 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Guided Semantic Alignment for Feature Fusion Networks
Jun 12, 2026Feature fusion networks are fundamental components in modern object detectors, aggregating multi-scale features to detect objects of varying sizes. However, directly fusing features from different pyramid levels often introduces semantic inconsistency due to their heterogeneous representations. In this paper, we propose Feature Interaction NEtwork (FINE), a lightweight semantic alignment module that refines low-level features via high-level contextual guidance using cross-level attention prior to fusion. To bridge the structural gap and ensure computational efficiency, we introduce an Alignment-Aware Token Sampling that aligns corresponding spatial regions across scales, reducing the attention complexity by an order of magnitude. The resulting attention weights generate a spatial-channel modulation map that is upsampled and applied to the low-level features via residual element-wise modulation. This mechanism ensures that the network selectively enhances semantically relevant pixels while preserving the sub-pixel localization accuracy necessary for dense prediction tasks. FINE is generally applicable to various detectors and consistently improves detection accuracy without compromising efficiency.
AnyDepth-DETR/-YOLO: Any-depth object detection with a single network
May 10, 2026Modern object detectors are static, fixed-depth networks optimized for a single operating point, requiring separate models for different deployment scenarios. We present an any-depth detection framework that enables a single network to span a continuous range of accuracy--efficiency trade-offs by controlling depth at inference time without retraining. Each backbone and neck stage is divided into an essential path, which always executes, and a skippable refinement path; this decomposition preserves the full multi-scale feature hierarchy at every depth configuration, unlike conventional early exiting that discards entire stages. To train such a network, jointly optimizing many sub-networks of varying depth introduces conflicting gradient signals. We address this via self-distillation between only the two extremes, with prediction-level and feature-level alignment losses that enforce stage-wise modularity, ensuring the outputs of each stage remain compatible regardless of the paths taken. Instantiated on RT-DETR and YOLOv12, our full-depth configurations match or surpass their respective SOTA baselines with negligible parameter overhead, while the most efficient configurations achieve up to $1.82\times$ speedup at a cost of only 2.0 AP, all from a single set of weights.
Adaptive Depth Networks with Skippable Sub-Paths
Dec 27, 2023



Systematic adaptation of network depths at runtime can be an effective way to control inference latency and meet the resource condition of various devices. However, previous depth adaptive networks do not provide general principles and a formal explanation on why and which layers can be skipped, and, hence, their approaches are hard to be generalized and require long and complex training steps. In this paper, we present an architectural pattern and training method for adaptive depth networks that can provide flexible accuracy-efficiency trade-offs in a single network. In our approach, every residual stage is divided into 2 consecutive sub-paths with different properties. While the first sub-path is mandatory for hierarchical feature learning, the other is optimized to incur minimal performance degradation even if it is skipped. Unlike previous adaptive networks, our approach does not iteratively self-distill a fixed set of sub-networks, resulting in significantly shorter training time. However, once deployed on devices, it can instantly construct sub-networks of varying depths to provide various accuracy-efficiency trade-offs in a single model. We provide a formal rationale for why the proposed architectural pattern and training method can reduce overall prediction errors while minimizing the impact of skipping selected sub-paths. We also demonstrate the generality and effectiveness of our approach with various residual networks, both from convolutional neural networks and vision transformers.
Learning Shared Filter Bases for Efficient ConvNets
Jul 01, 2020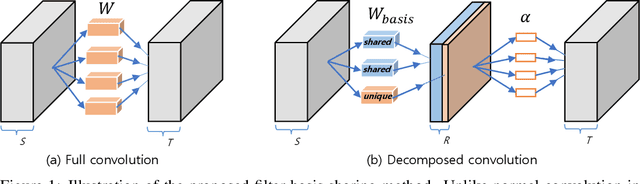

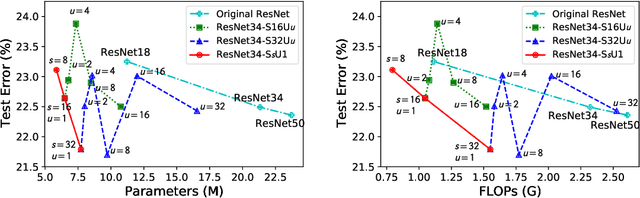
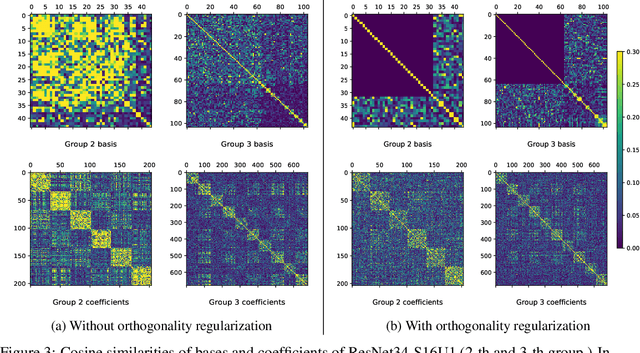
Modern convolutional neural networks (ConvNets) achieve state-of-the-art performance for many computer vision tasks. However, such high performance requires millions of parameters and high computational costs. Recently, inspired by the iterative structure of modern ConvNets, such as ResNets, parameter sharing among repetitive convolution layers has been proposed to reduce the size of parameters. However, naive sharing of convolution filters poses many challenges such as overfitting and vanishing/exploding gradients. Furthermore, parameter sharing often increases computational complexity due to additional operations. In this paper, we propose to exploit the linear structure of convolution filters for effective and efficient sharing of parameters among iterative convolution layers. Instead of sharing convolution filters themselves, we hypothesize that a filter basis of linearly-decomposed convolution layers is a more effective unit for sharing parameters since a filter basis is an intrinsic and reusable building block constituting diverse high dimensional convolution filters. The representation power and peculiarity of individual convolution layers are further increased by adding a small number of layer-specific non-shared components to the filter basis. We show empirically that enforcing orthogonality to shared filter bases can mitigate the difficulty in training shared parameters. Experimental results show that our approach achieves significant reductions both in model parameters and computational costs while maintaining competitive, and often better, performance than non-shared baseline networks.