 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack for RGB-Event based Visual Object Tracking
Apr 19, 2025Visual object tracking is a crucial research topic in the fields of computer vision and multi-modal fusion. Among various approaches, robust visual tracking that combines RGB frames with Event streams has attracted increasing attention from researchers. While striving for high accuracy and efficiency in tracking, it is also important to explore how to effectively conduct adversarial attacks and defenses on RGB-Event stream tracking algorithms, yet research in this area remains relatively scarce. To bridge this gap, in this paper, we propose a cross-modal adversarial attack algorithm for RGB-Event visual tracking. Because of the diverse representations of Event streams, and given that Event voxels and frames are more commonly used, this paper will focus on these two representations for an in-depth study. Specifically, for the RGB-Event voxel, we first optimize the perturbation by adversarial loss to generate RGB frame adversarial examples. For discrete Event voxel representations, we propose a two-step attack strategy, more in detail, we first inject Event voxels into the target region as initialized adversarial examples, then, conduct a gradient-guided optimization by perturbing the spatial location of the Event voxels. For the RGB-Event frame based tracking, we optimize the cross-modal universal perturbation by integrating the gradient information from multimodal data. We evaluate the proposed approach against attacks on three widely used RGB-Event Tracking datasets, i.e., COESOT, FE108, and VisEvent. Extensive experiments show that our method significantly reduces the performance of the tracker across numerous datasets in both unimodal and multimodal scenarios. The source code will be released on https://github.com/Event-AHU/Adversarial_Attack_Defense
CM3AE: A Unified RGB Frame and Event-Voxel/-Frame Pre-training Framework
Apr 17, 2025Event cameras have attracted increasing attention in recent years due to their advantages in high dynamic range, high temporal resolution, low power consumption, and low latency. Some researchers have begun exploring pre-training directly on event data. Nevertheless, these efforts often fail to establish strong connections with RGB frames, limiting their applicability in multi-modal fusion scenarios. To address these issues, we propose a novel CM3AE pre-training framework for the RGB-Event perception. This framework accepts multi-modalities/views of data as input, including RGB images, event images, and event voxels, providing robust support for both event-based and RGB-event fusion based downstream tasks. Specifically, we design a multi-modal fusion reconstruction module that reconstructs the original image from fused multi-modal features, explicitly enhancing the model's ability to aggregate cross-modal complementary information. Additionally, we employ a multi-modal contrastive learning strategy to align cross-modal feature representations in a shared latent space, which effectively enhances the model's capability for multi-modal understanding and capturing global dependencies. We construct a large-scale dataset containing 2,535,759 RGB-Event data pairs for the pre-training. Extensive experiments on five downstream tasks fully demonstrated the effectiveness of CM3AE. Source code and pre-trained models will be released on https://github.com/Event-AHU/CM3AE.
Human Activity Recognition using RGB-Event based Sensors: A Multi-modal Heat Conduction Model and A Benchmark Dataset
Apr 08, 2025



Human Activity Recognition (HAR) primarily relied on traditional RGB cameras to achieve high-performance activity recognition. However, the challenging factors in real-world scenarios, such as insufficient lighting and rapid movements, inevitably degrade the performance of RGB cameras. To address these challenges, biologically inspired event cameras offer a promising solution to overcome the limitations of traditional RGB cameras. In this work, we rethink human activity recognition by combining the RGB and event cameras. The first contribution is the proposed large-scale multi-modal RGB-Event human activity recognition benchmark dataset, termed HARDVS 2.0, which bridges the dataset gaps. It contains 300 categories of everyday real-world actions with a total of 107,646 paired videos covering various challenging scenarios. Inspired by the physics-informed heat conduction model, we propose a novel multi-modal heat conduction operation framework for effective activity recognition, termed MMHCO-HAR. More in detail, given the RGB frames and event streams, we first extract the feature embeddings using a stem network. Then, multi-modal Heat Conduction blocks are designed to fuse the dual features, the key module of which is the multi-modal Heat Conduction Operation layer. We integrate RGB and event embeddings through a multi-modal DCT-IDCT layer while adaptively incorporating the thermal conductivity coefficient via FVEs into this module. After that, we propose an adaptive fusion module based on a policy routing strategy for high-performance classification. Comprehensive experiments demonstrate that our method consistently performs well, validating its effectiveness and robustness. The source code and benchmark dataset will be released on https://github.com/Event-AHU/HARDVS/tree/HARDVSv2
LEGNet: Lightweight Edge-Gaussian Driven Network for Low-Quality Remote Sensing Image Object Detection
Mar 18, 2025
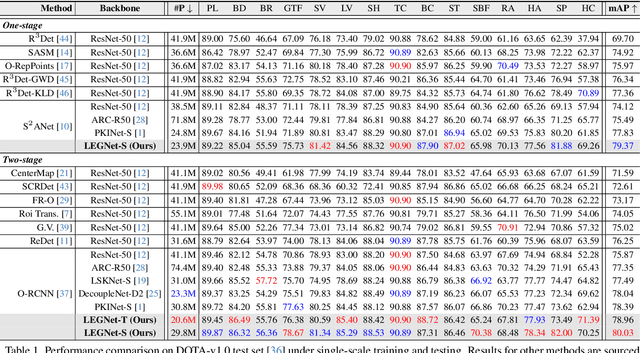
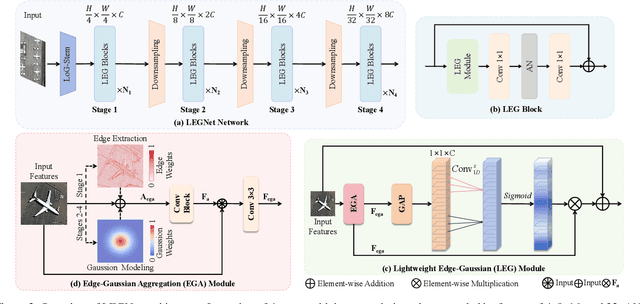
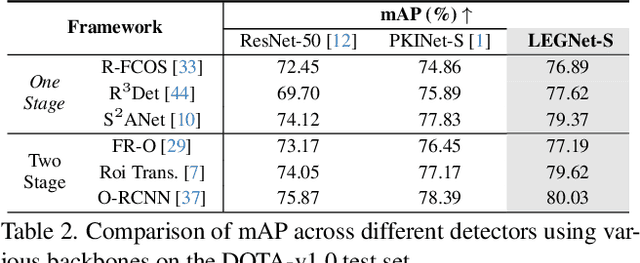
Remote sensing object detection (RSOD) faces formidable challenges in complex visual environments. Aerial and satellite images inherently suffer from limitations such as low spatial resolution, sensor noise, blurred objects, low-light degradation, and partial occlusions. These degradation factors collectively compromise the feature discriminability in detection models, resulting in three key issues: (1) reduced contrast that hampers foreground-background separation, (2) structural discontinuities in edge representations, and (3) ambiguous feature responses caused by variations in illumination. These collectively weaken model robustness and deployment feasibility. To address these challenges, we propose LEGNet, a lightweight network that incorporates a novel edge-Gaussian aggregation (EGA) module specifically designed for low-quality remote sensing images. Our key innovation lies in the synergistic integration of Scharr operator-based edge priors with uncertainty-aware Gaussian modeling: (a) The orientation-aware Scharr filters preserve high-frequency edge details with rotational invariance; (b) The uncertainty-aware Gaussian layers probabilistically refine low-confidence features through variance estimation. This design enables precision enhancement while maintaining architectural simplicity. Comprehensive evaluations across four RSOD benchmarks (DOTA-v1.0, v1.5, DIOR-R, FAIR1M-v1.0) and a UAV-view dataset (VisDrone2019) demonstrate significant improvements. LEGNet achieves state-of-the-art performance across five benchmark datasets while ensuring computational efficiency, making it well-suited for deployment on resource-constrained edge devices in real-world remote sensing applications. The code is available at https://github.com/lwCVer/LEGNet.
DehazeMamba: SAR-guided Optical Remote Sensing Image Dehazing with Adaptive State Space Model
Mar 17, 2025



Optical remote sensing image dehazing presents significant challenges due to its extensive spatial scale and highly non-uniform haze distribution, which traditional single-image dehazing methods struggle to address effectively. While Synthetic Aperture Radar (SAR) imagery offers inherently haze-free reference information for large-scale scenes, existing SAR-guided dehazing approaches face two critical limitations: the integration of SAR information often diminishes the quality of haze-free regions, and the instability of feature quality further exacerbates cross-modal domain shift. To overcome these challenges, we introduce DehazeMamba, a novel SAR-guided dehazing network built on a progressive haze decoupling fusion strategy. Our approach incorporates two key innovations: a Haze Perception and Decoupling Module (HPDM) that dynamically identifies haze-affected regions through optical-SAR difference analysis, and a Progressive Fusion Module (PFM) that mitigates domain shift through a two-stage fusion process based on feature quality assessment. To facilitate research in this domain, we present MRSHaze, a large-scale benchmark dataset comprising 8,000 pairs of temporally synchronized, precisely geo-registered SAR-optical images with high resolution and diverse haze conditions. Extensive experiments demonstrate that DehazeMamba significantly outperforms state-of-the-art methods, achieving a 0.73 dB improvement in PSNR and substantial enhancements in downstream tasks such as semantic segmentation. The dataset is available at https://github.com/mmic-lcl/Datasets-and-benchmark-code.
Breaking Shallow Limits: Task-Driven Pixel Fusion for Gap-free RGBT Tracking
Mar 14, 2025Current RGBT tracking methods often overlook the impact of fusion location on mitigating modality gap, which is key factor to effective tracking. Our analysis reveals that shallower fusion yields smaller distribution gap. However, the limited discriminative power of shallow networks hard to distinguish task-relevant information from noise, limiting the potential of pixel-level fusion. To break shallow limits, we propose a novel \textbf{T}ask-driven \textbf{P}ixel-level \textbf{F}usion network, named \textbf{TPF}, which unveils the power of pixel-level fusion in RGBT tracking through a progressive learning framework. In particular, we design a lightweight Pixel-level Fusion Adapter (PFA) that exploits Mamba's linear complexity to ensure real-time, low-latency RGBT tracking. To enhance the fusion capabilities of the PFA, our task-driven progressive learning framework first utilizes adaptive multi-expert distillation to inherits fusion knowledge from state-of-the-art image fusion models, establishing robust initialization, and then employs a decoupled representation learning scheme to achieve task-relevant information fusion. Moreover, to overcome appearance variations between the initial template and search frames, we presents a nearest-neighbor dynamic template updating scheme, which selects the most reliable frame closest to the current search frame as the dynamic template. Extensive experiments demonstrate that TPF significantly outperforms existing most of advanced trackers on four public RGBT tracking datasets. The code will be released upon acceptance.
Towards General Multimodal Visual Tracking
Mar 14, 2025



Existing multimodal tracking studies focus on bi-modal scenarios such as RGB-Thermal, RGB-Event, and RGB-Language. Although promising tracking performance is achieved through leveraging complementary cues from different sources, it remains challenging in complex scenes due to the limitations of bi-modal scenarios. In this work, we introduce a general multimodal visual tracking task that fully exploits the advantages of four modalities, including RGB, thermal infrared, event, and language, for robust tracking under challenging conditions. To provide a comprehensive evaluation platform for general multimodal visual tracking, we construct QuadTrack600, a large-scale, high-quality benchmark comprising 600 video sequences (totaling 384.7K high-resolution (640x480) frame groups). In each frame group, all four modalities are spatially aligned and meticulously annotated with bounding boxes, while 21 sequence-level challenge attributes are provided for detailed performance analysis. Despite quad-modal data provides richer information, the differences in information quantity among modalities and the computational burden from four modalities are two challenging issues in fusing four modalities. To handle these issues, we propose a novel approach called QuadFusion, which incorporates an efficient Multiscale Fusion Mamba with four different scanning scales to achieve sufficient interactions of the four modalities while overcoming the exponential computational burden, for general multimodal visual tracking. Extensive experiments on the QuadTrack600 dataset and three bi-modal tracking datasets, including LasHeR, VisEvent, and TNL2K, validate the effectiveness of our QuadFusion.
Text-RGBT Person Retrieval: Multilevel Global-Local Cross-Modal Alignment and A High-quality Benchmark
Mar 11, 2025The performance of traditional text-image person retrieval task is easily affected by lighting variations due to imaging limitations of visible spectrum sensors. In this work, we design a novel task called text-RGBT person retrieval that integrates complementary benefits from thermal and visible modalities for robust person retrieval in challenging environments. Aligning text and multi-modal visual representations is the key issue in text-RGBT person retrieval, but the heterogeneity between visible and thermal modalities may interfere with the alignment of visual and text modalities. To handle this problem, we propose a Multi-level Global-local cross-modal Alignment Network (MGANet), which sufficiently mines the relationships between modality-specific and modality-collaborative visual with the text, for text-RGBT person retrieval. To promote the research and development of this field, we create a high-quality text-RGBT person retrieval dataset, RGBT-PEDES. RGBT-PEDES contains 1,822 identities from different age groups and genders with 4,723 pairs of calibrated RGB and thermal images, and covers high-diverse scenes from both daytime and nighttime with a various of challenges such as occlusion, weak alignment and adverse lighting conditions. Additionally, we carefully annotate 7,987 fine-grained textual descriptions for all RGBT person image pairs. Extensive experiments on RGBT-PEDES demonstrate that our method outperforms existing text-image person retrieval methods. The code and dataset will be released upon the acceptance.
Sign Language Translation using Frame and Event Stream: Benchmark Dataset and Algorithms
Mar 09, 2025Accurate sign language understanding serves as a crucial communication channel for individuals with disabilities. Current sign language translation algorithms predominantly rely on RGB frames, which may be limited by fixed frame rates, variable lighting conditions, and motion blur caused by rapid hand movements. Inspired by the recent successful application of event cameras in other fields, we propose to leverage event streams to assist RGB cameras in capturing gesture data, addressing the various challenges mentioned above. Specifically, we first collect a large-scale RGB-Event sign language translation dataset using the DVS346 camera, termed VECSL, which contains 15,676 RGB-Event samples, 15,191 glosses, and covers 2,568 Chinese characters. These samples were gathered across a diverse range of indoor and outdoor environments, capturing multiple viewing angles, varying light intensities, and different camera motions. Due to the absence of benchmark algorithms for comparison in this new task, we retrained and evaluated multiple state-of-the-art SLT algorithms, and believe that this benchmark can effectively support subsequent related research. Additionally, we propose a novel RGB-Event sign language translation framework (i.e., M$^2$-SLT) that incorporates fine-grained micro-sign and coarse-grained macro-sign retrieval, achieving state-of-the-art results on the proposed dataset. Both the source code and dataset will be released on https://github.com/Event-AHU/OpenESL.
EventSTR: A Benchmark Dataset and Baselines for Event Stream based Scene Text Recognition
Feb 13, 2025Mainstream Scene Text Recognition (STR) algorithms are developed based on RGB cameras which are sensitive to challenging factors such as low illumination, motion blur, and cluttered backgrounds. In this paper, we propose to recognize the scene text using bio-inspired event cameras by collecting and annotating a large-scale benchmark dataset, termed EventSTR. It contains 9,928 high-definition (1280 * 720) event samples and involves both Chinese and English characters. We also benchmark multiple STR algorithms as the baselines for future works to compare. In addition, we propose a new event-based scene text recognition framework, termed SimC-ESTR. It first extracts the event features using a visual encoder and projects them into tokens using a Q-former module. More importantly, we propose to augment the vision tokens based on a memory mechanism before feeding into the large language models. A similarity-based error correction mechanism is embedded within the large language model to correct potential minor errors fundamentally based on contextual information. Extensive experiments on the newly proposed EventSTR dataset and two simulation STR datasets fully demonstrate the effectiveness of our proposed model. We believe that the dataset and algorithmic model can innovatively propose an event-based STR task and are expected to accelerate the application of event cameras in various industries. The source code and pre-trained models will be released on https://github.com/Event-AHU/EventSTR