 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation
May 03, 2022
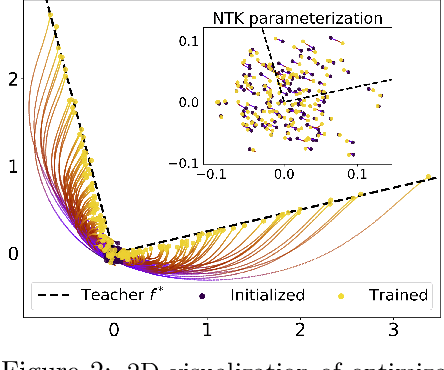
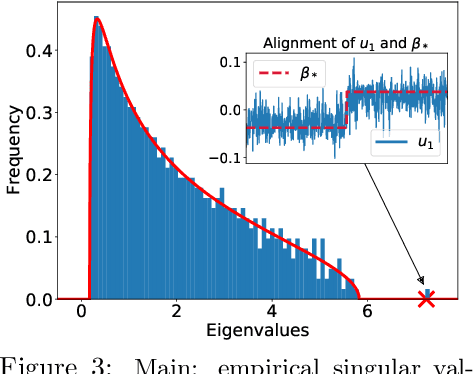
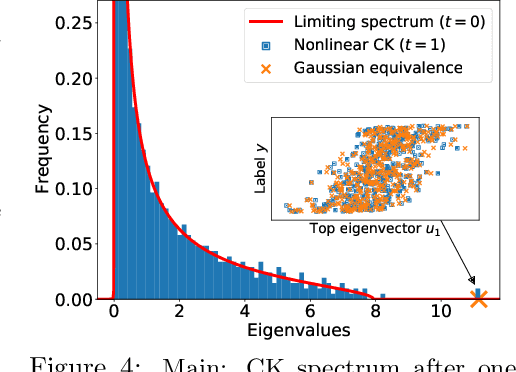
We study the first gradient descent step on the first-layer parameters $\boldsymbol{W}$ in a two-layer neural network: $f(\boldsymbol{x}) = \frac{1}{\sqrt{N}}\boldsymbol{a}^\top\sigma(\boldsymbol{W}^\top\boldsymbol{x})$, where $\boldsymbol{W}\in\mathbb{R}^{d\times N}, \boldsymbol{a}\in\mathbb{R}^{N}$ are randomly initialized, and the training objective is the empirical MSE loss: $\frac{1}{n}\sum_{i=1}^n (f(\boldsymbol{x}_i)-y_i)^2$. In the proportional asymptotic limit where $n,d,N\to\infty$ at the same rate, and an idealized student-teacher setting, we show that the first gradient update contains a rank-1 "spike", which results in an alignment between the first-layer weights and the linear component of the teacher model $f^*$. To characterize the impact of this alignment, we compute the prediction risk of ridge regression on the conjugate kernel after one gradient step on $\boldsymbol{W}$ with learning rate $\eta$, when $f^*$ is a single-index model. We consider two scalings of the first step learning rate $\eta$. For small $\eta$, we establish a Gaussian equivalence property for the trained feature map, and prove that the learned kernel improves upon the initial random features model, but cannot defeat the best linear model on the input. Whereas for sufficiently large $\eta$, we prove that for certain $f^*$, the same ridge estimator on trained features can go beyond this "linear regime" and outperform a wide range of random features and rotationally invariant kernels. Our results demonstrate that even one gradient step can lead to a considerable advantage over random features, and highlight the role of learning rate scaling in the initial phase of training.
Learning Domain Invariant Representations in Goal-conditioned Block MDPs
Oct 28, 2021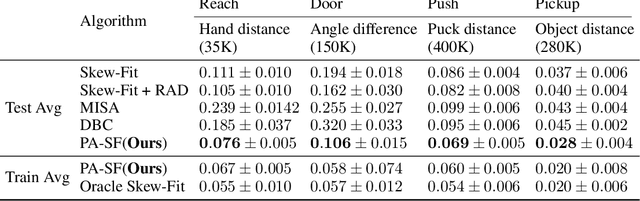
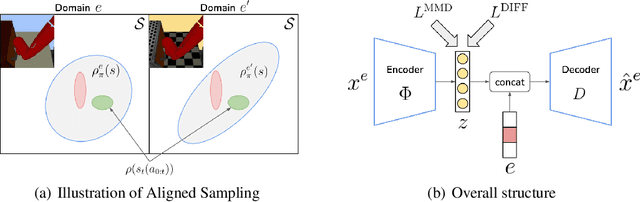

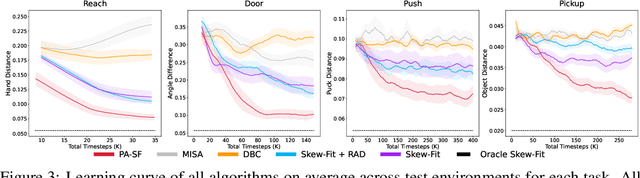
Deep Reinforcement Learning (RL) is successful in solving many complex Markov Decision Processes (MDPs) problems. However, agents often face unanticipated environmental changes after deployment in the real world. These changes are often spurious and unrelated to the underlying problem, such as background shifts for visual input agents. Unfortunately, deep RL policies are usually sensitive to these changes and fail to act robustly against them. This resembles the problem of domain generalization in supervised learning. In this work, we study this problem for goal-conditioned RL agents. We propose a theoretical framework in the Block MDP setting that characterizes the generalizability of goal-conditioned policies to new environments. Under this framework, we develop a practical method PA-SkewFit that enhances domain generalization. The empirical evaluation shows that our goal-conditioned RL agent can perform well in various unseen test environments, improving by 50% over baselines.
* 33 pages
Clockwork Variational Autoencoders
Feb 20, 2021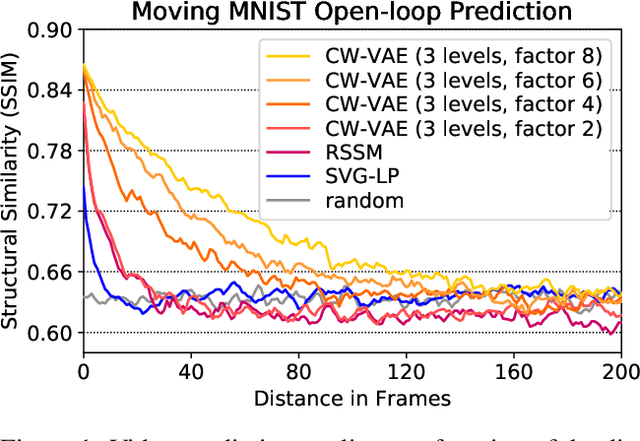
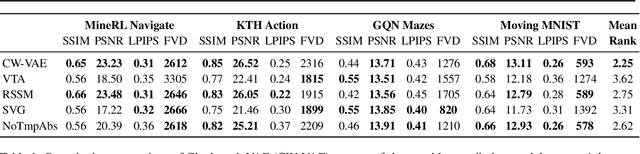
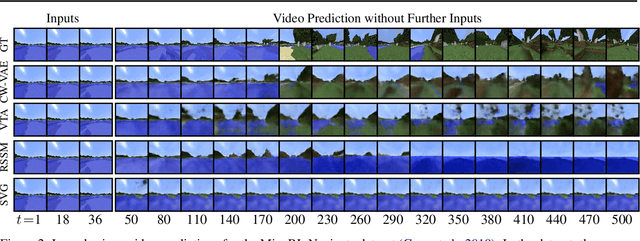
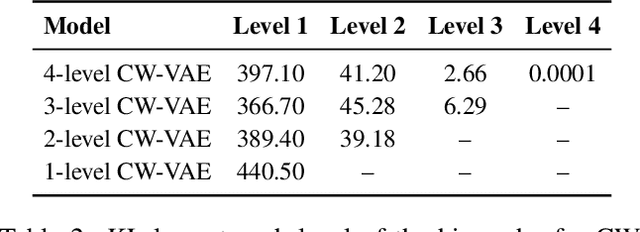
Deep learning has enabled algorithms to generate realistic images. However, accurately predicting long video sequences requires understanding long-term dependencies and remains an open challenge. While existing video prediction models succeed at generating sharp images, they tend to fail at accurately predicting far into the future. We introduce the Clockwork VAE (CW-VAE), a video prediction model that leverages a hierarchy of latent sequences, where higher levels tick at slower intervals. We demonstrate the benefits of both hierarchical latents and temporal abstraction on 4 diverse video prediction datasets with sequences of up to 1000 frames, where CW-VAE outperforms top video prediction models. Additionally, we propose a Minecraft benchmark for long-term video prediction. We conduct several experiments to gain insights into CW-VAE and confirm that slower levels learn to represent objects that change more slowly in the video, and faster levels learn to represent faster objects.
LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning
Jan 15, 2021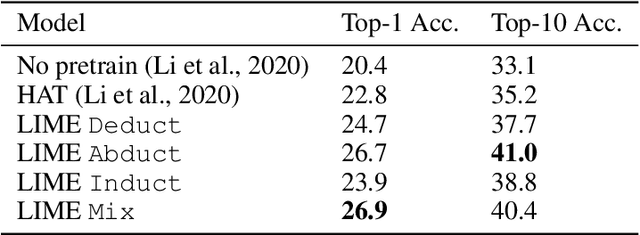
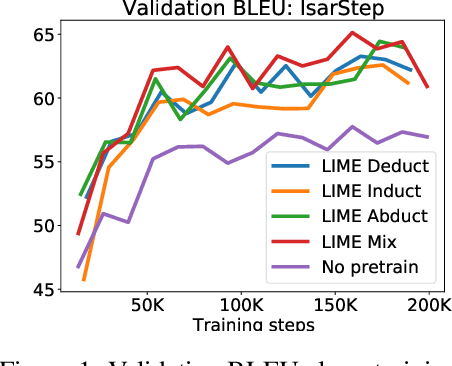

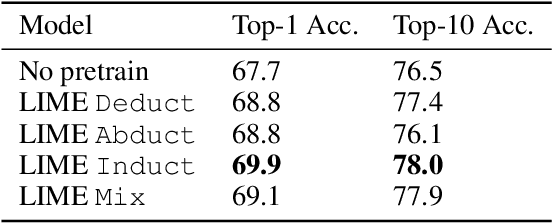
While designing inductive bias in neural architectures has been widely studied, we hypothesize that transformer networks are flexible enough to learn inductive bias from suitable generic tasks. Here, we replace architecture engineering by encoding inductive bias in the form of datasets. Inspired by Peirce's view that deduction, induction, and abduction form an irreducible set of reasoning primitives, we design three synthetic tasks that are intended to require the model to have these three abilities. We specifically design these synthetic tasks in a way that they are devoid of mathematical knowledge to ensure that only the fundamental reasoning biases can be learned from these tasks. This defines a new pre-training methodology called "LIME" (Learning Inductive bias for Mathematical rEasoning). Models trained with LIME significantly outperform vanilla transformers on three very different large mathematical reasoning benchmarks. Unlike dominating the computation cost as traditional pre-training approaches, LIME requires only a small fraction of the computation cost of the typical downstream task.
Noisy Labels Can Induce Good Representations
Dec 23, 2020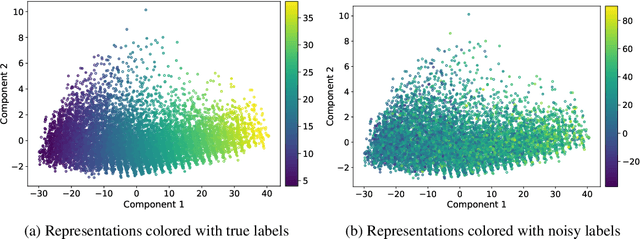

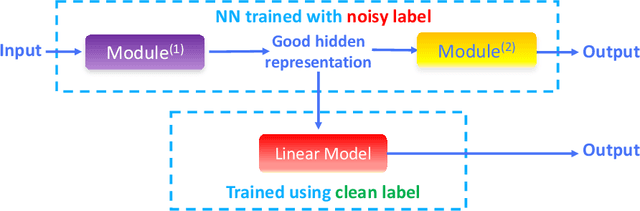
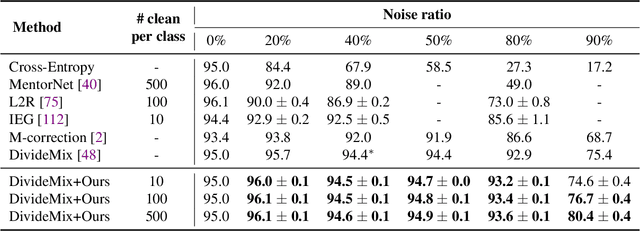
The current success of deep learning depends on large-scale labeled datasets. In practice, high-quality annotations are expensive to collect, but noisy annotations are more affordable. Previous works report mixed empirical results when training with noisy labels: neural networks can easily memorize random labels, but they can also generalize from noisy labels. To explain this puzzle, we study how architecture affects learning with noisy labels. We observe that if an architecture "suits" the task, training with noisy labels can induce useful hidden representations, even when the model generalizes poorly; i.e., the last few layers of the model are more negatively affected by noisy labels. This finding leads to a simple method to improve models trained on noisy labels: replacing the final dense layers with a linear model, whose weights are learned from a small set of clean data. We empirically validate our findings across three architectures (Convolutional Neural Networks, Graph Neural Networks, and Multi-Layer Perceptrons) and two domains (graph algorithmic tasks and image classification). Furthermore, we achieve state-of-the-art results on image classification benchmarks by combining our method with existing approaches on noisy label training.
Evaluating Agents without Rewards
Dec 21, 2020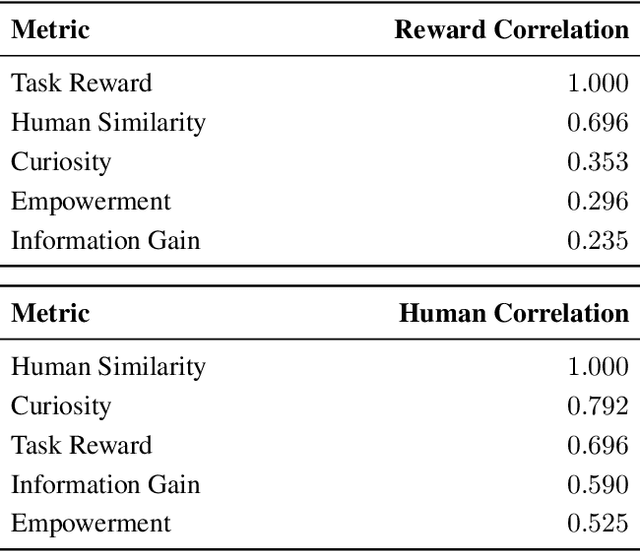
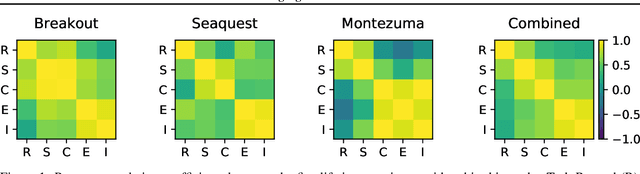
Reinforcement learning has enabled agents to solve challenging tasks in unknown environments. However, manually crafting reward functions can be time consuming, expensive, and error prone to human error. Competing objectives have been proposed for agents to learn without external supervision, but it has been unclear how well they reflect task rewards or human behavior. To accelerate the development of intrinsic objectives, we retrospectively compute potential objectives on pre-collected datasets of agent behavior, rather than optimizing them online, and compare them by analyzing their correlations. We study input entropy, information gain, and empowerment across seven agents, three Atari games, and the 3D game Minecraft. We find that all three intrinsic objectives correlate more strongly with a human behavior similarity metric than with task reward. Moreover, input entropy and information gain correlate more strongly with human similarity than task reward does, suggesting the use of intrinsic objectives for designing agents that behave similarly to human players.
Planning from Pixels using Inverse Dynamics Models
Dec 04, 2020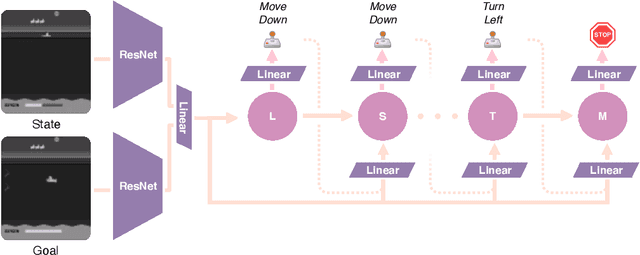
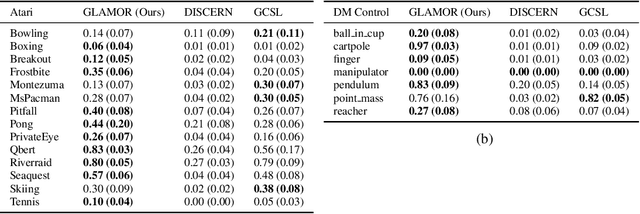
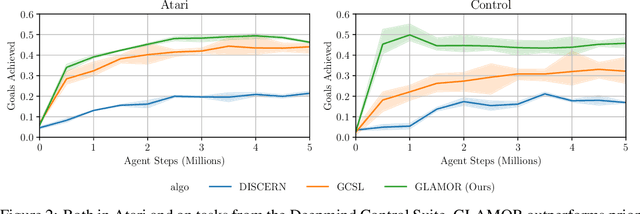
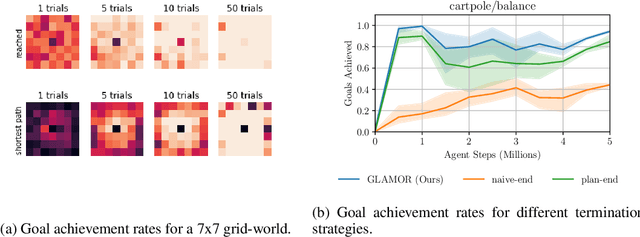
Learning task-agnostic dynamics models in high-dimensional observation spaces can be challenging for model-based RL agents. We propose a novel way to learn latent world models by learning to predict sequences of future actions conditioned on task completion. These task-conditioned models adaptively focus modeling capacity on task-relevant dynamics, while simultaneously serving as an effective heuristic for planning with sparse rewards. We evaluate our method on challenging visual goal completion tasks and show a substantial increase in performance compared to prior model-free approaches.
Mastering Atari with Discrete World Models
Oct 05, 2020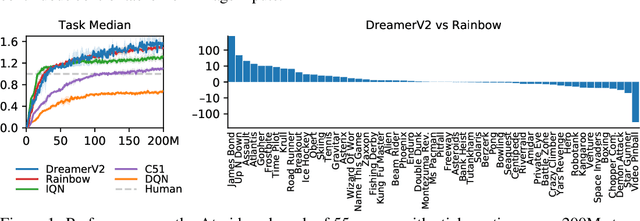
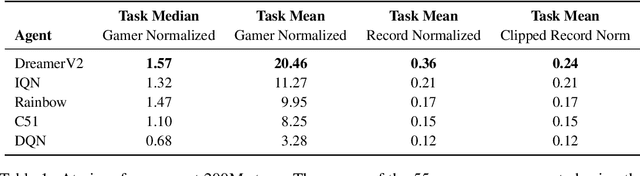
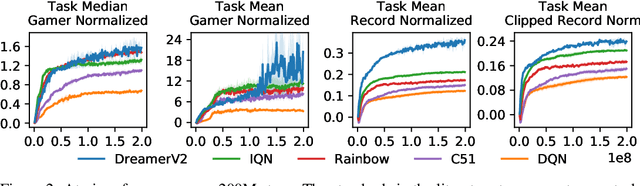

Intelligent agents need to generalize from past experience to achieve goals in complex environments. World models facilitate such generalization and allow learning behaviors from imagined outcomes to increase sample-efficiency. While learning world models from image inputs has recently become feasible for some tasks, modeling Atari games accurately enough to derive successful behaviors has remained an open challenge for many years. We introduce DreamerV2, a reinforcement learning agent that learns behaviors purely from predictions in the compact latent space of a powerful world model. The world model uses discrete representations and is trained separately from the policy. DreamerV2 constitutes the first agent that achieves human-level performance on the Atari benchmark of 55 tasks by learning behaviors inside a separately trained world model. With the same computational budget and wall-clock time, DreamerV2 reaches 200M frames and exceeds the final performance of the top single-GPU agents IQN and Rainbow.
Action and Perception as Divergence Minimization
Oct 05, 2020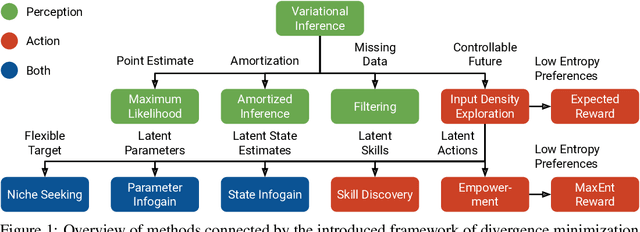
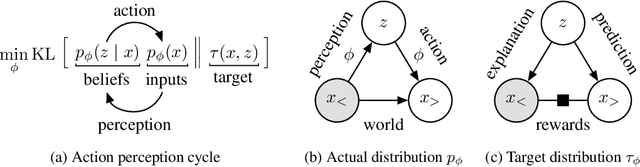
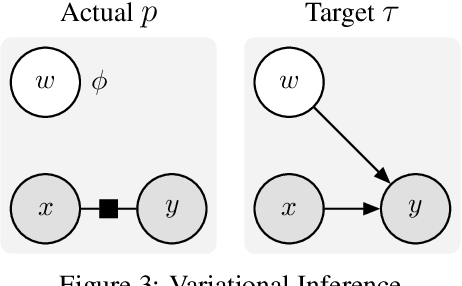
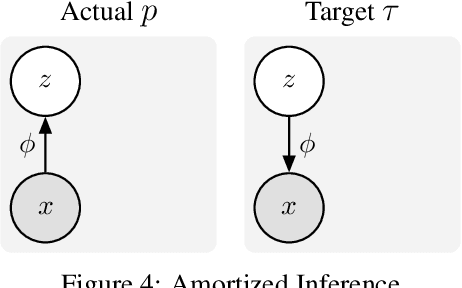
We introduce a unified objective for action and perception of intelligent agents. Extending representation learning and control, we minimize the joint divergence between the combined system of agent and environment and a target distribution. Intuitively, such agents use perception to align their beliefs with the world, and use actions to align the world with their beliefs. Minimizing the joint divergence to an expressive target maximizes the mutual information between the agent's representations and inputs, thus inferring representations that are informative of past inputs and exploring future inputs that are informative of the representations. This lets us explain intrinsic objectives, such as representation learning, information gain, empowerment, and skill discovery from minimal assumptions. Moreover, interpreting the target distribution as a latent variable model suggests powerful world models as a path toward highly adaptive agents that seek large niches in their environments, rendering task rewards optional. The framework provides a common language for comparing a wide range of objectives, advances the understanding of latent variables for decision making, and offers a recipe for designing novel objectives. We recommend deriving future agent objectives the joint divergence to facilitate comparison, to point out the agent's target distribution, and to identify the intrinsic objective terms needed to reach that distribution.
A Study of Gradient Variance in Deep Learning
Jul 09, 2020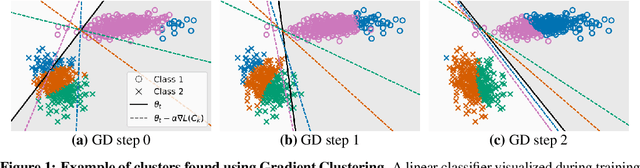


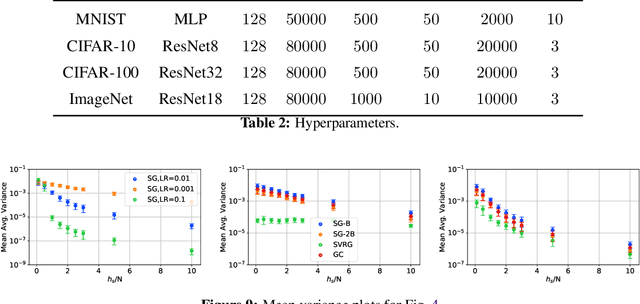
The impact of gradient noise on training deep models is widely acknowledged but not well understood. In this context, we study the distribution of gradients during training. We introduce a method, Gradient Clustering, to minimize the variance of average mini-batch gradient with stratified sampling. We prove that the variance of average mini-batch gradient is minimized if the elements are sampled from a weighted clustering in the gradient space. We measure the gradient variance on common deep learning benchmarks and observe that, contrary to common assumptions, gradient variance increases during training, and smaller learning rates coincide with higher variance. In addition, we introduce normalized gradient variance as a statistic that better correlates with the speed of convergence compared to gradient variance.