 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Design Methodologies and Future Trends for Edge AI: Specialization and Co-design
Mar 30, 2021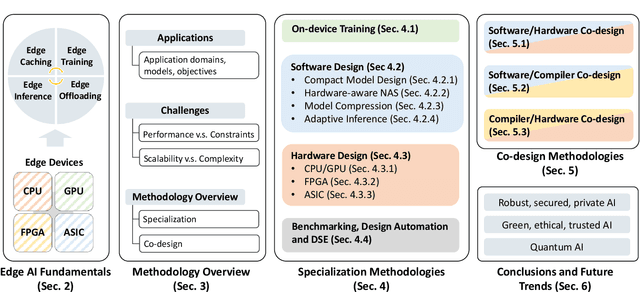
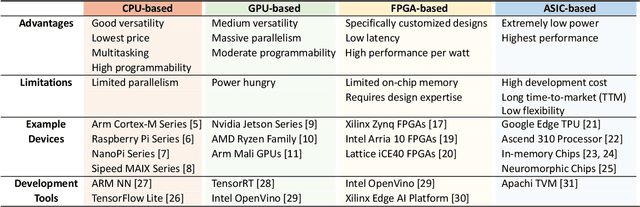

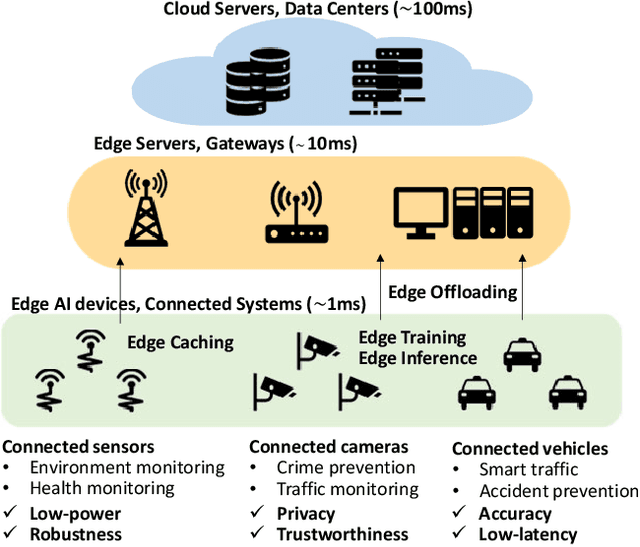
Artificial intelligence (AI) technologies have dramatically advanced in recent years, resulting in revolutionary changes in people's lives. Empowered by edge computing, AI workloads are migrating from centralized cloud architectures to distributed edge systems, introducing a new paradigm called edge AI. While edge AI has the promise of bringing significant increases in autonomy and intelligence into everyday lives through common edge devices, it also raises new challenges, especially for the development of its algorithms and the deployment of its services, which call for novel design methodologies catered to these unique challenges. In this paper, we provide a comprehensive survey of the latest enabling design methodologies that span the entire edge AI development stack. We suggest that the key methodologies for effective edge AI development are single-layer specialization and cross-layer co-design. We discuss representative methodologies in each category in detail, including on-device training methods, specialized software design, dedicated hardware design, benchmarking and design automation, software/hardware co-design, software/compiler co-design, and compiler/hardware co-design. Moreover, we attempt to reveal hidden cross-layer design opportunities that can further boost the solution quality of future edge AI and provide insights into future directions and emerging areas that require increased research focus.
Large Graph Convolutional Network Training with GPU-Oriented Data Communication Architecture
Mar 04, 2021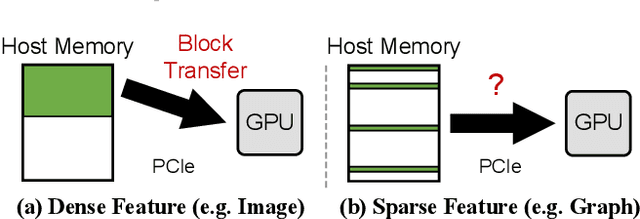

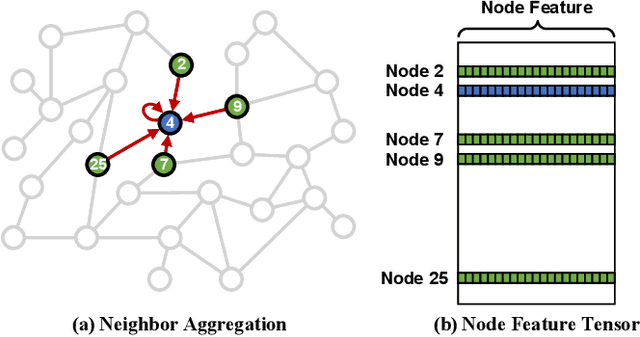

Graph Convolutional Networks (GCNs) are increasingly adopted in large-scale graph-based recommender systems. Training GCN requires the minibatch generator traversing graphs and sampling the sparsely located neighboring nodes to obtain their features. Since real-world graphs often exceed the capacity of GPU memory, current GCN training systems keep the feature table in host memory and rely on the CPU to collect sparse features before sending them to the GPUs. This approach, however, puts tremendous pressure on host memory bandwidth and the CPU. This is because the CPU needs to (1) read sparse features from memory, (2) write features into memory as a dense format, and (3) transfer the features from memory to the GPUs. In this work, we propose a novel GPU-oriented data communication approach for GCN training, where GPU threads directly access sparse features in host memory through zero-copy accesses without much CPU help. By removing the CPU gathering stage, our method significantly reduces the consumption of the host resources and data access latency. We further present two important techniques to achieve high host memory access efficiency by the GPU: (1) automatic data access address alignment to maximize PCIe packet efficiency, and (2) asynchronous zero-copy access and kernel execution to fully overlap data transfer with training. We incorporate our method into PyTorch and evaluate its effectiveness using several graphs with sizes up to 111 million nodes and 1.6 billion edges. In a multi-GPU training setup, our method is 65-92% faster than the conventional data transfer method, and can even match the performance of all-in-GPU-memory training for some graphs that fit in GPU memory.
PyTorch-Direct: Enabling GPU Centric Data Access for Very Large Graph Neural Network Training with Irregular Accesses
Jan 20, 2021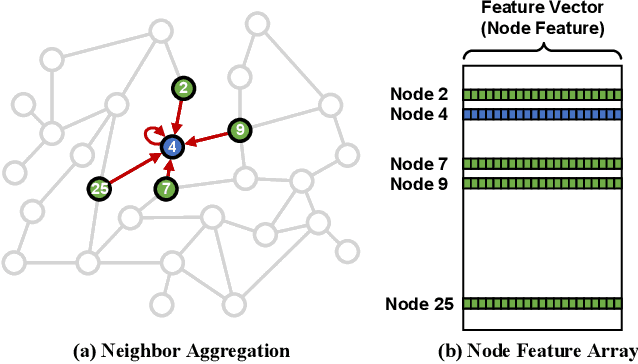

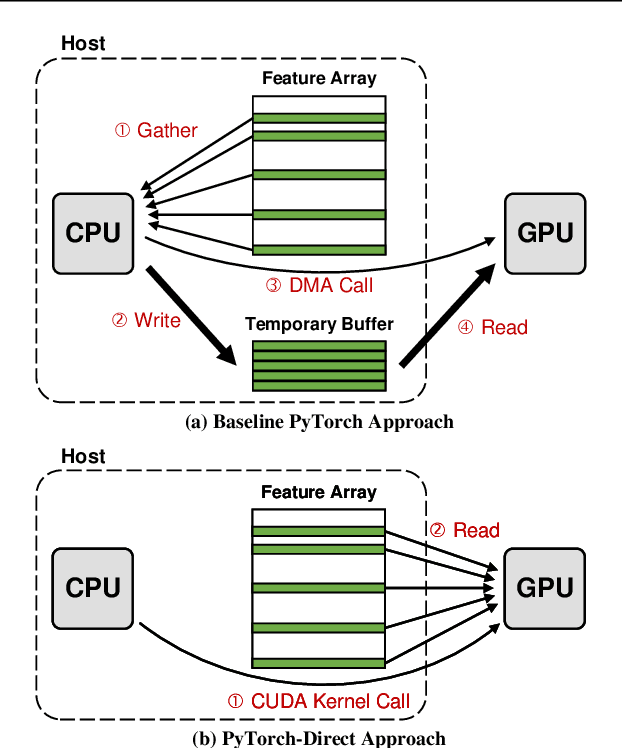

With the increasing adoption of graph neural networks (GNNs) in the machine learning community, GPUs have become an essential tool to accelerate GNN training. However, training GNNs on very large graphs that do not fit in GPU memory is still a challenging task. Unlike conventional neural networks, mini-batching input samples in GNNs requires complicated tasks such as traversing neighboring nodes and gathering their feature values. While this process accounts for a significant portion of the training time, we find existing GNN implementations using popular deep neural network (DNN) libraries such as PyTorch are limited to a CPU-centric approach for the entire data preparation step. This "all-in-CPU" approach has negative impact on the overall GNN training performance as it over-utilizes CPU resources and hinders GPU acceleration of GNN training. To overcome such limitations, we introduce PyTorch-Direct, which enables a GPU-centric data accessing paradigm for GNN training. In PyTorch-Direct, GPUs are capable of efficiently accessing complicated data structures in host memory directly without CPU intervention. Our microbenchmark and end-to-end GNN training results show that PyTorch-Direct reduces data transfer time by 47.1% on average and speeds up GNN training by up to 1.6x. Furthermore, by reducing CPU utilization, PyTorch-Direct also saves system power by 12.4% to 17.5% during training. To minimize programmer effort, we introduce a new "unified tensor" type along with necessary changes to the PyTorch memory allocator, dispatch logic, and placement rules. As a result, users need to change at most two lines of their PyTorch GNN training code for each tensor object to take advantage of PyTorch-Direct.
When Machine Learning Meets Quantum Computers: A Case Study
Dec 18, 2020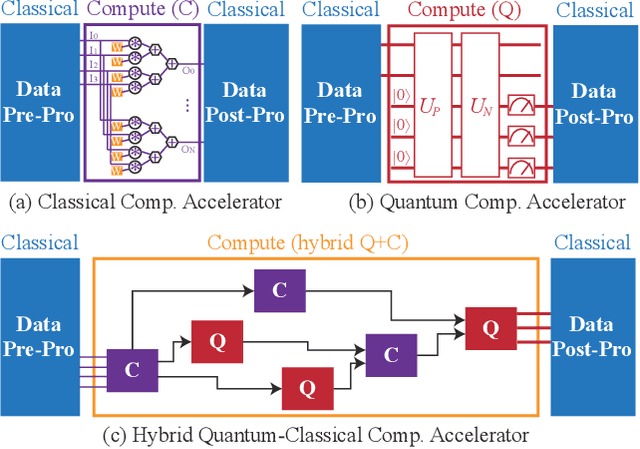
Along with the development of AI democratization, the machine learning approach, in particular neural networks, has been applied to wide-range applications. In different application scenarios, the neural network will be accelerated on the tailored computing platform. The acceleration of neural networks on classical computing platforms, such as CPU, GPU, FPGA, ASIC, has been widely studied; however, when the scale of the application consistently grows up, the memory bottleneck becomes obvious, widely known as memory-wall. In response to such a challenge, advanced quantum computing, which can represent 2^N states with N quantum bits (qubits), is regarded as a promising solution. It is imminent to know how to design the quantum circuit for accelerating neural networks. Most recently, there are initial works studying how to map neural networks to actual quantum processors. To better understand the state-of-the-art design and inspire new design methodology, this paper carries out a case study to demonstrate an end-to-end implementation. On the neural network side, we employ the multilayer perceptron to complete image classification tasks using the standard and widely used MNIST dataset. On the quantum computing side, we target IBM Quantum processors, which can be programmed and simulated by using IBM Qiskit. This work targets the acceleration of the inference phase of a trained neural network on the quantum processor. Along with the case study, we will demonstrate the typical procedure for mapping neural networks to quantum circuits.
Interpretable Visual Reasoning via Induced Symbolic Space
Nov 23, 2020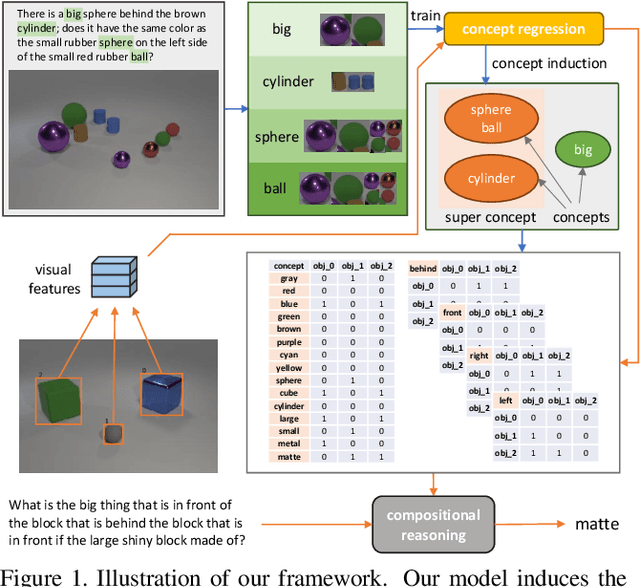
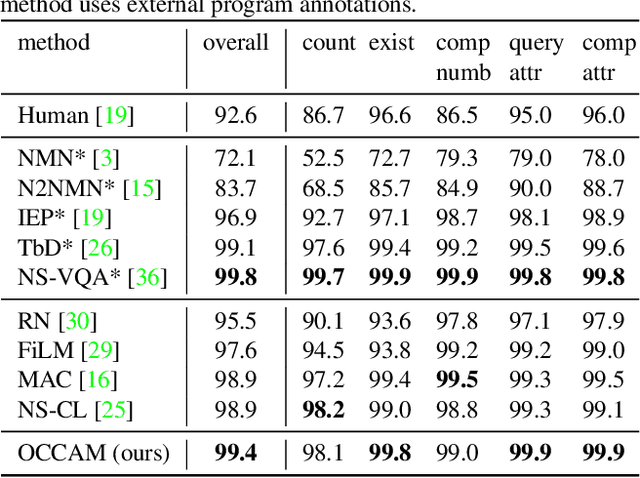
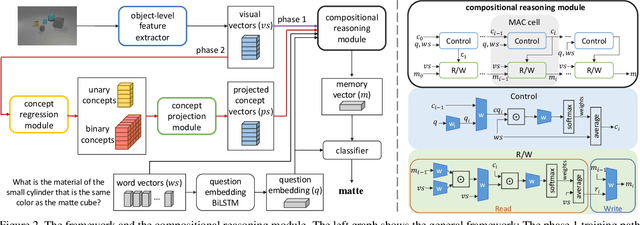

We study the problem of concept induction in visual reasoning, i.e., identifying concepts and their hierarchical relationships from question-answer pairs associated with images; and achieve an interpretable model via working on the induced symbolic concept space. To this end, we first design a new framework named object-centric compositional attention model (OCCAM) to perform the visual reasoning task with object-level visual features. Then, we come up with a method to induce concepts of objects and relations using clues from the attention patterns between objects' visual features and question words. Finally, we achieve a higher level of interpretability by imposing OCCAM on the objects represented in the induced symbolic concept space. Experiments on the CLEVR dataset demonstrate: 1) our OCCAM achieves a new state of the art without human-annotated functional programs; 2) our induced concepts are both accurate and sufficient as OCCAM achieves an on-par performance on objects represented either in visual features or in the induced symbolic concept space.
Effective Algorithm-Accelerator Co-design for AI Solutions on Edge Devices
Oct 15, 2020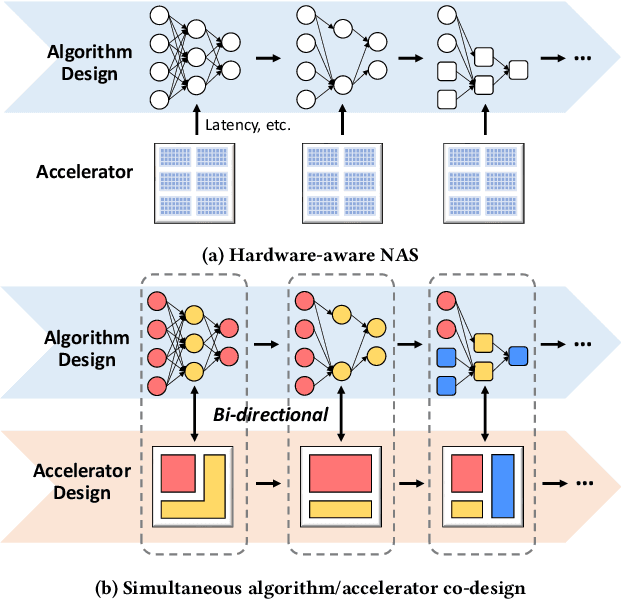
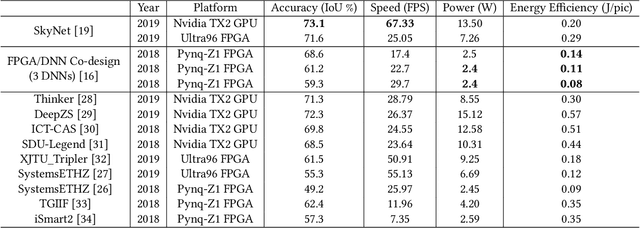
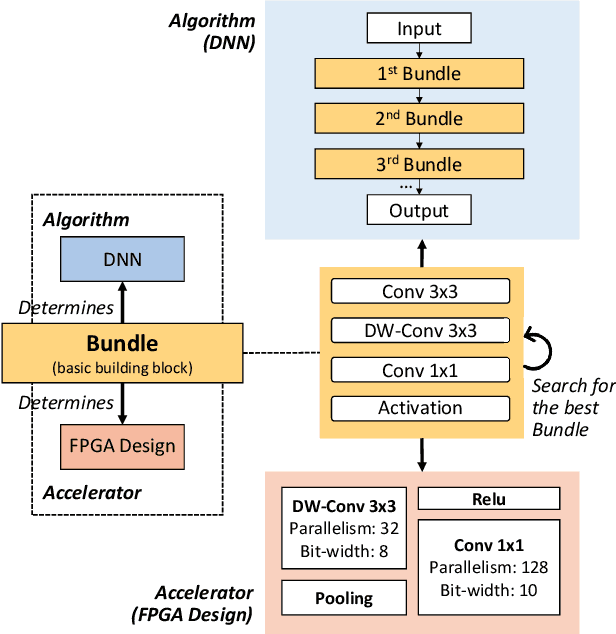
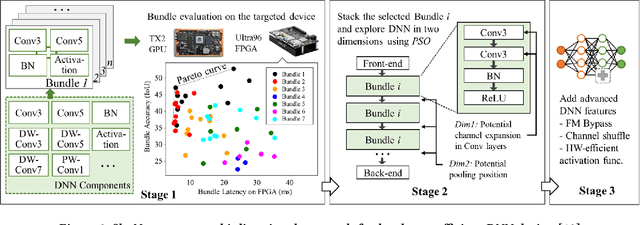
High quality AI solutions require joint optimization of AI algorithms, such as deep neural networks (DNNs), and their hardware accelerators. To improve the overall solution quality as well as to boost the design productivity, efficient algorithm and accelerator co-design methodologies are indispensable. In this paper, we first discuss the motivations and challenges for the Algorithm/Accelerator co-design problem and then provide several effective solutions. Especially, we highlight three leading works of effective co-design methodologies: 1) the first simultaneous DNN/FPGA co-design method; 2) a bi-directional lightweight DNN and accelerator co-design method; 3) a differentiable and efficient DNN and accelerator co-search method. We demonstrate the effectiveness of the proposed co-design approaches using extensive experiments on both FPGAs and GPUs, with comparisons to existing works. This paper emphasizes the importance and efficacy of algorithm-accelerator co-design and calls for more research breakthroughs in this interesting and demanding area.
Exploring Semantic Capacity of Terms
Oct 05, 2020
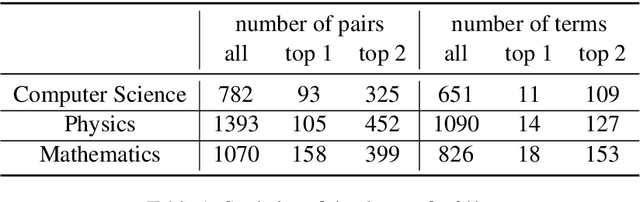
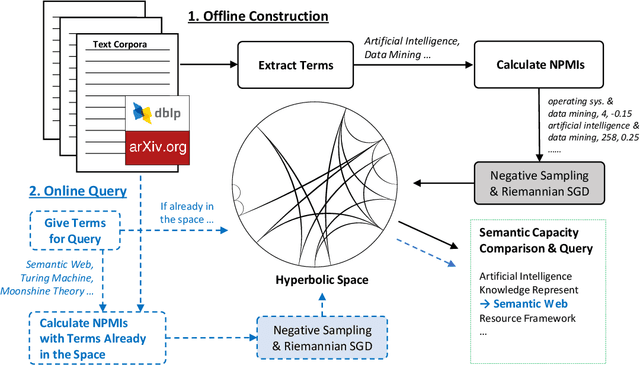
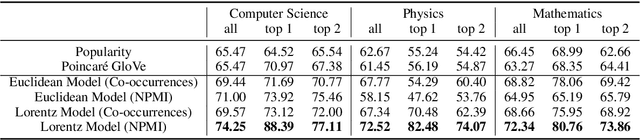
We introduce and study semantic capacity of terms. For example, the semantic capacity of artificial intelligence is higher than that of linear regression since artificial intelligence possesses a broader meaning scope. Understanding semantic capacity of terms will help many downstream tasks in natural language processing. For this purpose, we propose a two-step model to investigate semantic capacity of terms, which takes a large text corpus as input and can evaluate semantic capacity of terms if the text corpus can provide enough co-occurrence information of terms. Extensive experiments in three fields demonstrate the effectiveness and rationality of our model compared with well-designed baselines and human-level evaluations.
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020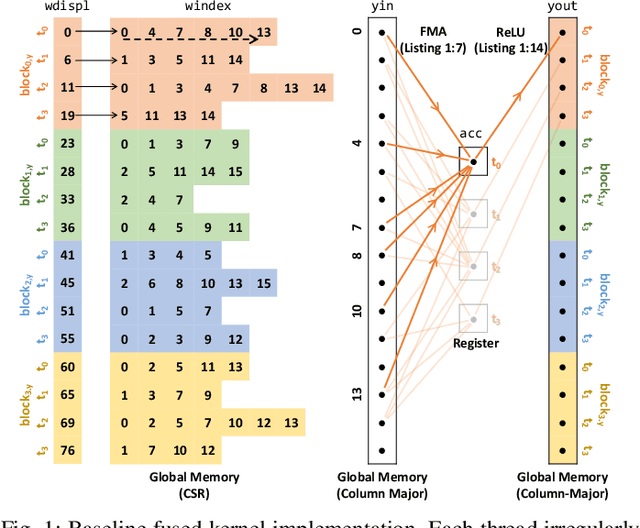
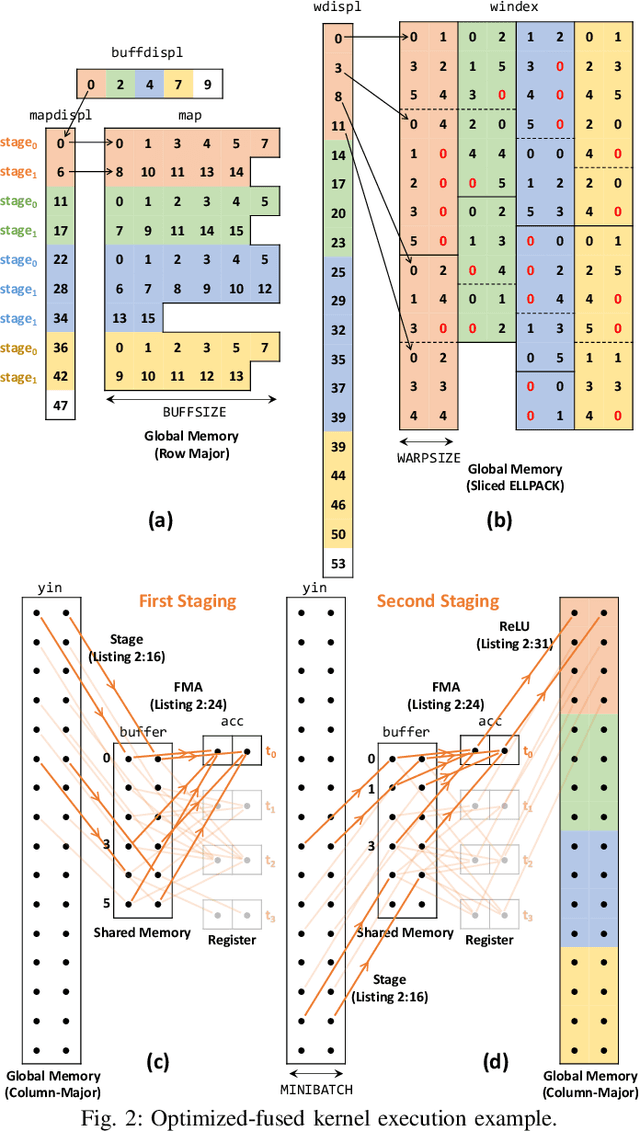
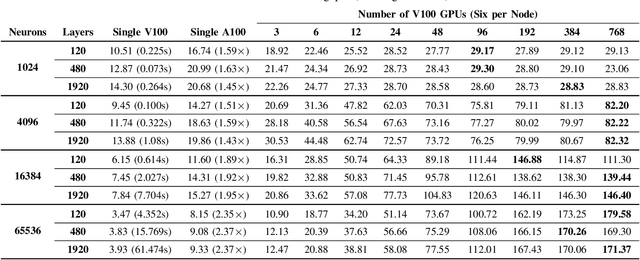
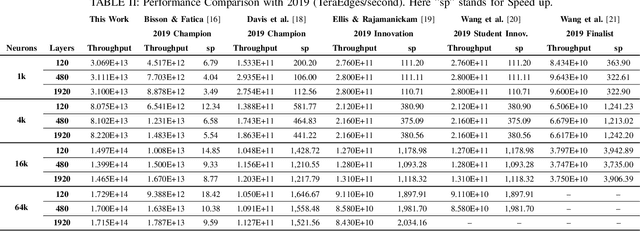
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages
Practical Detection of Trojan Neural Networks: Data-Limited and Data-Free Cases
Jul 31, 2020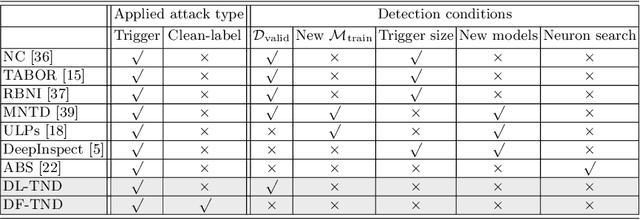
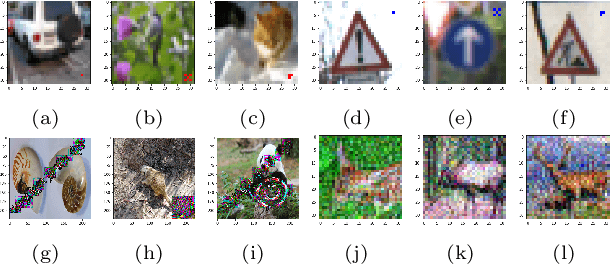
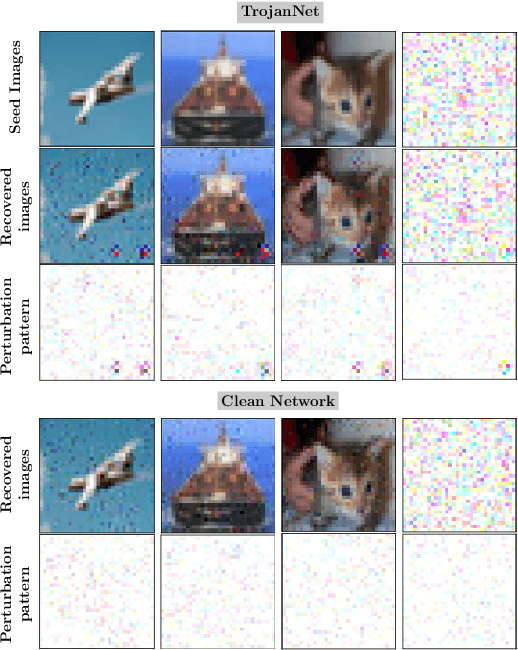
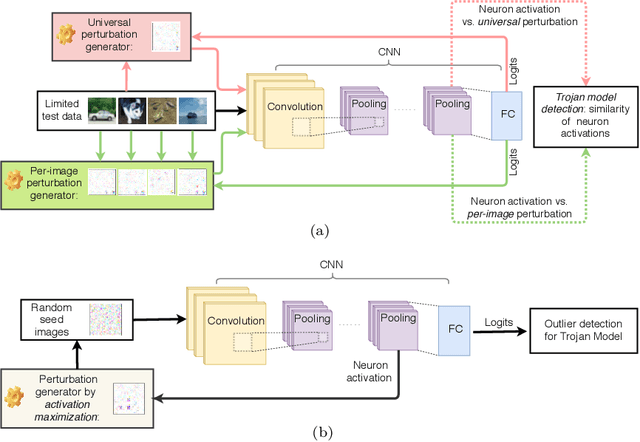
When the training data are maliciously tampered, the predictions of the acquired deep neural network (DNN) can be manipulated by an adversary known as the Trojan attack (or poisoning backdoor attack). The lack of robustness of DNNs against Trojan attacks could significantly harm real-life machine learning (ML) systems in downstream applications, therefore posing widespread concern to their trustworthiness. In this paper, we study the problem of the Trojan network (TrojanNet) detection in the data-scarce regime, where only the weights of a trained DNN are accessed by the detector. We first propose a data-limited TrojanNet detector (TND), when only a few data samples are available for TrojanNet detection. We show that an effective data-limited TND can be established by exploring connections between Trojan attack and prediction-evasion adversarial attacks including per-sample attack as well as all-sample universal attack. In addition, we propose a data-free TND, which can detect a TrojanNet without accessing any data samples. We show that such a TND can be built by leveraging the internal response of hidden neurons, which exhibits the Trojan behavior even at random noise inputs. The effectiveness of our proposals is evaluated by extensive experiments under different model architectures and datasets including CIFAR-10, GTSRB, and ImageNet.
ICA-UNet: ICA Inspired Statistical UNet for Real-time 3D Cardiac Cine MRI Segmentation
Jul 18, 2020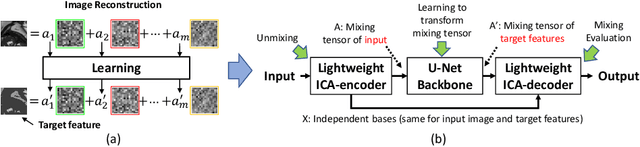
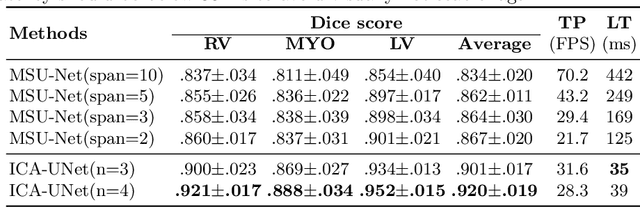
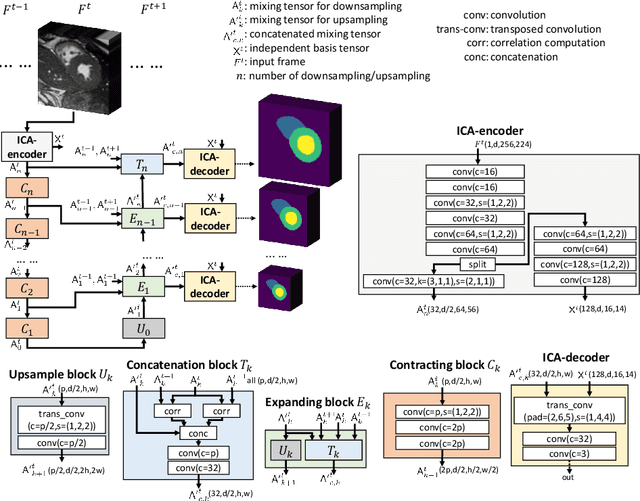
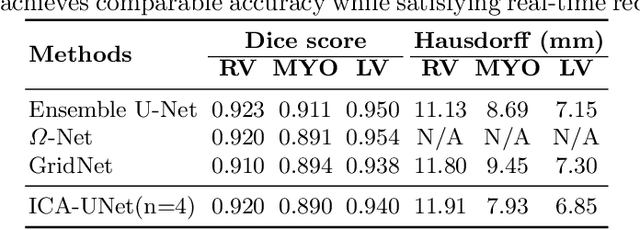
Real-time cine magnetic resonance imaging (MRI) plays an increasingly important role in various cardiac interventions. In order to enable fast and accurate visual assistance, the temporal frames need to be segmented on-the-fly. However, state-of-the-art MRI segmentation methods are used either offline because of their high computation complexity, or in real-time but with significant accuracy loss and latency increase (causing visually noticeable lag). As such, they can hardly be adopted to assist visual guidance. In this work, inspired by a new interpretation of Independent Component Analysis (ICA) for learning, we propose a novel ICA-UNet for real-time 3D cardiac cine MRI segmentation. Experiments using the MICCAI ACDC 2017 dataset show that, compared with the state-of-the-arts, ICA-UNet not only achieves higher Dice scores, but also meets the real-time requirements for both throughput and latency (up to 12.6X reduction), enabling real-time guidance for cardiac interventions without visual lag.