 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSynth: Automated Workflow Optimization for High-Quality Synthetic Dataset Generation via Monte Carlo Tree Search
Nov 12, 2025



Supervised fine-tuning (SFT) of large language models (LLMs) for specialized tasks requires high-quality datasets, but manual curation is prohibitively expensive. Synthetic data generation offers scalability, but its effectiveness relies on complex, multi-stage workflows, integrating prompt engineering and model orchestration. Existing automated workflow methods face a cold start problem: they require labeled datasets for reward modeling, which is especially problematic for subjective, open-ended tasks with no objective ground truth. We introduce AutoSynth, a framework that automates workflow discovery and optimization without reference datasets by reframing the problem as a Monte Carlo Tree Search guided by a novel dataset-free hybrid reward. This reward enables meta-learning through two LLM-as-judge components: one evaluates sample quality using dynamically generated task-specific metrics, and another assesses workflow code and prompt quality. Experiments on subjective educational tasks show that while expert-designed workflows achieve higher human preference rates (96-99% win rates vs. AutoSynth's 40-51%), models trained on AutoSynth-generated data dramatically outperform baselines (40-51% vs. 2-5%) and match or surpass expert workflows on certain metrics, suggesting discovery of quality dimensions beyond human intuition. These results are achieved while reducing human effort from 5-7 hours to just 30 minutes (>90% reduction). AutoSynth tackles the cold start issue in data-centric AI, offering a scalable, cost-effective method for subjective LLM tasks. Code: https://github.com/bisz9918-maker/AutoSynth.
Cultivating Helpful, Personalized, and Creative AI Tutors: A Framework for Pedagogical Alignment using Reinforcement Learning
Jul 27, 2025



The integration of large language models (LLMs) into education presents unprecedented opportunities for scalable personalized learning. However, standard LLMs often function as generic information providers, lacking alignment with fundamental pedagogical principles such as helpfulness, student-centered personalization, and creativity cultivation. To bridge this gap, we propose EduAlign, a novel framework designed to guide LLMs toward becoming more effective and responsible educational assistants. EduAlign consists of two main stages. In the first stage, we curate a dataset of 8k educational interactions and annotate them-both manually and automatically-along three key educational dimensions: Helpfulness, Personalization, and Creativity (HPC). These annotations are used to train HPC-RM, a multi-dimensional reward model capable of accurately scoring LLM outputs according to these educational principles. We further evaluate the consistency and reliability of this reward model. In the second stage, we leverage HPC-RM as a reward signal to fine-tune a pre-trained LLM using Group Relative Policy Optimization (GRPO) on a set of 2k diverse prompts. We then assess the pre- and post-finetuning models on both educational and general-domain benchmarks across the three HPC dimensions. Experimental results demonstrate that the fine-tuned model exhibits significantly improved alignment with pedagogical helpfulness, personalization, and creativity stimulation. This study presents a scalable and effective approach to aligning LLMs with nuanced and desirable educational traits, paving the way for the development of more engaging, pedagogically aligned AI tutors.
TopicVD: A Topic-Based Dataset of Video-Guided Multimodal Machine Translation for Documentaries
May 09, 2025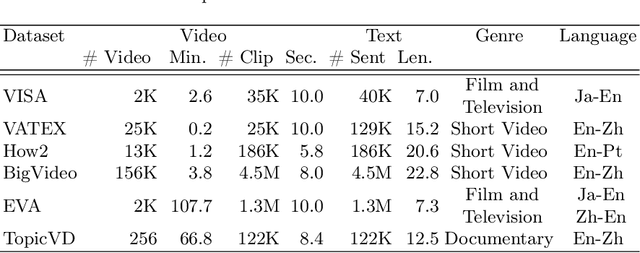
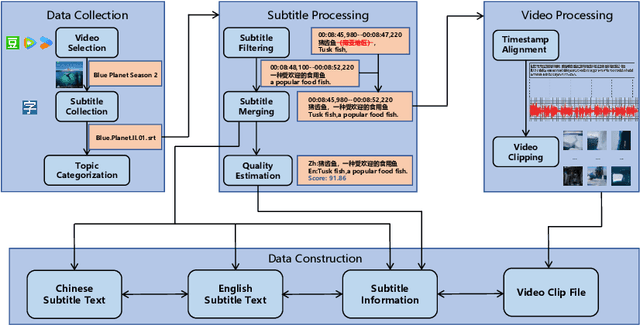
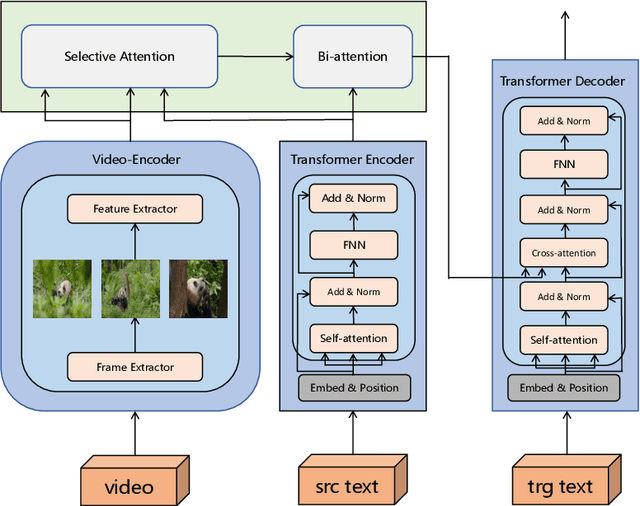
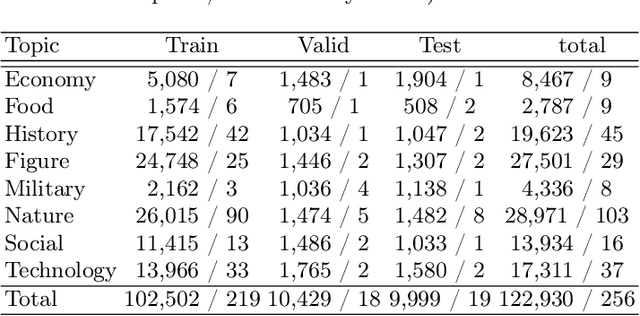
Most existing multimodal machine translation (MMT) datasets are predominantly composed of static images or short video clips, lacking extensive video data across diverse domains and topics. As a result, they fail to meet the demands of real-world MMT tasks, such as documentary translation. In this study, we developed TopicVD, a topic-based dataset for video-supported multimodal machine translation of documentaries, aiming to advance research in this field. We collected video-subtitle pairs from documentaries and categorized them into eight topics, such as economy and nature, to facilitate research on domain adaptation in video-guided MMT. Additionally, we preserved their contextual information to support research on leveraging the global context of documentaries in video-guided MMT. To better capture the shared semantics between text and video, we propose an MMT model based on a cross-modal bidirectional attention module. Extensive experiments on the TopicVD dataset demonstrate that visual information consistently improves the performance of the NMT model in documentary translation. However, the MMT model's performance significantly declines in out-of-domain scenarios, highlighting the need for effective domain adaptation methods. Additionally, experiments demonstrate that global context can effectively improve translation performance. % Dataset and our implementations are available at https://github.com/JinzeLv/TopicVD