 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHyLL: Learning Continuous Neural Representations of Hybrid Systems
Dec 10, 2025Learning the flows of hybrid systems that have both continuous and discrete time dynamics is challenging. The existing method learns the dynamics in each discrete mode, which suffers from the combination of mode switching and discontinuities in the flows. In this work, we propose CHyLL (Continuous Hybrid System Learning in Latent Space), which learns a continuous neural representation of a hybrid system without trajectory segmentation, event functions, or mode switching. The key insight of CHyLL is that the reset map glues the state space at the guard surface, reformulating the state space as a piecewise smooth quotient manifold where the flow becomes spatially continuous. Building upon these insights and the embedding theorems grounded in differential topology, CHyLL concurrently learns a singularity-free neural embedding in a higher-dimensional space and the continuous flow in it. We showcase that CHyLL can accurately predict the flow of hybrid systems with superior accuracy and identify the topological invariants of the hybrid systems. Finally, we apply CHyLL to the stochastic optimal control problem.
OceanSim: A GPU-Accelerated Underwater Robot Perception Simulation Framework
Mar 03, 2025Underwater simulators offer support for building robust underwater perception solutions. Significant work has recently been done to develop new simulators and to advance the performance of existing underwater simulators. Still, there remains room for improvement on physics-based underwater sensor modeling and rendering efficiency. In this paper, we propose OceanSim, a high-fidelity GPU-accelerated underwater simulator to address this research gap. We propose advanced physics-based rendering techniques to reduce the sim-to-real gap for underwater image simulation. We develop OceanSim to fully leverage the computing advantages of GPUs and achieve real-time imaging sonar rendering and fast synthetic data generation. We evaluate the capabilities and realism of OceanSim using real-world data to provide qualitative and quantitative results. The project page for OceanSim is https://umfieldrobotics.github.io/OceanSim.
MemFusionMap: Working Memory Fusion for Online Vectorized HD Map Construction
Sep 26, 2024



High-definition (HD) maps provide environmental information for autonomous driving systems and are essential for safe planning. While existing methods with single-frame input achieve impressive performance for online vectorized HD map construction, they still struggle with complex scenarios and occlusions. We propose MemFusionMap, a novel temporal fusion model with enhanced temporal reasoning capabilities for online HD map construction. Specifically, we contribute a working memory fusion module that improves the model's memory capacity to reason across history frames. We also design a novel temporal overlap heatmap to explicitly inform the model about the temporal overlap information and vehicle trajectory in the Bird's Eye View space. By integrating these two designs, MemFusionMap significantly outperforms existing methods while also maintaining a versatile design for scalability. We conduct extensive evaluation on open-source benchmarks and demonstrate a maximum improvement of 5.4% in mAP over state-of-the-art methods. The code for MemFusionMap will be made open-source upon publication of this paper.
TURTLMap: Real-time Localization and Dense Mapping of Low-texture Underwater Environments with a Low-cost Unmanned Underwater Vehicle
Aug 02, 2024Significant work has been done on advancing localization and mapping in underwater environments. Still, state-of-the-art methods are challenged by low-texture environments, which is common for underwater settings. This makes it difficult to use existing methods in diverse, real-world scenes. In this paper, we present TURTLMap, a novel solution that focuses on textureless underwater environments through a real-time localization and mapping method. We show that this method is low-cost, and capable of tracking the robot accurately, while constructing a dense map of a low-textured environment in real-time. We evaluate the proposed method using real-world data collected in an indoor water tank with a motion capture system and ground truth reference map. Qualitative and quantitative results validate the proposed system achieves accurate and robust localization and precise dense mapping, even when subject to wave conditions. The project page for TURTLMap is https://umfieldrobotics.github.io/TURTLMap.
CRKD: Enhanced Camera-Radar Object Detection with Cross-modality Knowledge Distillation
Mar 28, 2024



In the field of 3D object detection for autonomous driving, LiDAR-Camera (LC) fusion is the top-performing sensor configuration. Still, LiDAR is relatively high cost, which hinders adoption of this technology for consumer automobiles. Alternatively, camera and radar are commonly deployed on vehicles already on the road today, but performance of Camera-Radar (CR) fusion falls behind LC fusion. In this work, we propose Camera-Radar Knowledge Distillation (CRKD) to bridge the performance gap between LC and CR detectors with a novel cross-modality KD framework. We use the Bird's-Eye-View (BEV) representation as the shared feature space to enable effective knowledge distillation. To accommodate the unique cross-modality KD path, we propose four distillation losses to help the student learn crucial features from the teacher model. We present extensive evaluations on the nuScenes dataset to demonstrate the effectiveness of the proposed CRKD framework. The project page for CRKD is https://song-jingyu.github.io/CRKD.
LiRaFusion: Deep Adaptive LiDAR-Radar Fusion for 3D Object Detection
Feb 18, 2024



We propose LiRaFusion to tackle LiDAR-radar fusion for 3D object detection to fill the performance gap of existing LiDAR-radar detectors. To improve the feature extraction capabilities from these two modalities, we design an early fusion module for joint voxel feature encoding, and a middle fusion module to adaptively fuse feature maps via a gated network. We perform extensive evaluation on nuScenes to demonstrate that LiRaFusion leverages the complementary information of LiDAR and radar effectively and achieves notable improvement over existing methods.
Uncertainty-Aware Acoustic Localization and Mapping for Underwater Robots
Jul 17, 2023



For underwater vehicles, robotic applications have the added difficulty of operating in highly unstructured and dynamic environments. Environmental effects impact not only the dynamics and controls of the robot but also the perception and sensing modalities. Acoustic sensors, which inherently use mechanically vibrated signals for measuring range or velocity, are particularly prone to the effects that such dynamic environments induce. This paper presents an uncertainty-aware localization and mapping framework that accounts for induced disturbances in acoustic sensing modalities for underwater robots operating near the surface in dynamic wave conditions. For the state estimation task, the uncertainty is accounted for as the added noise caused by the environmental disturbance. The mapping method uses an adaptive kernel-based method to propagate measurement and pose uncertainty into an occupancy map. Experiments are carried out in a wave tank environment to perform qualitative and quantitative evaluations of the proposed method. More details about this project can be found at https://umfieldrobotics.github.io/PUMA.github.io.
Convolutional Bayesian Kernel Inference for 3D Semantic Mapping
Sep 21, 2022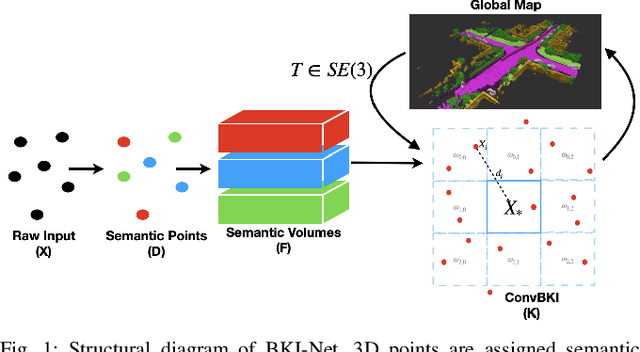
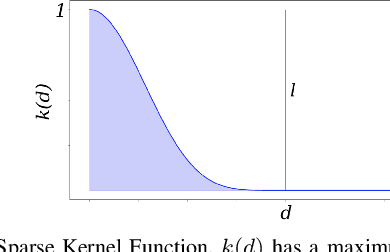
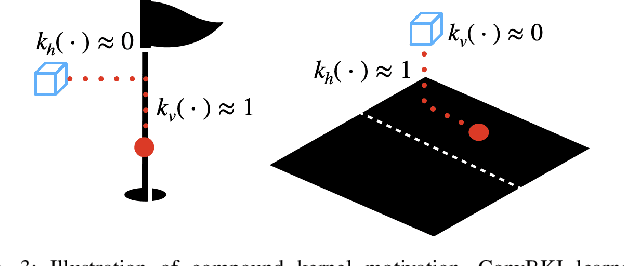
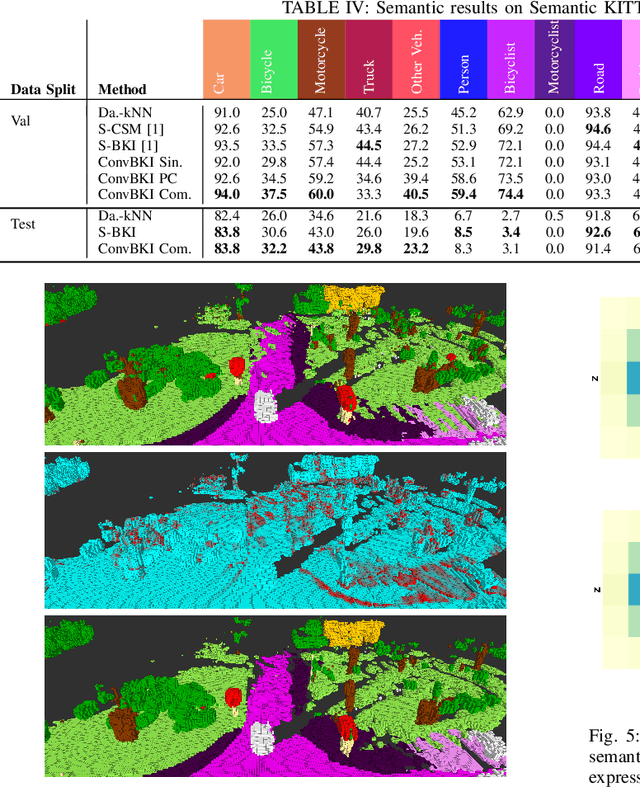
Robotic perception is currently at a cross-roads between modern methods which operate in an efficient latent space, and classical methods which are mathematically founded and provide interpretable, trustworthy results. In this paper, we introduce a Convolutional Bayesian Kernel Inference (ConvBKI) layer which explicitly performs Bayesian inference within a depthwise separable convolution layer to simultaneously maximize efficiency while maintaining reliability. We apply our layer to the task of 3D semantic mapping, where we learn semantic-geometric probability distributions for LiDAR sensor information in real time. We evaluate our network against state-of-the-art semantic mapping algorithms on the KITTI data set, and demonstrate improved latency with comparable semantic results.
MotionSC: Data Set and Network for Real-Time Semantic Mapping in Dynamic Environments
Mar 14, 2022
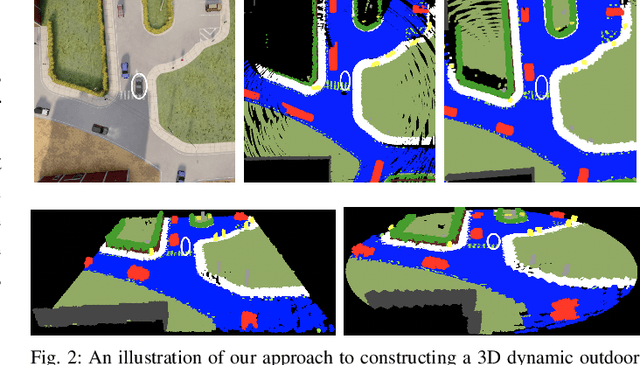

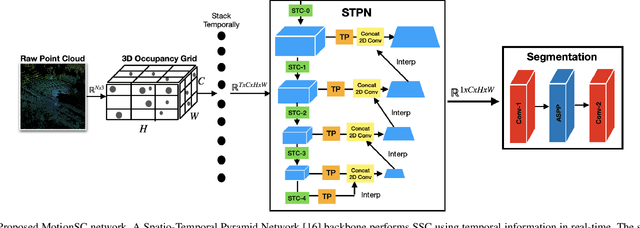
This work addresses a gap in semantic scene completion (SSC) data by creating a novel outdoor data set with accurate and complete dynamic scenes. Our data set is formed from randomly sampled views of the world at each time step, which supervises generalizability to complete scenes without occlusions or traces. We create SSC baselines from state-of-the-art open source networks and construct a benchmark real-time dense local semantic mapping algorithm, MotionSC, by leveraging recent 3D deep learning architectures to enhance SSC with temporal information. Our network shows that the proposed data set can quantify and supervise accurate scene completion in the presence of dynamic objects, which can lead to the development of improved dynamic mapping algorithms. All software is available at https://github.com/UMich-CURLY/3DMapping.