 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDementia-R1: Reinforced Pretraining and Reasoning from Unstructured Clinical Notes for Real-World Dementia Prognosis
Jan 06, 2026While Large Language Models (LLMs) have shown strong performance on clinical text understanding, they struggle with longitudinal prediction tasks such as dementia prognosis, which require reasoning over complex, non-monotonic symptom trajectories across multiple visits. Standard supervised training lacks explicit annotations for symptom evolution, while direct Reinforcement Learning (RL) is hindered by sparse binary rewards. To address this challenge, we introduce Dementia-R1, an RL-based framework for longitudinal dementia prognosis from unstructured clinical notes. Our approach adopts a Cold-Start RL strategy that pre-trains the model to predict verifiable clinical indices extracted from patient histories, enhancing the capability to reason about disease progression before determining the final clinical status. Extensive experiments demonstrate that Dementia-R1 achieves an F1 score of 77.03% on real-world unstructured clinical datasets. Notably, on the ADNI benchmark, our 7B model rivals GPT-4o, effectively capturing fluctuating cognitive trajectories. Code is available at https://anonymous.4open.science/r/dementiar1-CDB5
Universal Reasoner: A Single, Composable Plug-and-Play Reasoner for Frozen LLMs
May 25, 2025



Large Language Models (LLMs) have demonstrated remarkable general capabilities, but enhancing skills such as reasoning often demands substantial computational resources and may compromise their generalization. While Parameter-Efficient Fine-Tuning (PEFT) methods offer a more resource-conscious alternative, they typically requires retraining for each LLM backbone due to architectural dependencies. To address these challenges, here we propose Universal Reasoner (UniR) - a single, lightweight, composable, and plug-and-play reasoning module that can be used with any frozen LLM to endow it with specialized reasoning capabilities. Specifically, UniR decomposes the reward into a standalone reasoning module that is trained independently using predefined rewards, effectively translating trajectory-level signals into token-level guidance. Once trained, UniR can be combined with any frozen LLM at inference time by simply adding its output logits to those of the LLM backbone. This additive structure naturally enables modular composition: multiple UniR modules trained for different tasks can be jointly applied by summing their logits, enabling complex reasoning via composition. Experimental results on mathematical reasoning and machine translation tasks show that UniR significantly outperforms \add{existing baseline fine-tuning methods using the Llama3.2 model}. Furthermore, UniR demonstrates strong weak-to-strong generalization: reasoning modules trained on smaller models effectively guide much larger LLMs. This makes UniR a cost-efficient, adaptable, and robust solution for enhancing reasoning in LLMs without compromising their core capabilities. Code is open-sourced at https://github.com/hangeol/UniR
Simplifying Multimodality: Unimodal Approach to Multimodal Challenges in Radiology with General-Domain Large Language Model
Apr 29, 2024



Recent advancements in Large Multimodal Models (LMMs) have attracted interest in their generalization capability with only a few samples in the prompt. This progress is particularly relevant to the medical domain, where the quality and sensitivity of data pose unique challenges for model training and application. However, the dependency on high-quality data for effective in-context learning raises questions about the feasibility of these models when encountering with the inevitable variations and errors inherent in real-world medical data. In this paper, we introduce MID-M, a novel framework that leverages the in-context learning capabilities of a general-domain Large Language Model (LLM) to process multimodal data via image descriptions. MID-M achieves a comparable or superior performance to task-specific fine-tuned LMMs and other general-domain ones, without the extensive domain-specific training or pre-training on multimodal data, with significantly fewer parameters. This highlights the potential of leveraging general-domain LLMs for domain-specific tasks and offers a sustainable and cost-effective alternative to traditional LMM developments. Moreover, the robustness of MID-M against data quality issues demonstrates its practical utility in real-world medical domain applications.
High Recall Data-to-text Generation with Progressive Edit
Aug 09, 2022

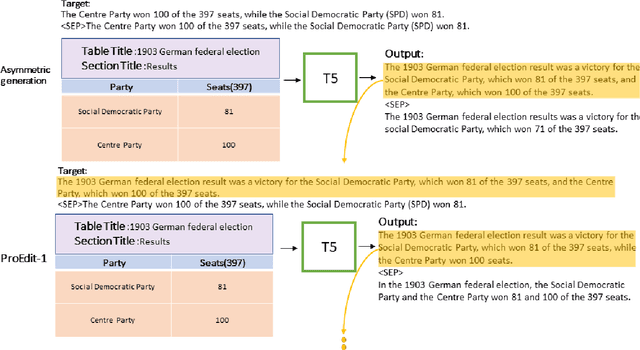

Data-to-text (D2T) generation is the task of generating texts from structured inputs. We observed that when the same target sentence was repeated twice, Transformer (T5) based model generates an output made up of asymmetric sentences from structured inputs. In other words, these sentences were different in length and quality. We call this phenomenon "Asymmetric Generation" and we exploit this in D2T generation. Once asymmetric sentences are generated, we add the first part of the output with a no-repeated-target. As this goes through progressive edit (ProEdit), the recall increases. Hence, this method better covers structured inputs than before editing. ProEdit is a simple but effective way to improve performance in D2T generation and it achieves the new stateof-the-art result on the ToTTo dataset