 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA Family: Boosting Weight-Sharing NAS with Block-Wise Supervisions
Mar 02, 2024



Neural Architecture Search (NAS), aiming at automatically designing neural architectures by machines, has been considered a key step toward automatic machine learning. One notable NAS branch is the weight-sharing NAS, which significantly improves search efficiency and allows NAS algorithms to run on ordinary computers. Despite receiving high expectations, this category of methods suffers from low search effectiveness. By employing a generalization boundedness tool, we demonstrate that the devil behind this drawback is the untrustworthy architecture rating with the oversized search space of the possible architectures. Addressing this problem, we modularize a large search space into blocks with small search spaces and develop a family of models with the distilling neural architecture (DNA) techniques. These proposed models, namely a DNA family, are capable of resolving multiple dilemmas of the weight-sharing NAS, such as scalability, efficiency, and multi-modal compatibility. Our proposed DNA models can rate all architecture candidates, as opposed to previous works that can only access a subsearch space using heuristic algorithms. Moreover, under a certain computational complexity constraint, our method can seek architectures with different depths and widths. Extensive experimental evaluations show that our models achieve state-of-the-art top-1 accuracy of 78.9% and 83.6% on ImageNet for a mobile convolutional network and a small vision transformer, respectively. Additionally, we provide in-depth empirical analysis and insights into neural architecture ratings. Codes available: \url{https://github.com/changlin31/DNA}.
EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation
Sep 16, 2021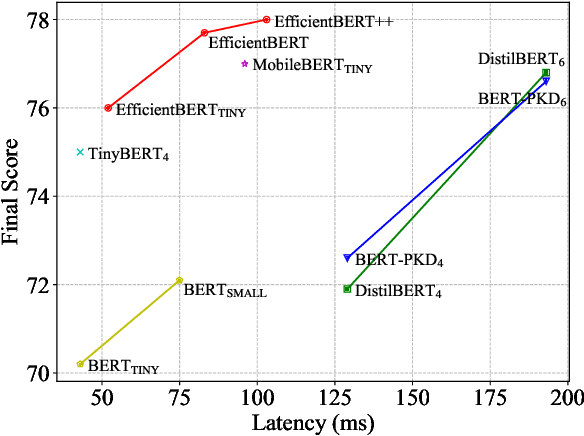

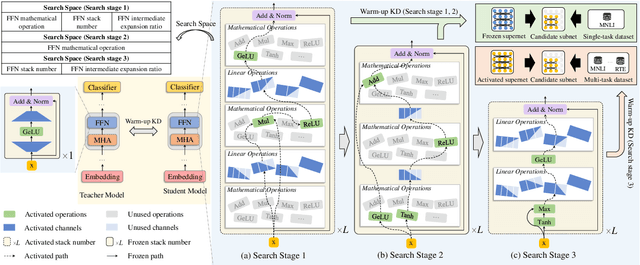
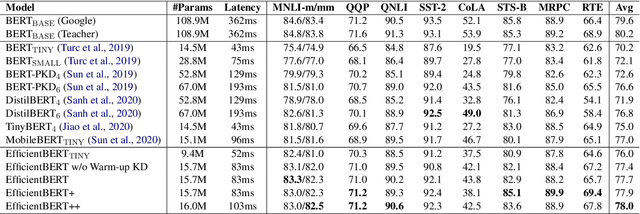
Pre-trained language models have shown remarkable results on various NLP tasks. Nevertheless, due to their bulky size and slow inference speed, it is hard to deploy them on edge devices. In this paper, we have a critical insight that improving the feed-forward network (FFN) in BERT has a higher gain than improving the multi-head attention (MHA) since the computational cost of FFN is 2$\sim$3 times larger than MHA. Hence, to compact BERT, we are devoted to designing efficient FFN as opposed to previous works that pay attention to MHA. Since FFN comprises a multilayer perceptron (MLP) that is essential in BERT optimization, we further design a thorough search space towards an advanced MLP and perform a coarse-to-fine mechanism to search for an efficient BERT architecture. Moreover, to accelerate searching and enhance model transferability, we employ a novel warm-up knowledge distillation strategy at each search stage. Extensive experiments show our searched EfficientBERT is 6.9$\times$ smaller and 4.4$\times$ faster than BERT$\rm_{BASE}$, and has competitive performances on GLUE and SQuAD Benchmarks. Concretely, EfficientBERT attains a 77.7 average score on GLUE \emph{test}, 0.7 higher than MobileBERT$\rm_{TINY}$, and achieves an 85.3/74.5 F1 score on SQuAD v1.1/v2.0 \emph{dev}, 3.2/2.7 higher than TinyBERT$_4$ even without data augmentation. The code is released at https://github.com/cheneydon/efficient-bert.
Pi-NAS: Improving Neural Architecture Search by Reducing Supernet Training Consistency Shift
Aug 22, 2021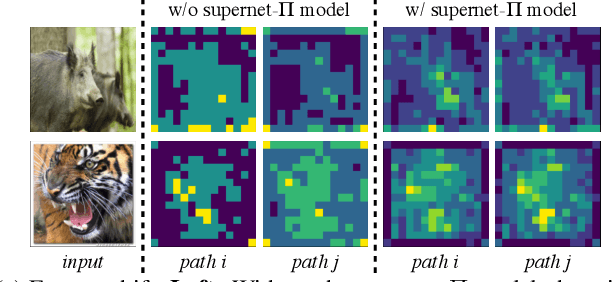
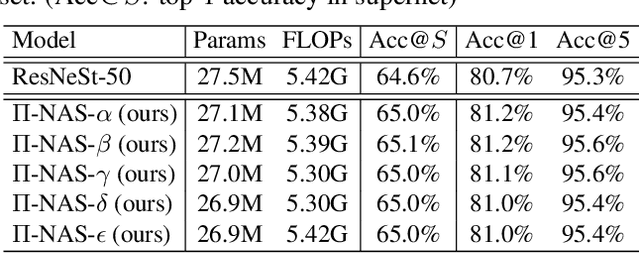
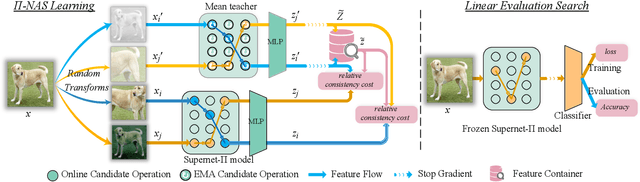
Recently proposed neural architecture search (NAS) methods co-train billions of architectures in a supernet and estimate their potential accuracy using the network weights detached from the supernet. However, the ranking correlation between the architectures' predicted accuracy and their actual capability is incorrect, which causes the existing NAS methods' dilemma. We attribute this ranking correlation problem to the supernet training consistency shift, including feature shift and parameter shift. Feature shift is identified as dynamic input distributions of a hidden layer due to random path sampling. The input distribution dynamic affects the loss descent and finally affects architecture ranking. Parameter shift is identified as contradictory parameter updates for a shared layer lay in different paths in different training steps. The rapidly-changing parameter could not preserve architecture ranking. We address these two shifts simultaneously using a nontrivial supernet-Pi model, called Pi-NAS. Specifically, we employ a supernet-Pi model that contains cross-path learning to reduce the feature consistency shift between different paths. Meanwhile, we adopt a novel nontrivial mean teacher containing negative samples to overcome parameter shift and model collision. Furthermore, our Pi-NAS runs in an unsupervised manner, which can search for more transferable architectures. Extensive experiments on ImageNet and a wide range of downstream tasks (e.g., COCO 2017, ADE20K, and Cityscapes) demonstrate the effectiveness and universality of our Pi-NAS compared to supervised NAS. See Codes: https://github.com/Ernie1/Pi-NAS.
BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
Mar 24, 2021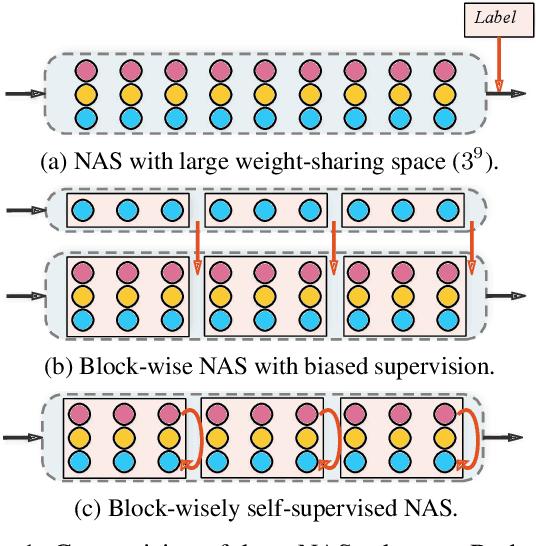
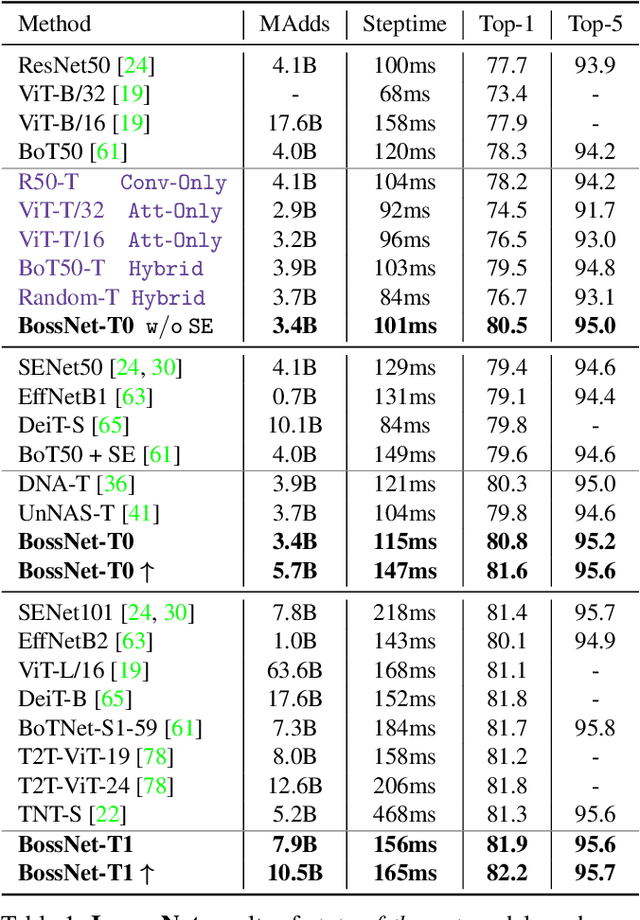
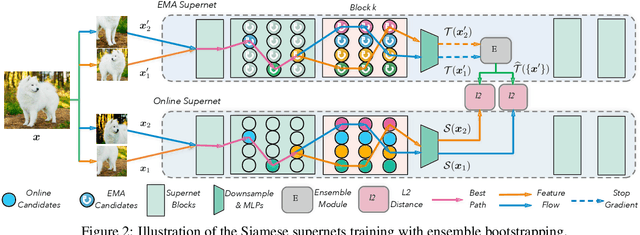
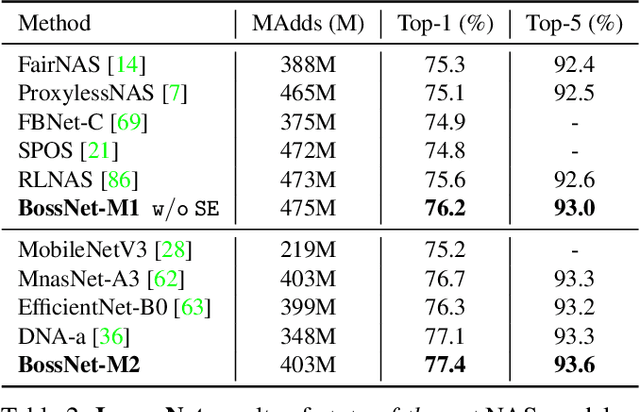
A myriad of recent breakthroughs in hand-crafted neural architectures for visual recognition have highlighted the urgent need to explore hybrid architectures consisting of diversified building blocks. Meanwhile, neural architecture search methods are surging with an expectation to reduce human efforts. However, whether NAS methods can efficiently and effectively handle diversified search spaces with disparate candidates (e.g. CNNs and transformers) is still an open question. In this work, we present Block-wisely Self-supervised Neural Architecture Search (BossNAS), an unsupervised NAS method that addresses the problem of inaccurate architecture rating caused by large weight-sharing space and biased supervision in previous methods. More specifically, we factorize the search space into blocks and utilize a novel self-supervised training scheme, named ensemble bootstrapping, to train each block separately before searching them as a whole towards the population center. Additionally, we present HyTra search space, a fabric-like hybrid CNN-transformer search space with searchable down-sampling positions. On this challenging search space, our searched model, BossNet-T, achieves up to 82.2% accuracy on ImageNet, surpassing EfficientNet by 2.1% with comparable compute time. Moreover, our method achieves superior architecture rating accuracy with 0.78 and 0.76 Spearman correlation on the canonical MBConv search space with ImageNet and on NATS-Bench size search space with CIFAR-100, respectively, surpassing state-of-the-art NAS methods. Code and pretrained models are available at https://github.com/changlin31/BossNAS .
Blockwisely Supervised Neural Architecture Search with Knowledge Distillation
Nov 29, 2019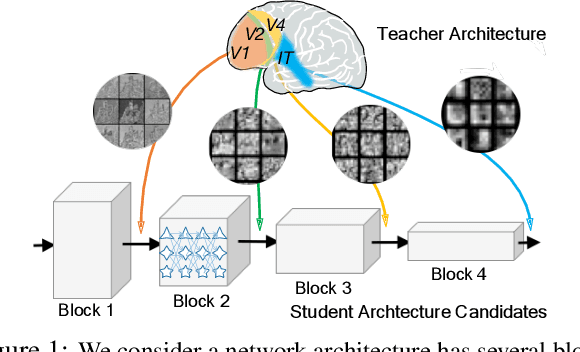
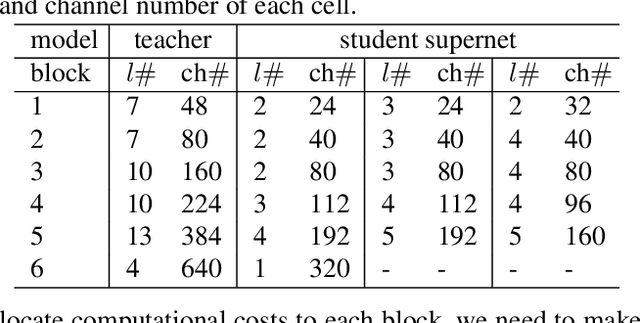
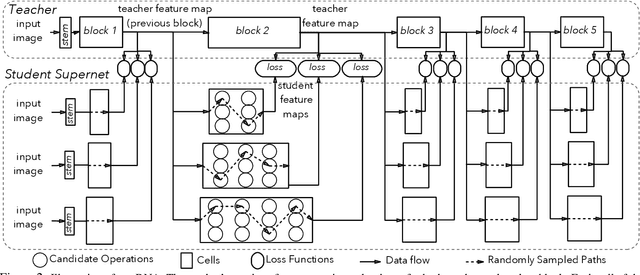
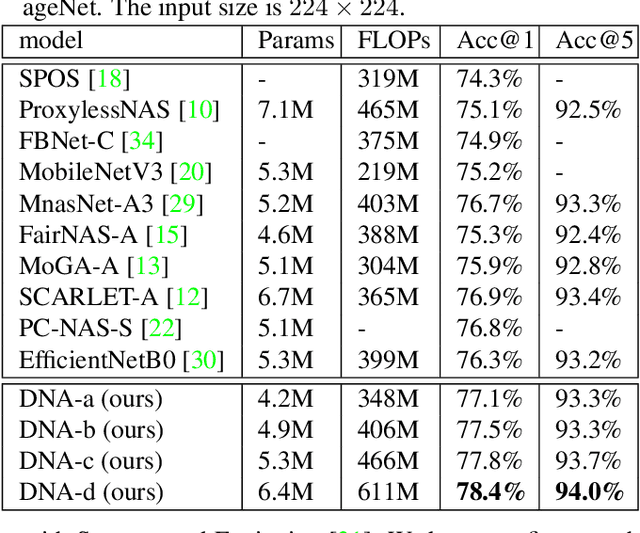
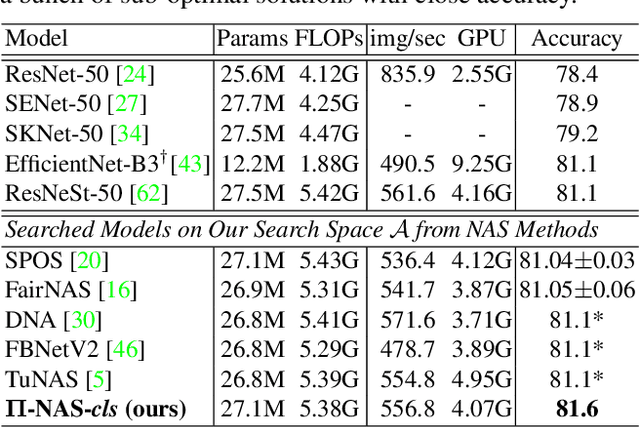
Neural Architecture Search (NAS), aiming at automatically designing network architectures by machines, is hoped and expected to bring about a new revolution in machine learning. Despite these high expectation, the effectiveness and efficiency of existing NAS solutions are unclear, with some recent works going so far as to suggest that many existing NAS solutions are no better than random architecture selection. The inefficiency of NAS solutions may be attributed to inaccurate architecture evaluation. Specifically, to speed up NAS, recent works have proposed under-training different candidate architectures in a large search space concurrently by using shared network parameters; however, this has resulted in incorrect architecture ratings and furthered the ineffectiveness of NAS. In this work, we propose to modularize the large search space of NAS into blocks to ensure that the potential candidate architectures are fully trained; this reduces the representation shift caused by the shared parameters and leads to the correct rating of the candidates. Thanks to the block-wise search, we can also evaluate all of the candidate architectures within a block. Moreover, we find that the knowledge of a network model lies not only in the network parameters but also in the network architecture. Therefore, we propose to distill the neural architecture (DNA) knowledge from a teacher model as the supervision to guide our block-wise architecture search, which significantly improves the effectiveness of NAS. Remarkably, the capacity of our searched architecture has exceeded the teacher model, demonstrating the practicability and scalability of our method. Finally, our method achieves a state-of-the-art 78.4\% top-1 accuracy on ImageNet in a mobile setting, which is about a 2.1\% gain over EfficientNet-B0. All of our searched models along with the evaluation code are available online.
Learning Deep Representations for Semantic Image Parsing: a Comprehensive Overview
Oct 10, 2018


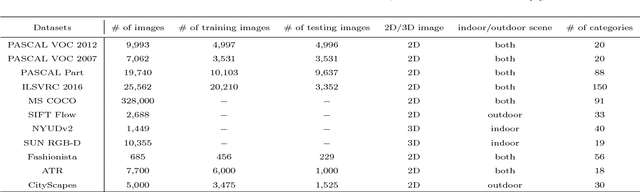
Semantic image parsing, which refers to the process of decomposing images into semantic regions and constructing the structure representation of the input, has recently aroused widespread interest in the field of computer vision. The recent application of deep representation learning has driven this field into a new stage of development. In this paper, we summarize three aspects of the progress of research on semantic image parsing, i.e., category-level semantic segmentation, instance-level semantic segmentation, and beyond segmentation. Specifically, we first review the general frameworks for each task and introduce the relevant variants. The advantages and limitations of each method are also discussed. Moreover, we present a comprehensive comparison of different benchmark datasets and evaluation metrics. Finally, we explore the future trends and challenges of semantic image parsing.
Attentive Crowd Flow Machines
Sep 01, 2018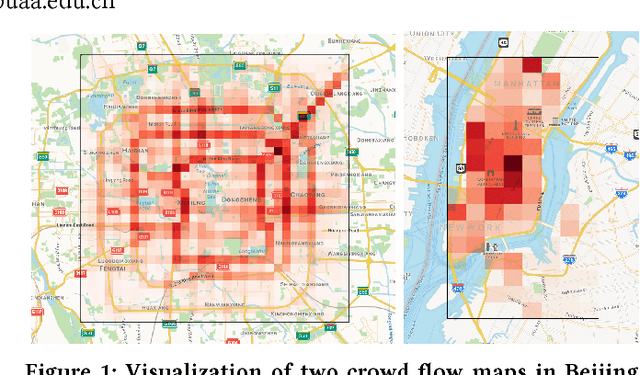
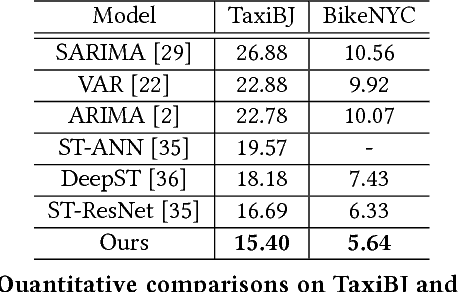
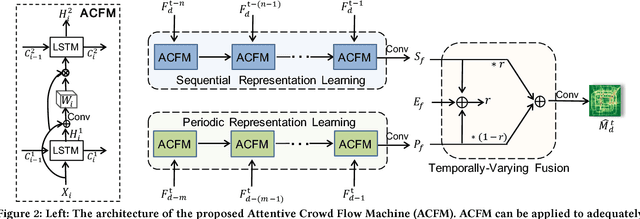
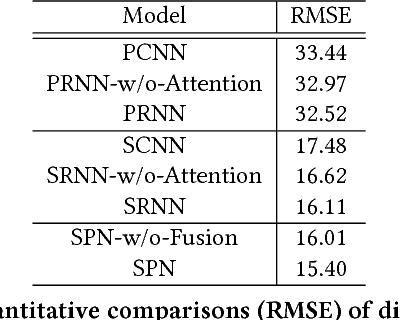
Traffic flow prediction is crucial for urban traffic management and public safety. Its key challenges lie in how to adaptively integrate the various factors that affect the flow changes. In this paper, we propose a unified neural network module to address this problem, called Attentive Crowd Flow Machine~(ACFM), which is able to infer the evolution of the crowd flow by learning dynamic representations of temporally-varying data with an attention mechanism. Specifically, the ACFM is composed of two progressive ConvLSTM units connected with a convolutional layer for spatial weight prediction. The first LSTM takes the sequential flow density representation as input and generates a hidden state at each time-step for attention map inference, while the second LSTM aims at learning the effective spatial-temporal feature expression from attentionally weighted crowd flow features. Based on the ACFM, we further build a deep architecture with the application to citywide crowd flow prediction, which naturally incorporates the sequential and periodic data as well as other external influences. Extensive experiments on two standard benchmarks (i.e., crowd flow in Beijing and New York City) show that the proposed method achieves significant improvements over the state-of-the-art methods.
Batch Kalman Normalization: Towards Training Deep Neural Networks with Micro-Batches
Feb 28, 2018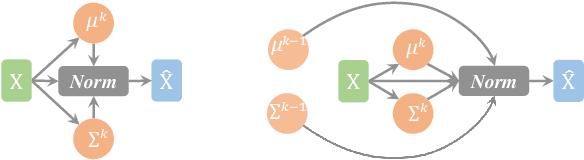

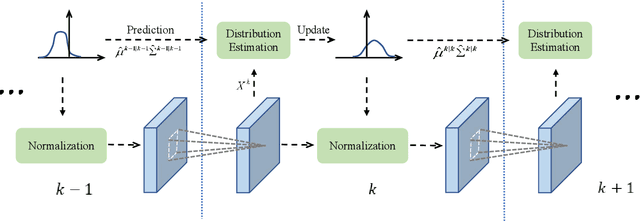
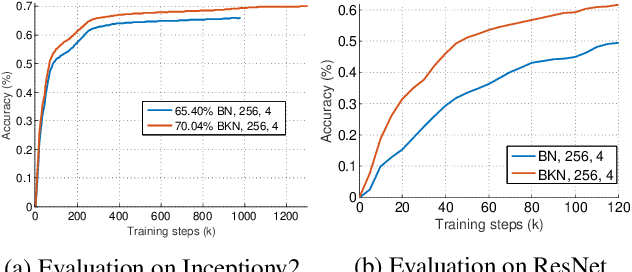
As an indispensable component, Batch Normalization (BN) has successfully improved the training of deep neural networks (DNNs) with mini-batches, by normalizing the distribution of the internal representation for each hidden layer. However, the effectiveness of BN would diminish with scenario of micro-batch (e.g., less than 10 samples in a mini-batch), since the estimated statistics in a mini-batch are not reliable with insufficient samples. In this paper, we present a novel normalization method, called Batch Kalman Normalization (BKN), for improving and accelerating the training of DNNs, particularly under the context of micro-batches. Specifically, unlike the existing solutions treating each hidden layer as an isolated system, BKN treats all the layers in a network as a whole system, and estimates the statistics of a certain layer by considering the distributions of all its preceding layers, mimicking the merits of Kalman Filtering. BKN has two appealing properties. First, it enables more stable training and faster convergence compared to previous works. Second, training DNNs using BKN performs substantially better than those using BN and its variants, especially when very small mini-batches are presented. On the image classification benchmark of ImageNet, using BKN powered networks we improve upon the best-published model-zoo results: reaching 74.0% top-1 val accuracy for InceptionV2. More importantly, using BKN achieves the comparable accuracy with extremely smaller batch size, such as 64 times smaller on CIFAR-10/100 and 8 times smaller on ImageNet.