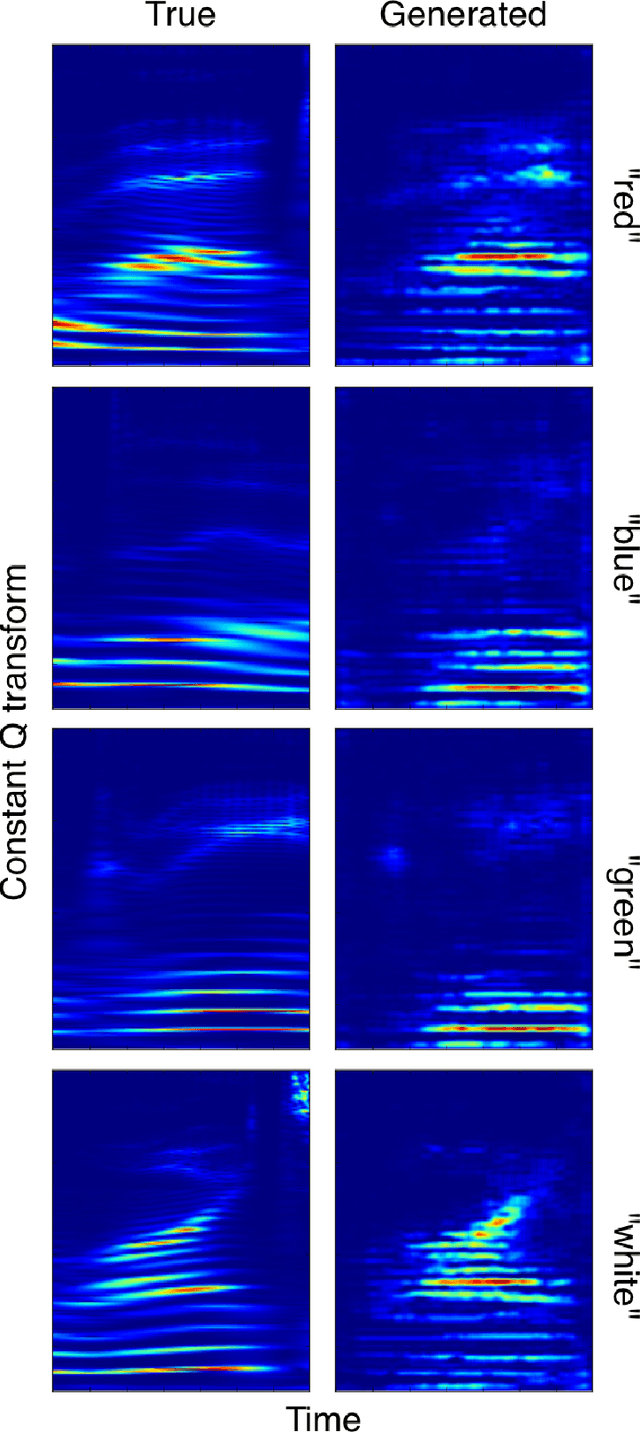
The human auditory system is able to distinguish the vocal source of thousands of speakers, yet not much is known about what features the auditory system uses to do this. Fourier Transforms are capable of capturing the pitch and harmonic structure of the speaker but this alone proves insufficient at identifying speakers uniquely. The remaining structure, often referred to as timbre, is critical to identifying speakers but we understood little about it. In this paper we use recent advances in neural networks in order to manipulate the voice of one speaker into another by transforming not only the pitch of the speaker, but the timbre. We review generative models built with neural networks as well as architectures for creating neural networks that learn analogies. Our preliminary results converting voices from one speaker to another are encouraging.