 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vision-Language Tasks Benefit from Large Pre-trained Models: A Survey
Dec 11, 2024



The exploration of various vision-language tasks, such as visual captioning, visual question answering, and visual commonsense reasoning, is an important area in artificial intelligence and continuously attracts the research community's attention. Despite the improvements in overall performance, classic challenges still exist in vision-language tasks and hinder the development of this area. In recent years, the rise of pre-trained models is driving the research on vision-language tasks. Thanks to the massive scale of training data and model parameters, pre-trained models have exhibited excellent performance in numerous downstream tasks. Inspired by the powerful capabilities of pre-trained models, new paradigms have emerged to solve the classic challenges. Such methods have become mainstream in current research with increasing attention and rapid advances. In this paper, we present a comprehensive overview of how vision-language tasks benefit from pre-trained models. First, we review several main challenges in vision-language tasks and discuss the limitations of previous solutions before the era of pre-training. Next, we summarize the recent advances in incorporating pre-trained models to address the challenges in vision-language tasks. Finally, we analyze the potential risks associated with the inherent limitations of pre-trained models and discuss possible solutions, attempting to provide future research directions.
Video Captioning Using Weak Annotation
Sep 02, 2020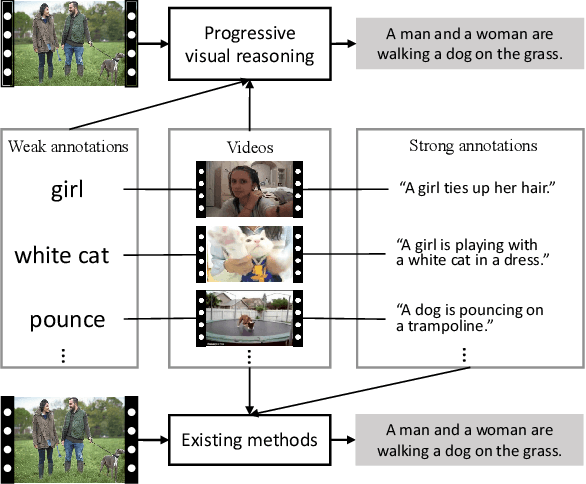
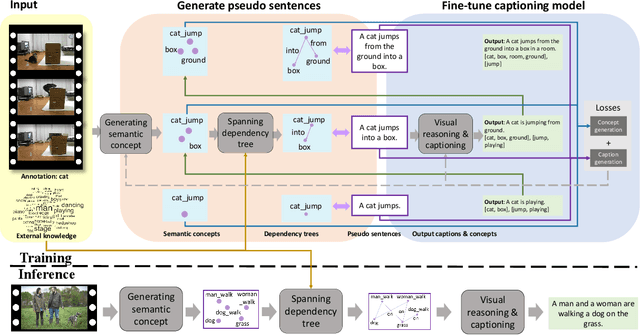
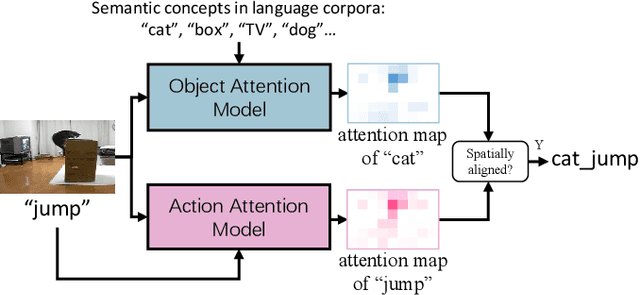
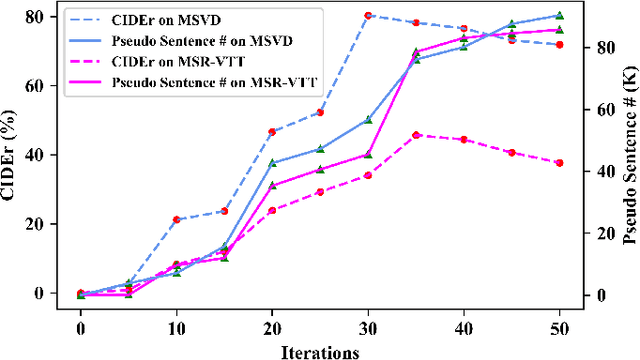
Video captioning has shown impressive progress in recent years. One key reason of the performance improvements made by existing methods lie in massive paired video-sentence data, but collecting such strong annotation, i.e., high-quality sentences, is time-consuming and laborious. It is the fact that there now exist an amazing number of videos with weak annotation that only contains semantic concepts such as actions and objects. In this paper, we investigate using weak annotation instead of strong annotation to train a video captioning model. To this end, we propose a progressive visual reasoning method that progressively generates fine sentences from weak annotations by inferring more semantic concepts and their dependency relationships for video captioning. To model concept relationships, we use dependency trees that are spanned by exploiting external knowledge from large sentence corpora. Through traversing the dependency trees, the sentences are generated to train the captioning model. Accordingly, we develop an iterative refinement algorithm that refines sentences via spanning dependency trees and fine-tunes the captioning model using the refined sentences in an alternative training manner. Experimental results demonstrate that our method using weak annotation is very competitive to the state-of-the-art methods using strong annotation.
Relational Reasoning using Prior Knowledge for Visual Captioning
Jun 04, 2019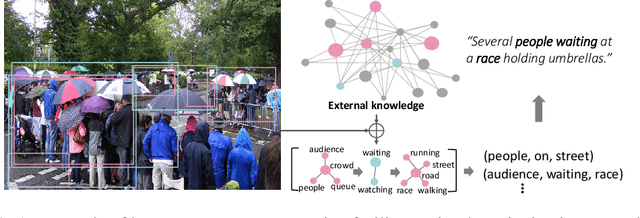
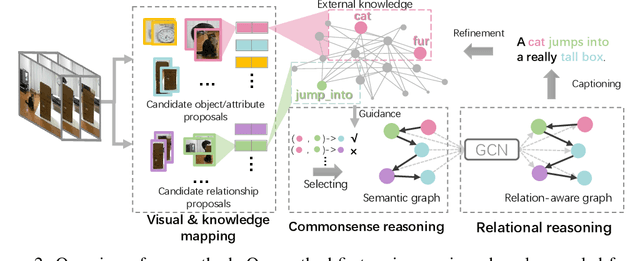

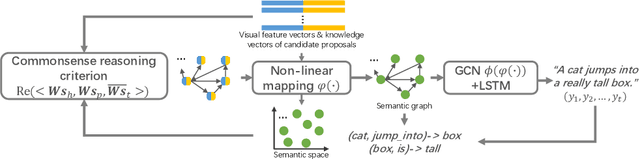
Exploiting relationships among objects has achieved remarkable progress in interpreting images or videos by natural language. Most existing methods resort to first detecting objects and their relationships, and then generating textual descriptions, which heavily depends on pre-trained detectors and leads to performance drop when facing problems of heavy occlusion, tiny-size objects and long-tail in object detection. In addition, the separate procedure of detecting and captioning results in semantic inconsistency between the pre-defined object/relation categories and the target lexical words. We exploit prior human commonsense knowledge for reasoning relationships between objects without any pre-trained detectors and reaching semantic coherency within one image or video in captioning. The prior knowledge (e.g., in the form of knowledge graph) provides commonsense semantic correlation and constraint between objects that are not explicit in the image and video, serving as useful guidance to build semantic graph for sentence generation. Particularly, we present a joint reasoning method that incorporates 1) commonsense reasoning for embedding image or video regions into semantic space to build semantic graph and 2) relational reasoning for encoding semantic graph to generate sentences. Extensive experiments on the MS-COCO image captioning benchmark and the MSVD video captioning benchmark validate the superiority of our method on leveraging prior commonsense knowledge to enhance relational reasoning for visual captioning.