 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Adversarial Robustness and Training Across Text Scoring Models
Jan 31, 2026Research on adversarial robustness in language models is currently fragmented across applications and attacks, obscuring shared vulnerabilities. In this work, we propose unifying the study of adversarial robustness in text scoring models spanning dense retrievers, rerankers, and reward models. This motivates adapting both attacks and adversarial training methods across model roles. Unlike open-ended generation, text scoring failures are directly testable: an attack succeeds when an irrelevant or rejected text outscores a relevant or chosen one. Using this principled lens of text scoring, we demonstrate that current adversarial training formulations for language models are often short-sighted, failing to effectively generalize across attacks. To address this, we introduce multiple adversarial training methods for text scoring models and show that combining complementary training methods can yield strong robustness while also improving task effectiveness. We also highlight the practical value of our approach for RLHF, showing that our adversarially trained reward models mitigate reward hacking and support the training of better-aligned LLMs. We provide our code and models for further study.
Rerank Before You Reason: Analyzing Reranking Tradeoffs through Effective Token Cost in Deep Search Agents
Jan 20, 2026Deep research agents rely on iterative retrieval and reasoning to answer complex queries, but scaling test-time computation raises significant efficiency concerns. We study how to allocate reasoning budget in deep search pipelines, focusing on the role of listwise reranking. Using the BrowseComp-Plus benchmark, we analyze tradeoffs between model scale, reasoning effort, reranking depth, and total token cost via a novel effective token cost (ETC) metric. Our results show that reranking consistently improves retrieval and end-to-end accuracy, and that moderate reranking often yields larger gains than increasing search-time reasoning, achieving comparable accuracy at substantially lower cost. All our code is available at https://github.com/texttron/BrowseComp-Plus.git
LACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
Study on LLMs for Promptagator-Style Dense Retriever Training
Oct 02, 2025Promptagator demonstrated that Large Language Models (LLMs) with few-shot prompts can be used as task-specific query generators for fine-tuning domain-specialized dense retrieval models. However, the original Promptagator approach relied on proprietary and large-scale LLMs which users may not have access to or may be prohibited from using with sensitive data. In this work, we study the impact of open-source LLMs at accessible scales ($\leq$14B parameters) as an alternative. Our results demonstrate that open-source LLMs as small as 3B parameters can serve as effective Promptagator-style query generators. We hope our work will inform practitioners with reliable alternatives for synthetic data generation and give insights to maximize fine-tuning results for domain-specific applications.
MAGMaR Shared Task System Description: Video Retrieval with OmniEmbed
Jun 11, 2025


Effective video retrieval remains challenging due to the complexity of integrating visual, auditory, and textual modalities. In this paper, we explore unified retrieval methods using OmniEmbed, a powerful multimodal embedding model from the Tevatron 2.0 toolkit, in the context of the MAGMaR shared task. Evaluated on the comprehensive MultiVENT 2.0 dataset, OmniEmbed generates unified embeddings for text, images, audio, and video, enabling robust multimodal retrieval. By finetuning OmniEmbed with the combined multimodal data--visual frames, audio tracks, and textual descriptions provided in MultiVENT 2.0, we achieve substantial improvements in complex, multilingual video retrieval tasks. Our submission achieved the highest score on the MAGMaR shared task leaderboard among public submissions as of May 20th, 2025, highlighting the practical effectiveness of our unified multimodal retrieval approach. Model checkpoint in this work is opensourced.
On the Comprehensibility of Multi-structured Financial Documents using LLMs and Pre-processing Tools
Jun 05, 2025



The proliferation of complex structured data in hybrid sources, such as PDF documents and web pages, presents unique challenges for current Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) in providing accurate answers. Despite the recent advancements of MLLMs, they still often falter when interpreting intricately structured information, such as nested tables and multi-dimensional plots, leading to hallucinations and erroneous outputs. This paper explores the capabilities of LLMs and MLLMs in understanding and answering questions from complex data structures found in PDF documents by leveraging industrial and open-source tools as part of a pre-processing pipeline. Our findings indicate that GPT-4o, a popular MLLM, achieves an accuracy of 56% on multi-structured documents when fed documents directly, and that integrating pre-processing tools raises the accuracy of LLMs to 61.3% for GPT-4o and 76% for GPT-4, and with lower overall cost. The code is publicly available at https://github.com/OGCDS/FinancialQA.
Improving Multilingual Math Reasoning for African Languages
May 26, 2025



Researchers working on low-resource languages face persistent challenges due to limited data availability and restricted access to computational resources. Although most large language models (LLMs) are predominantly trained in high-resource languages, adapting them to low-resource contexts, particularly African languages, requires specialized techniques. Several strategies have emerged for adapting models to low-resource languages in todays LLM landscape, defined by multi-stage pre-training and post-training paradigms. However, the most effective approaches remain uncertain. This work systematically investigates which adaptation strategies yield the best performance when extending existing LLMs to African languages. We conduct extensive experiments and ablation studies to evaluate different combinations of data types (translated versus synthetically generated), training stages (pre-training versus post-training), and other model adaptation configurations. Our experiments focuses on mathematical reasoning tasks, using the Llama 3.1 model family as our base model.
Conventional Contrastive Learning Often Falls Short: Improving Dense Retrieval with Cross-Encoder Listwise Distillation and Synthetic Data
May 25, 2025We investigate improving the retrieval effectiveness of embedding models through the lens of corpus-specific fine-tuning. Prior work has shown that fine-tuning with queries generated using a dataset's retrieval corpus can boost retrieval effectiveness for the dataset. However, we find that surprisingly, fine-tuning using the conventional InfoNCE contrastive loss often reduces effectiveness in state-of-the-art models. To overcome this, we revisit cross-encoder listwise distillation and demonstrate that, unlike using contrastive learning alone, listwise distillation can help more consistently improve retrieval effectiveness across multiple datasets. Additionally, we show that synthesizing more training data using diverse query types (such as claims, keywords, and questions) yields greater effectiveness than using any single query type alone, regardless of the query type used in evaluation. Our findings further indicate that synthetic queries offer comparable utility to human-written queries for training. We use our approach to train an embedding model that achieves state-of-the-art effectiveness among BERT embedding models. We release our model and both query generation and training code to facilitate further research.
RankLLM: A Python Package for Reranking with LLMs
May 25, 2025
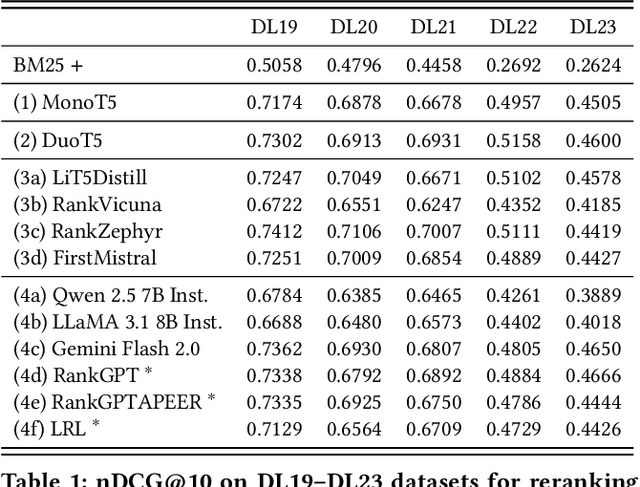


The adoption of large language models (LLMs) as rerankers in multi-stage retrieval systems has gained significant traction in academia and industry. These models refine a candidate list of retrieved documents, often through carefully designed prompts, and are typically used in applications built on retrieval-augmented generation (RAG). This paper introduces RankLLM, an open-source Python package for reranking that is modular, highly configurable, and supports both proprietary and open-source LLMs in customized reranking workflows. To improve usability, RankLLM features optional integration with Pyserini for retrieval and provides integrated evaluation for multi-stage pipelines. Additionally, RankLLM includes a module for detailed analysis of input prompts and LLM responses, addressing reliability concerns with LLM APIs and non-deterministic behavior in Mixture-of-Experts (MoE) models. This paper presents the architecture of RankLLM, along with a detailed step-by-step guide and sample code. We reproduce results from RankGPT, LRL, RankVicuna, RankZephyr, and other recent models. RankLLM integrates with common inference frameworks and a wide range of LLMs. This compatibility allows for quick reproduction of reported results, helping to speed up both research and real-world applications. The complete repository is available at rankllm.ai, and the package can be installed via PyPI.
Fixing Data That Hurts Performance: Cascading LLMs to Relabel Hard Negatives for Robust Information Retrieval
May 22, 2025



Training robust retrieval and reranker models typically relies on large-scale retrieval datasets; for example, the BGE collection contains 1.6 million query-passage pairs sourced from various data sources. However, we find that certain datasets can negatively impact model effectiveness -- pruning 8 out of 15 datasets from the BGE collection reduces the training set size by 2.35$\times$ and increases nDCG@10 on BEIR by 1.0 point. This motivates a deeper examination of training data quality, with a particular focus on "false negatives", where relevant passages are incorrectly labeled as irrelevant. We propose a simple, cost-effective approach using cascading LLM prompts to identify and relabel hard negatives. Experimental results show that relabeling false negatives with true positives improves both E5 (base) and Qwen2.5-7B retrieval models by 0.7-1.4 nDCG@10 on BEIR and by 1.7-1.8 nDCG@10 on zero-shot AIR-Bench evaluation. Similar gains are observed for rerankers fine-tuned on the relabeled data, such as Qwen2.5-3B on BEIR. The reliability of the cascading design is further supported by human annotation results, where we find judgment by GPT-4o shows much higher agreement with humans than GPT-4o-mini.