 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabelAny3D: Label Any Object 3D in the Wild
Jan 04, 2026Detecting objects in 3D space from monocular input is crucial for applications ranging from robotics to scene understanding. Despite advanced performance in the indoor and autonomous driving domains, existing monocular 3D detection models struggle with in-the-wild images due to the lack of 3D in-the-wild datasets and the challenges of 3D annotation. We introduce LabelAny3D, an \emph{analysis-by-synthesis} framework that reconstructs holistic 3D scenes from 2D images to efficiently produce high-quality 3D bounding box annotations. Built on this pipeline, we present COCO3D, a new benchmark for open-vocabulary monocular 3D detection, derived from the MS-COCO dataset and covering a wide range of object categories absent from existing 3D datasets. Experiments show that annotations generated by LabelAny3D improve monocular 3D detection performance across multiple benchmarks, outperforming prior auto-labeling approaches in quality. These results demonstrate the promise of foundation-model-driven annotation for scaling up 3D recognition in realistic, open-world settings.
Breaking the Cycle of Incarceration With Targeted Mental Health Outreach: A Case Study in Machine Learning for Public Policy
Sep 17, 2025Many incarcerated individuals face significant and complex challenges, including mental illness, substance dependence, and homelessness, yet jails and prisons are often poorly equipped to address these needs. With little support from the existing criminal justice system, these needs can remain untreated and worsen, often leading to further offenses and a cycle of incarceration with adverse outcomes both for the individual and for public safety, with particularly large impacts on communities of color that continue to widen the already extensive racial disparities in criminal justice outcomes. Responding to these failures, a growing number of criminal justice stakeholders are seeking to break this cycle through innovative approaches such as community-driven and alternative approaches to policing, mentoring, community building, restorative justice, pretrial diversion, holistic defense, and social service connections. Here we report on a collaboration between Johnson County, Kansas, and Carnegie Mellon University to perform targeted, proactive mental health outreach in an effort to reduce reincarceration rates. This paper describes the data used, our predictive modeling approach and results, as well as the design and analysis of a field trial conducted to confirm our model's predictive power, evaluate the impact of this targeted outreach, and understand at what level of reincarceration risk outreach might be most effective. Through this trial, we find that our model is highly predictive of new jail bookings, with more than half of individuals in the trial's highest-risk group returning to jail in the following year. Outreach was most effective among these highest-risk individuals, with impacts on mental health utilization, EMS dispatches, and criminal justice involvement.
Towards Large Language Models that Benefit for All: Benchmarking Group Fairness in Reward Models
Mar 10, 2025



As Large Language Models (LLMs) become increasingly powerful and accessible to human users, ensuring fairness across diverse demographic groups, i.e., group fairness, is a critical ethical concern. However, current fairness and bias research in LLMs is limited in two aspects. First, compared to traditional group fairness in machine learning classification, it requires that the non-sensitive attributes, in this case, the prompt questions, be the same across different groups. In many practical scenarios, different groups, however, may prefer different prompt questions and this requirement becomes impractical. Second, it evaluates group fairness only for the LLM's final output without identifying the source of possible bias. Namely, the bias in LLM's output can result from both the pretraining and the finetuning. For finetuning, the bias can result from both the RLHF procedure and the learned reward model. Arguably, evaluating the group fairness of each component in the LLM pipeline could help develop better methods to mitigate the possible bias. Recognizing those two limitations, this work benchmarks the group fairness of learned reward models. By using expert-written text from arXiv, we are able to benchmark the group fairness of reward models without requiring the same prompt questions across different demographic groups. Surprisingly, our results demonstrate that all the evaluated reward models (e.g., Nemotron-4-340B-Reward, ArmoRM-Llama3-8B-v0.1, and GRM-llama3-8B-sftreg) exhibit statistically significant group unfairness. We also observed that top-performing reward models (w.r.t. canonical performance metrics) tend to demonstrate better group fairness.
Open Vocabulary Monocular 3D Object Detection
Nov 25, 2024In this work, we pioneer the study of open-vocabulary monocular 3D object detection, a novel task that aims to detect and localize objects in 3D space from a single RGB image without limiting detection to a predefined set of categories. We formalize this problem, establish baseline methods, and introduce a class-agnostic approach that leverages open-vocabulary 2D detectors and lifts 2D bounding boxes into 3D space. Our approach decouples the recognition and localization of objects in 2D from the task of estimating 3D bounding boxes, enabling generalization across unseen categories. Additionally, we propose a target-aware evaluation protocol to address inconsistencies in existing datasets, improving the reliability of model performance assessment. Extensive experiments on the Omni3D dataset demonstrate the effectiveness of the proposed method in zero-shot 3D detection for novel object categories, validating its robust generalization capabilities. Our method and evaluation protocols contribute towards the development of open-vocabulary object detection models that can effectively operate in real-world, category-diverse environments.
TrajDeleter: Enabling Trajectory Forgetting in Offline Reinforcement Learning Agents
Apr 18, 2024



Reinforcement learning (RL) trains an agent from experiences interacting with the environment. In scenarios where online interactions are impractical, offline RL, which trains the agent using pre-collected datasets, has become popular. While this new paradigm presents remarkable effectiveness across various real-world domains, like healthcare and energy management, there is a growing demand to enable agents to rapidly and completely eliminate the influence of specific trajectories from both the training dataset and the trained agents. To meet this problem, this paper advocates Trajdeleter, the first practical approach to trajectory unlearning for offline RL agents. The key idea of Trajdeleter is to guide the agent to demonstrate deteriorating performance when it encounters states associated with unlearning trajectories. Simultaneously, it ensures the agent maintains its original performance level when facing other remaining trajectories. Additionally, we introduce Trajauditor, a simple yet efficient method to evaluate whether Trajdeleter successfully eliminates the specific trajectories of influence from the offline RL agent. Extensive experiments conducted on six offline RL algorithms and three tasks demonstrate that Trajdeleter requires only about 1.5% of the time needed for retraining from scratch. It effectively unlearns an average of 94.8% of the targeted trajectories yet still performs well in actual environment interactions after unlearning. The replication package and agent parameters are available online.
Machine Unlearning of Pre-trained Large Language Models
Feb 27, 2024This study investigates the concept of the `right to be forgotten' within the context of large language models (LLMs). We explore machine unlearning as a pivotal solution, with a focus on pre-trained models--a notably under-researched area. Our research delineates a comprehensive framework for machine unlearning in pre-trained LLMs, encompassing a critical analysis of seven diverse unlearning methods. Through rigorous evaluation using curated datasets from arXiv, books, and GitHub, we establish a robust benchmark for unlearning performance, demonstrating that these methods are over $10^5$ times more computationally efficient than retraining. Our results show that integrating gradient ascent with gradient descent on in-distribution data improves hyperparameter robustness. We also provide detailed guidelines for efficient hyperparameter tuning in the unlearning process. Our findings advance the discourse on ethical AI practices, offering substantive insights into the mechanics of machine unlearning for pre-trained LLMs and underscoring the potential for responsible AI development.
Weakly Supervised Lesion Localization With Probabilistic-CAM Pooling
May 29, 2020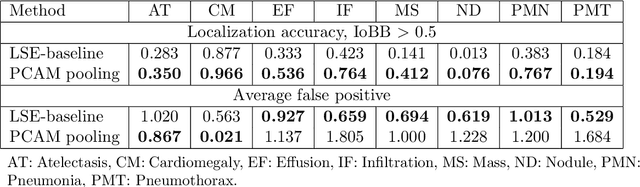
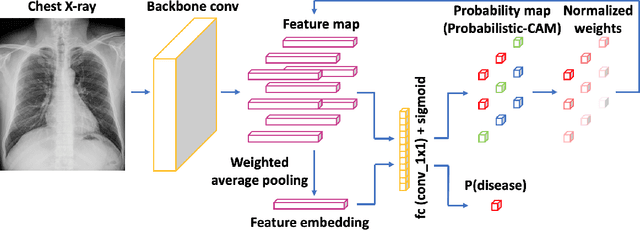
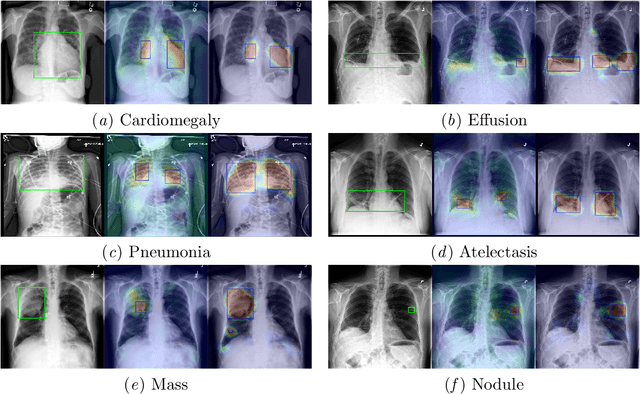
Localizing thoracic diseases on chest X-ray plays a critical role in clinical practices such as diagnosis and treatment planning. However, current deep learning based approaches often require strong supervision, e.g. annotated bounding boxes, for training such systems, which is infeasible to harvest in large-scale. We present Probabilistic Class Activation Map (PCAM) pooling, a novel global pooling operation for lesion localization with only image-level supervision. PCAM pooling explicitly leverages the excellent localization ability of CAM during training in a probabilistic fashion. Experiments on the ChestX-ray14 dataset show a ResNet-34 model trained with PCAM pooling outperforms state-of-the-art baselines on both the classification task and the localization task. Visual examination on the probability maps generated by PCAM pooling shows clear and sharp boundaries around lesion regions compared to the localization heatmaps generated by CAM. PCAM pooling is open sourced at https://github.com/jfhealthcare/Chexpert.