 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Can Wash Better: Daily Handwashing Assessment with Smartwatches
Dec 09, 2021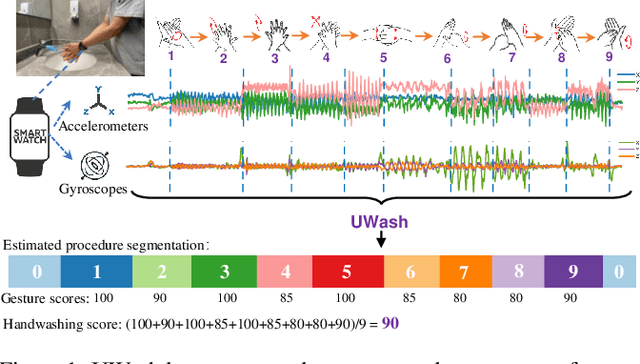
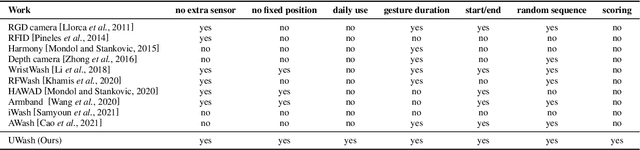
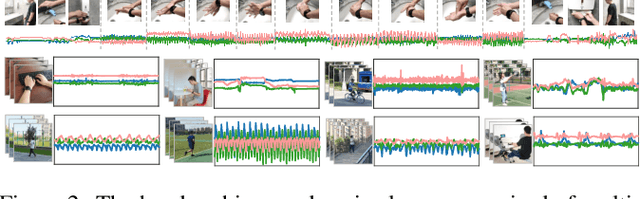
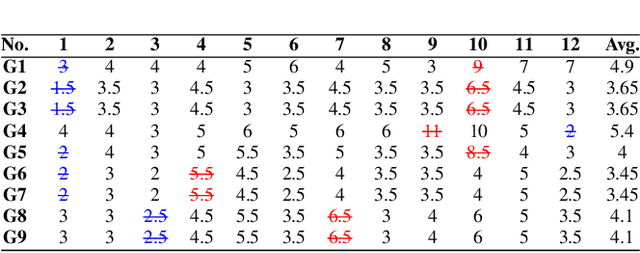
We propose UWash, an intelligent solution upon smartwatches, to assess handwashing for the purpose of raising users' awareness and cultivating habits in high-quality handwashing. UWash can identify the onset/offset of handwashing, measure the duration of each gesture, and score each gesture as well as the entire procedure in accordance with the WHO guidelines. Technically, we address the task of handwashing assessment as the semantic segmentation problem in computer vision, and propose a lightweight UNet-like network, only 496KBits, to achieve it effectively. Experiments over 51 subjects show that UWash achieves the accuracy of 92.27\% on sample-wise handwashing gesture recognition, $<$0.5 \textit{seconds} error in onset/offset detection, and $<$5 out of 100 \textit{points} error in scoring in the user-dependent setting, while remains promising in the cross-user evaluation and in the cross-user-cross-location evaluation.
PhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer
Nov 23, 2021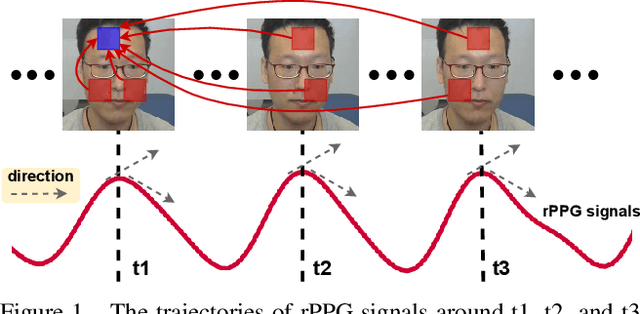
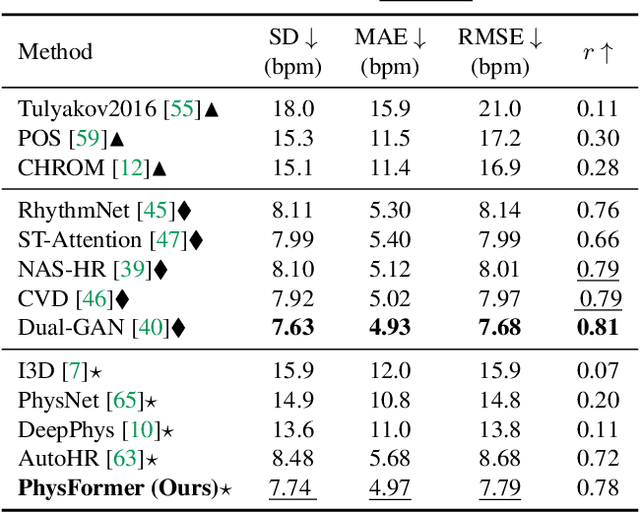
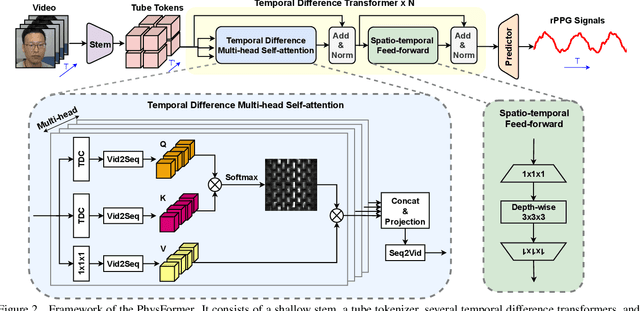
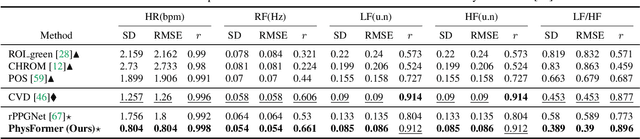
Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose the PhysFormer, an end-to-end video transformer based architecture, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. Furthermore, we also propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. One highlight is that, unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community. The codes will be released at https://github.com/ZitongYu/PhysFormer.
Revisiting Pixel-Wise Supervision for Face Anti-Spoofing
Nov 24, 2020
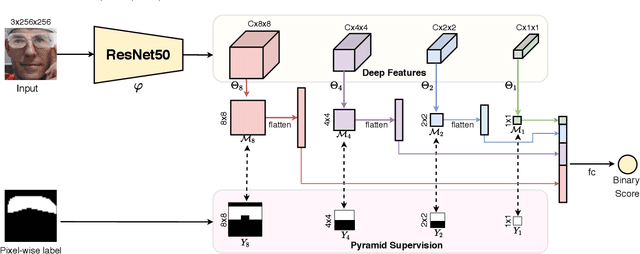
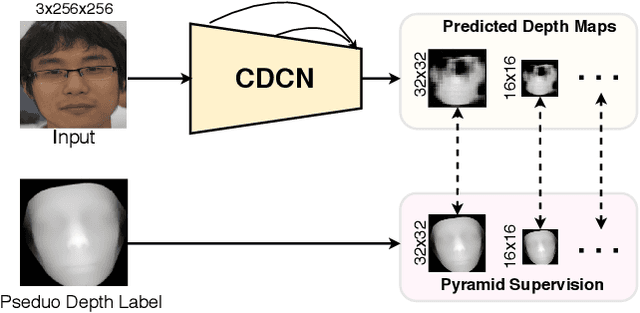
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from the presentation attacks (PAs). As more and more realistic PAs with novel types spring up, it is necessary to develop robust algorithms for detecting unknown attacks even in unseen scenarios. However, deep models supervised by traditional binary loss (e.g., `0' for bonafide vs. `1' for PAs) are weak in describing intrinsic and discriminative spoofing patterns. Recently, pixel-wise supervision has been proposed for the FAS task, intending to provide more fine-grained pixel/patch-level cues. In this paper, we firstly give a comprehensive review and analysis about the existing pixel-wise supervision methods for FAS. Then we propose a novel pyramid supervision, which guides deep models to learn both local details and global semantics from multi-scale spatial context. Extensive experiments are performed on five FAS benchmark datasets to show that, without bells and whistles, the proposed pyramid supervision could not only improve the performance beyond existing pixel-wise supervision frameworks, but also enhance the model's interpretability (i.e., locating the patch-level positions of PAs more reasonably). Furthermore, elaborate studies are conducted for exploring the efficacy of different architecture configurations with two kinds of pixel-wise supervisions (binary mask and depth map supervisions), which provides inspirable insights for future architecture/supervision design.
Mix Dimension in Poincaré Geometry for 3D Skeleton-based Action Recognition
Aug 03, 2020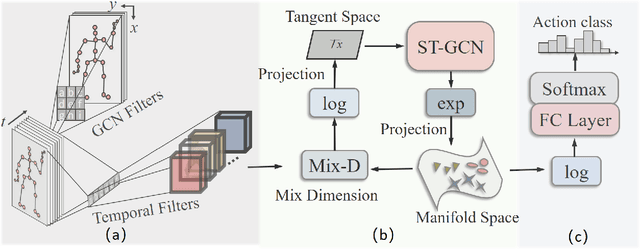

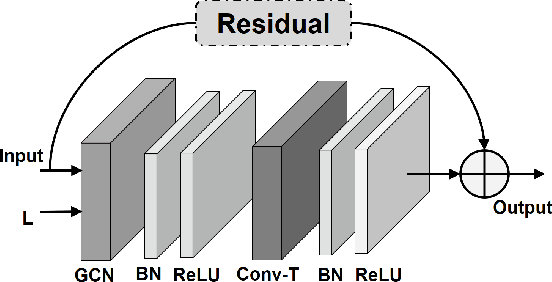
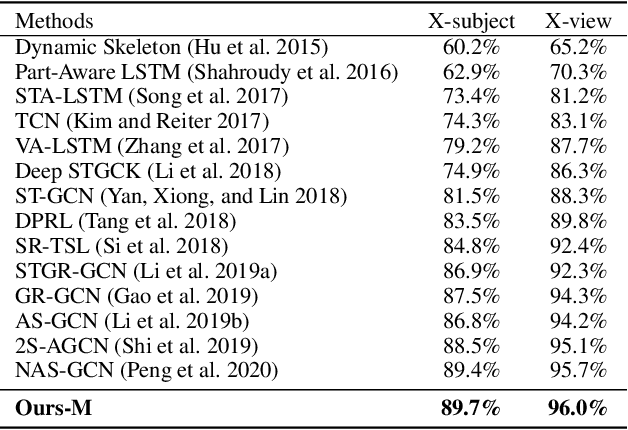
Graph Convolutional Networks (GCNs) have already demonstrated their powerful ability to model the irregular data, e.g., skeletal data in human action recognition, providing an exciting new way to fuse rich structural information for nodes residing in different parts of a graph. In human action recognition, current works introduce a dynamic graph generation mechanism to better capture the underlying semantic skeleton connections and thus improves the performance. In this paper, we provide an orthogonal way to explore the underlying connections. Instead of introducing an expensive dynamic graph generation paradigm, we build a more efficient GCN on a Riemann manifold, which we think is a more suitable space to model the graph data, to make the extracted representations fit the embedding matrix. Specifically, we present a novel spatial-temporal GCN (ST-GCN) architecture which is defined via the Poincar\'e geometry such that it is able to better model the latent anatomy of the structure data. To further explore the optimal projection dimension in the Riemann space, we mix different dimensions on the manifold and provide an efficient way to explore the dimension for each ST-GCN layer. With the final resulted architecture, we evaluate our method on two current largest scale 3D datasets, i.e., NTU RGB+D and NTU RGB+D 120. The comparison results show that the model could achieve a superior performance under any given evaluation metrics with only 40\% model size when compared with the previous best GCN method, which proves the effectiveness of our model.
Face Anti-Spoofing with Human Material Perception
Jul 04, 2020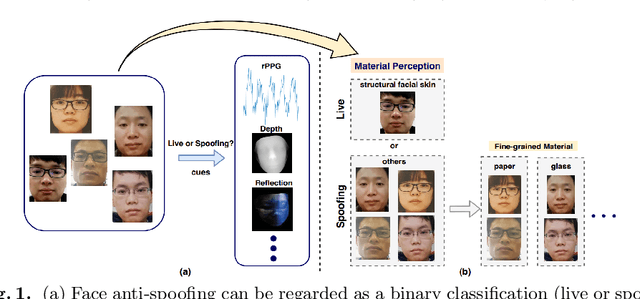
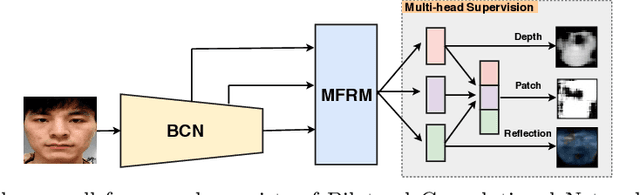


Face anti-spoofing (FAS) plays a vital role in securing the face recognition systems from presentation attacks. Most existing FAS methods capture various cues (e.g., texture, depth and reflection) to distinguish the live faces from the spoofing faces. All these cues are based on the discrepancy among physical materials (e.g., skin, glass, paper and silicone). In this paper we rephrase face anti-spoofing as a material recognition problem and combine it with classical human material perception [1], intending to extract discriminative and robust features for FAS. To this end, we propose the Bilateral Convolutional Networks (BCN), which is able to capture intrinsic material-based patterns via aggregating multi-level bilateral macro- and micro- information. Furthermore, Multi-level Feature Refinement Module (MFRM) and multi-head supervision are utilized to learn more robust features. Comprehensive experiments are performed on six benchmark datasets, and the proposed method achieves superior performance on both intra- and cross-dataset testings. One highlight is that we achieve overall 11.3$\pm$9.5\% EER for cross-type testing in SiW-M dataset, which significantly outperforms previous results. We hope this work will facilitate future cooperation between FAS and material communities.
AutoHR: A Strong End-to-end Baseline for Remote Heart Rate Measurement with Neural Searching
Apr 26, 2020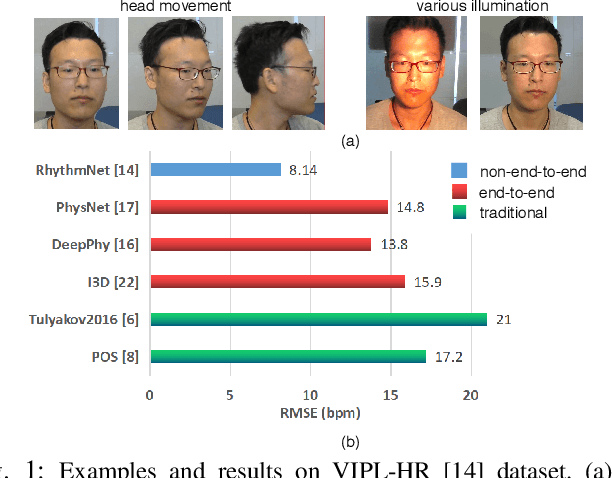
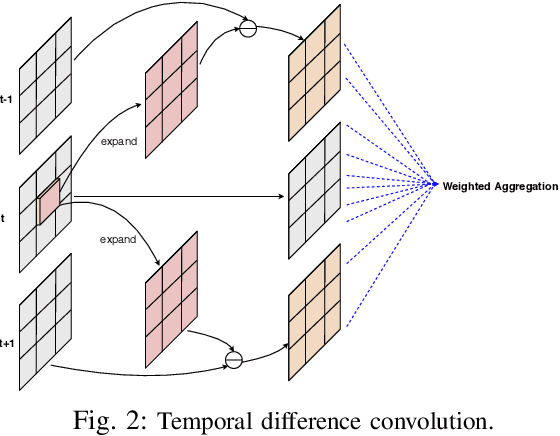
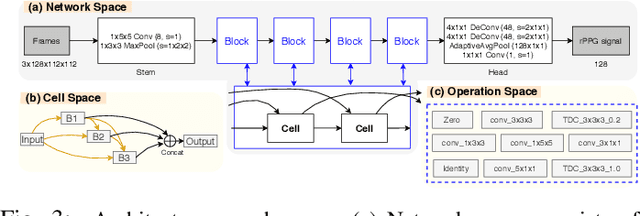
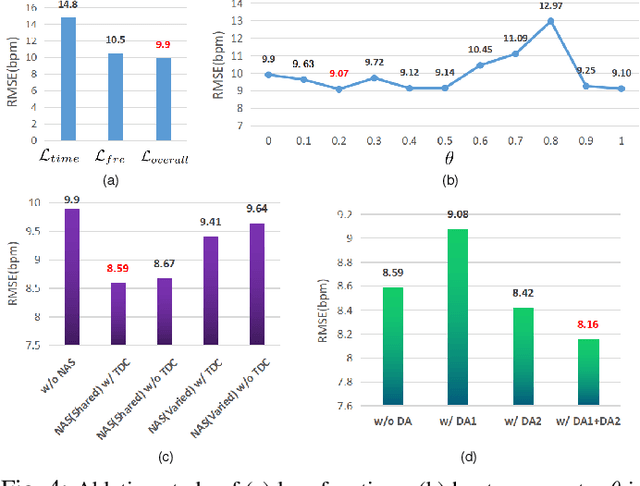
Remote photoplethysmography (rPPG), which aims at measuring heart activities without any contact, has great potential in many applications (e.g., remote healthcare). Existing end-to-end rPPG and heart rate (HR) measurement methods from facial videos are vulnerable to the less-constrained scenarios (e.g., with head movement and bad illumination). In this letter, we explore the reason why existing end-to-end networks perform poorly in challenging conditions and establish a strong end-to-end baseline (AutoHR) for remote HR measurement with neural architecture search (NAS). The proposed method includes three parts: 1) a powerful searched backbone with novel Temporal Difference Convolution (TDC), intending to capture intrinsic rPPG-aware clues between frames; 2) a hybrid loss function considering constraints from both time and frequency domains; and 3) spatio-temporal data augmentation strategies for better representation learning. Comprehensive experiments are performed on three benchmark datasets to show our superior performance on both intra- and cross-dataset testing.
Image denoising via group sparsity residual constraint
Mar 03, 2017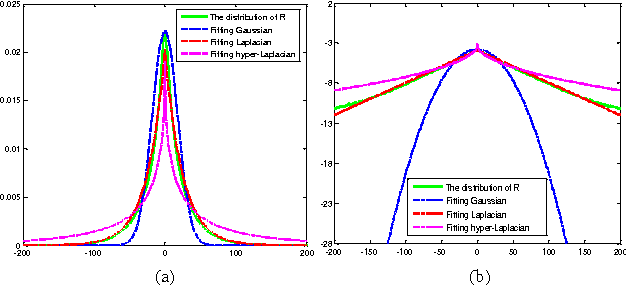
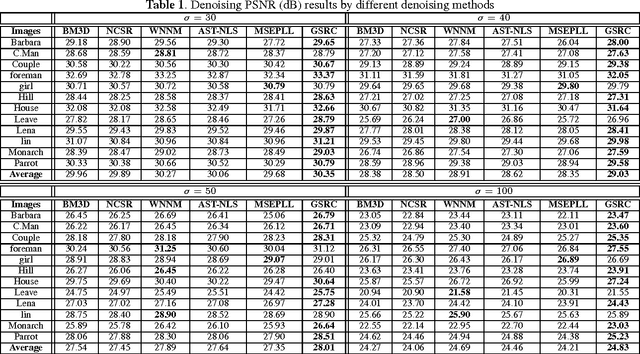


Group sparsity has shown great potential in various low-level vision tasks (e.g, image denoising, deblurring and inpainting). In this paper, we propose a new prior model for image denoising via group sparsity residual constraint (GSRC). To enhance the performance of group sparse-based image denoising, the concept of group sparsity residual is proposed, and thus, the problem of image denoising is translated into one that reduces the group sparsity residual. To reduce the residual, we first obtain some good estimation of the group sparse coefficients of the original image by the first-pass estimation of noisy image, and then centralize the group sparse coefficients of noisy image to the estimation. Experimental results have demonstrated that the proposed method not only outperforms many state-of-the-art denoising methods such as BM3D and WNNM, but results in a faster speed.
Analyzing the Affect of a Group of People Using Multi-modal Framework
Oct 13, 2016


Millions of images on the web enable us to explore images from social events such as a family party, thus it is of interest to understand and model the affect exhibited by a group of people in images. But analysis of the affect expressed by multiple people is challenging due to varied indoor and outdoor settings, and interactions taking place between various numbers of people. A few existing works on Group-level Emotion Recognition (GER) have investigated on face-level information. Due to the challenging environments, face may not provide enough information to GER. Relatively few studies have investigated multi-modal GER. Therefore, we propose a novel multi-modal approach based on a new feature description for understanding emotional state of a group of people in an image. In this paper, we firstly exploit three kinds of rich information containing face, upperbody and scene in a group-level image. Furthermore, in order to integrate multiple person's information in a group-level image, we propose an information aggregation method to generate three features for face, upperbody and scene, respectively. We fuse face, upperbody and scene information for robustness of GER against the challenging environments. Intensive experiments are performed on two challenging group-level emotion databases to investigate the role of face, upperbody and scene as well as multi-modal framework. Experimental results demonstrate that our framework achieves very promising performance for GER.