 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Diffusion Denoised Smoothing
Oct 27, 2023Along with recent diffusion models, randomized smoothing has become one of a few tangible approaches that offers adversarial robustness to models at scale, e.g., those of large pre-trained models. Specifically, one can perform randomized smoothing on any classifier via a simple "denoise-and-classify" pipeline, so-called denoised smoothing, given that an accurate denoiser is available - such as diffusion model. In this paper, we present scalable methods to address the current trade-off between certified robustness and accuracy in denoised smoothing. Our key idea is to "selectively" apply smoothing among multiple noise scales, coined multi-scale smoothing, which can be efficiently implemented with a single diffusion model. This approach also suggests a new objective to compare the collective robustness of multi-scale smoothed classifiers, and questions which representation of diffusion model would maximize the objective. To address this, we propose to further fine-tune diffusion model (a) to perform consistent denoising whenever the original image is recoverable, but (b) to generate rather diverse outputs otherwise. Our experiments show that the proposed multi-scale smoothing scheme combined with diffusion fine-tuning enables strong certified robustness available with high noise level while maintaining its accuracy close to non-smoothed classifiers.
Modality-Agnostic Self-Supervised Learning with Meta-Learned Masked Auto-Encoder
Oct 25, 2023Despite its practical importance across a wide range of modalities, recent advances in self-supervised learning (SSL) have been primarily focused on a few well-curated domains, e.g., vision and language, often relying on their domain-specific knowledge. For example, Masked Auto-Encoder (MAE) has become one of the popular architectures in these domains, but less has explored its potential in other modalities. In this paper, we develop MAE as a unified, modality-agnostic SSL framework. In turn, we argue meta-learning as a key to interpreting MAE as a modality-agnostic learner, and propose enhancements to MAE from the motivation to jointly improve its SSL across diverse modalities, coined MetaMAE as a result. Our key idea is to view the mask reconstruction of MAE as a meta-learning task: masked tokens are predicted by adapting the Transformer meta-learner through the amortization of unmasked tokens. Based on this novel interpretation, we propose to integrate two advanced meta-learning techniques. First, we adapt the amortized latent of the Transformer encoder using gradient-based meta-learning to enhance the reconstruction. Then, we maximize the alignment between amortized and adapted latents through task contrastive learning which guides the Transformer encoder to better encode the task-specific knowledge. Our experiment demonstrates the superiority of MetaMAE in the modality-agnostic SSL benchmark (called DABS), significantly outperforming prior baselines. Code is available at https://github.com/alinlab/MetaMAE.
Guide Your Agent with Adaptive Multimodal Rewards
Sep 19, 2023Developing an agent capable of adapting to unseen environments remains a difficult challenge in imitation learning. In this work, we present Adaptive Return-conditioned Policy (ARP), an efficient framework designed to enhance the agent's generalization ability using natural language task descriptions and pre-trained multimodal encoders. Our key idea is to calculate a similarity between visual observations and natural language instructions in the pre-trained multimodal embedding space (such as CLIP) and use it as a reward signal. We then train a return-conditioned policy using expert demonstrations labeled with multimodal rewards. Because the multimodal rewards provide adaptive signals at each timestep, our ARP effectively mitigates the goal misgeneralization. This results in superior generalization performances even when faced with unseen text instructions, compared to existing text-conditioned policies. To improve the quality of rewards, we also introduce a fine-tuning method for pre-trained multimodal encoders, further enhancing the performance. Video demonstrations and source code are available on the project website: https://sites.google.com/view/2023arp.
NeFL: Nested Federated Learning for Heterogeneous Clients
Aug 15, 2023



Federated learning (FL) is a promising approach in distributed learning keeping privacy. However, during the training pipeline of FL, slow or incapable clients (i.e., stragglers) slow down the total training time and degrade performance. System heterogeneity, including heterogeneous computing and network bandwidth, has been addressed to mitigate the impact of stragglers. Previous studies split models to tackle the issue, but with less degree-of-freedom in terms of model architecture. We propose nested federated learning (NeFL), a generalized framework that efficiently divides a model into submodels using both depthwise and widthwise scaling. NeFL is implemented by interpreting models as solving ordinary differential equations (ODEs) with adaptive step sizes. To address the inconsistency that arises when training multiple submodels with different architecture, we decouple a few parameters. NeFL enables resource-constrained clients to effectively join the FL pipeline and the model to be trained with a larger amount of data. Through a series of experiments, we demonstrate that NeFL leads to significant gains, especially for the worst-case submodel (e.g., 8.33 improvement on CIFAR-10). Furthermore, we demonstrate NeFL aligns with recent studies in FL.
Towards Safe Self-Distillation of Internet-Scale Text-to-Image Diffusion Models
Jul 12, 2023Large-scale image generation models, with impressive quality made possible by the vast amount of data available on the Internet, raise social concerns that these models may generate harmful or copyrighted content. The biases and harmfulness arise throughout the entire training process and are hard to completely remove, which have become significant hurdles to the safe deployment of these models. In this paper, we propose a method called SDD to prevent problematic content generation in text-to-image diffusion models. We self-distill the diffusion model to guide the noise estimate conditioned on the target removal concept to match the unconditional one. Compared to the previous methods, our method eliminates a much greater proportion of harmful content from the generated images without degrading the overall image quality. Furthermore, our method allows the removal of multiple concepts at once, whereas previous works are limited to removing a single concept at a time.
Collaborative Score Distillation for Consistent Visual Synthesis
Jul 04, 2023Generative priors of large-scale text-to-image diffusion models enable a wide range of new generation and editing applications on diverse visual modalities. However, when adapting these priors to complex visual modalities, often represented as multiple images (e.g., video), achieving consistency across a set of images is challenging. In this paper, we address this challenge with a novel method, Collaborative Score Distillation (CSD). CSD is based on the Stein Variational Gradient Descent (SVGD). Specifically, we propose to consider multiple samples as "particles" in the SVGD update and combine their score functions to distill generative priors over a set of images synchronously. Thus, CSD facilitates seamless integration of information across 2D images, leading to a consistent visual synthesis across multiple samples. We show the effectiveness of CSD in a variety of tasks, encompassing the visual editing of panorama images, videos, and 3D scenes. Our results underline the competency of CSD as a versatile method for enhancing inter-sample consistency, thereby broadening the applicability of text-to-image diffusion models.
infoVerse: A Universal Framework for Dataset Characterization with Multidimensional Meta-information
Jun 12, 2023



The success of NLP systems often relies on the availability of large, high-quality datasets. However, not all samples in these datasets are equally valuable for learning, as some may be redundant or noisy. Several methods for characterizing datasets based on model-driven meta-information (e.g., model's confidence) have been developed, but the relationship and complementary effects of these methods have received less attention. In this paper, we introduce infoVerse, a universal framework for dataset characterization, which provides a new feature space that effectively captures multidimensional characteristics of datasets by incorporating various model-driven meta-information. infoVerse reveals distinctive regions of the dataset that are not apparent in the original semantic space, hence guiding users (or models) in identifying which samples to focus on for exploration, assessment, or annotation. Additionally, we propose a novel sampling method on infoVerse to select a set of data points that maximizes informativeness. In three real-world applications (data pruning, active learning, and data annotation), the samples chosen on infoVerse space consistently outperform strong baselines in all applications. Our code and demo are publicly available.
Prefer to Classify: Improving Text Classifiers via Auxiliary Preference Learning
Jun 08, 2023



The development of largely human-annotated benchmarks has driven the success of deep neural networks in various NLP tasks. To enhance the effectiveness of existing benchmarks, collecting new additional input-output pairs is often too costly and challenging, particularly considering their marginal impact on improving the current model accuracy. Instead, additional or complementary annotations on the existing input texts in the benchmarks can be preferable as an efficient way to pay the additional human cost. In this paper, we investigate task-specific preferences between pairs of input texts as a new alternative way for such auxiliary data annotation. From 'pair-wise' comparisons with respect to the task, the auxiliary preference learning enables the model to learn an additional informative training signal that cannot be captured with 'instance-wise' task labels. To this end, we propose a novel multi-task learning framework, called prefer-to-classify (P2C), which can enjoy the cooperative effect of learning both the given classification task and the auxiliary preferences. Here, we provide three different ways to collect preference signals in practice: (a) implicitly extracting from annotation records (for free, but often unavailable), (b) collecting explicitly from crowd workers (high paid), or (c) pre-trained large language models such as GPT-3 (low paid). Given existing classification NLP benchmarks, we demonstrate that the proposed auxiliary preference learning via P2C on them is effective in improving text classifiers. Our codes are publicly available.
Accelerating Reinforcement Learning with Value-Conditional State Entropy Exploration
May 31, 2023A promising technique for exploration is to maximize the entropy of visited state distribution, i.e., state entropy, by encouraging uniform coverage of visited state space. While it has been effective for an unsupervised setup, it tends to struggle in a supervised setup with a task reward, where an agent prefers to visit high-value states to exploit the task reward. Such a preference can cause an imbalance between the distributions of high-value states and low-value states, which biases exploration towards low-value state regions as a result of the state entropy increasing when the distribution becomes more uniform. This issue is exacerbated when high-value states are narrowly distributed within the state space, making it difficult for the agent to complete the tasks. In this paper, we present a novel exploration technique that maximizes the value-conditional state entropy, which separately estimates the state entropies that are conditioned on the value estimates of each state, then maximizes their average. By only considering the visited states with similar value estimates for computing the intrinsic bonus, our method prevents the distribution of low-value states from affecting exploration around high-value states, and vice versa. We demonstrate that the proposed alternative to the state entropy baseline significantly accelerates various reinforcement learning algorithms across a variety of tasks within MiniGrid, DeepMind Control Suite, and Meta-World benchmarks. Source code is available at https://sites.google.com/view/rl-vcse.
S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions
May 23, 2023
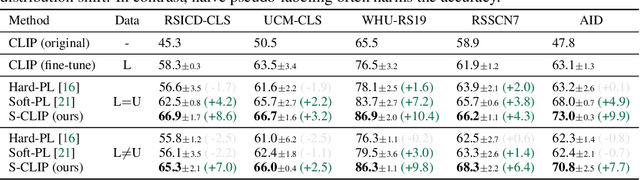

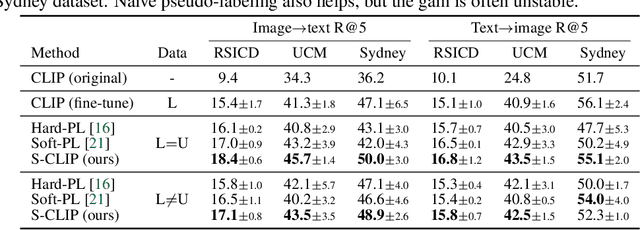
Vision-language models, such as contrastive language-image pre-training (CLIP), have demonstrated impressive results in natural image domains. However, these models often struggle when applied to specialized domains like remote sensing, and adapting to such domains is challenging due to the limited number of image-text pairs available for training. To address this, we propose S-CLIP, a semi-supervised learning method for training CLIP that utilizes additional unpaired images. S-CLIP employs two pseudo-labeling strategies specifically designed for contrastive learning and the language modality. The caption-level pseudo-label is given by a combination of captions of paired images, obtained by solving an optimal transport problem between unpaired and paired images. The keyword-level pseudo-label is given by a keyword in the caption of the nearest paired image, trained through partial label learning that assumes a candidate set of labels for supervision instead of the exact one. By combining these objectives, S-CLIP significantly enhances the training of CLIP using only a few image-text pairs, as demonstrated in various specialist domains, including remote sensing, fashion, scientific figures, and comics. For instance, S-CLIP improves CLIP by 10% for zero-shot classification and 4% for image-text retrieval on the remote sensing benchmark, matching the performance of supervised CLIP while using three times fewer image-text pairs.