 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Enabled Multi-Task Physical Layer Network
Dec 30, 2024The recent advance of Artificial Intelligence (AI) is continuously reshaping the future 6G wireless communications. Recently, the development of Large Language Models (LLMs) offers a promising approach to effectively improve the performance and generalization for different physical layer tasks. However, most existing works finetune dedicated LLM networks for a single wireless communication task separately. Thus performing diverse physical layer tasks introduces extremely high training resources, memory usage, and deployment costs. To solve the problem, we propose a LLM-enabled multi-task physical layer network to unify multiple tasks with a single LLM. Specifically, we first propose a multi-task LLM framework, which finetunes LLM to perform multi-user precoding, signal detection and channel prediction simultaneously. Besides, multi-task instruction module, input encoders, as well as output decoders, are elaborately designed to distinguish multiple tasks and adapted the features of different formats of wireless data for the features of LLM. Numerical simulations are also displayed to verify the effectiveness of the proposed method.
t-READi: Transformer-Powered Robust and Efficient Multimodal Inference for Autonomous Driving
Oct 13, 2024



Given the wide adoption of multimodal sensors (e.g., camera, lidar, radar) by autonomous vehicles (AVs), deep analytics to fuse their outputs for a robust perception become imperative. However, existing fusion methods often make two assumptions rarely holding in practice: i) similar data distributions for all inputs and ii) constant availability for all sensors. Because, for example, lidars have various resolutions and failures of radars may occur, such variability often results in significant performance degradation in fusion. To this end, we present tREADi, an adaptive inference system that accommodates the variability of multimodal sensory data and thus enables robust and efficient perception. t-READi identifies variation-sensitive yet structure-specific model parameters; it then adapts only these parameters while keeping the rest intact. t-READi also leverages a cross-modality contrastive learning method to compensate for the loss from missing modalities. Both functions are implemented to maintain compatibility with existing multimodal deep fusion methods. The extensive experiments evidently demonstrate that compared with the status quo approaches, t-READi not only improves the average inference accuracy by more than 6% but also reduces the inference latency by almost 15x with the cost of only 5% extra memory overhead in the worst case under realistic data and modal variations.
Error Correction Code Transformer: From Non-Unified to Unified
Oct 04, 2024



Channel coding is vital for reliable data transmission in modern wireless systems, and its significance will increase with the emergence of sixth-generation (6G) networks, which will need to support various error correction codes. However, traditional decoders were typically designed as fixed hardware circuits tailored to specific decoding algorithms, leading to inefficiencies and limited flexibility. To address these challenges, this paper proposes a unified, code-agnostic Transformer-based decoding architecture capable of handling multiple linear block codes, including Polar, Low-Density Parity-Check (LDPC), and Bose-Chaudhuri-Hocquenghem (BCH), within a single framework. To achieve this, standardized units are employed to harmonize parameters across different code types, while the redesigned unified attention module compresses the structural information of various codewords. Additionally, a sparse mask, derived from the sparsity of the parity-check matrix, is introduced to enhance the model's ability to capture inherent constraints between information and parity-check bits, resulting in improved decoding accuracy and robustness. Extensive experimental results demonstrate that the proposed unified Transformer-based decoder not only outperforms existing methods but also provides a flexible, efficient, and high-performance solution for next-generation wireless communication systems.
Near-Field Wideband Beam Training Based on Distance-Dependent Beam Split
Jun 12, 2024



Near-field beam training is essential for acquiring channel state information in 6G extremely large-scale multiple input multiple output (XL-MIMO) systems. To achieve low-overhead beam training, existing method has been proposed to leverage the near-field beam split effect, which deploys true-time-delay arrays to simultaneously search multiple angles of the entire angular range in a distance ring with a single pilot. However, the method still requires exhaustive search in the distance domain, which limits its efficiency. To address the problem, we propose a distance-dependent beam-split-based beam training method to further reduce the training overheads. Specifically, we first reveal the new phenomenon of distance-dependent beam split, where by manipulating the configurations of time-delay and phase-shift, beams at different frequencies can simultaneously scan the angular domain in multiple distance rings. Leveraging the phenomenon, we propose a near-field beam training method where both different angles and distances can simultaneously be searched in one time slot. Thus, a few pilots are capable of covering the whole angle-distance space for wideband XL-MIMO. Theoretical analysis and numerical simulations are also displayed to verify the superiority of the proposed method on beamforming gain and training overhead.
Coded Beam Training
Jan 03, 2024



In extremely large-scale multiple input multiple output (XL-MIMO) systems for future sixth-generation (6G) communications, codebook-based beam training stands out as a promising technology to acquire channel state information (CSI). Despite their effectiveness, when the pilot overhead is limited, existing beam training methods suffer from significant achievable rate degradation for remote users with low signal-to-noise ratio (SNR). To tackle this challenge, leverging the error-correcting capability of channel codes, we introduce channel coding theory into hierarchical beam training to extend the coverage area. Specifically, we establish the duality between hierarchical beam training and channel coding, and the proposed coded beam training scheme serves as a general framework. Then, we present two specific implementations exemplified by coded beam training methods based on Hamming codes and convolutional codes, during which the beam encoding and decoding processes are refined respectively to better accommodate to the beam training problem. Simulation results have demonstrated that, the proposed coded beam training method can enable reliable beam training performance for remote users with low SNR, while keeping training overhead low.
HoloFed: Environment-Adaptive Positioning via Multi-band Reconfigurable Holographic Surfaces and Federated Learning
Oct 10, 2023Positioning is an essential service for various applications and is expected to be integrated with existing communication infrastructures in 5G and 6G. Though current Wi-Fi and cellular base stations (BSs) can be used to support this integration, the resulting precision is unsatisfactory due to the lack of precise control of the wireless signals. Recently, BSs adopting reconfigurable holographic surfaces (RHSs) have been advocated for positioning as RHSs' large number of antenna elements enable generation of arbitrary and highly-focused signal beam patterns. However, existing designs face two major challenges: i) RHSs only have limited operating bandwidth, and ii) the positioning methods cannot adapt to the diverse environments encountered in practice. To overcome these challenges, we present HoloFed, a system providing high-precision environment-adaptive user positioning services by exploiting multi-band(MB)-RHS and federated learning (FL). For improving the positioning performance, a lower bound on the error variance is obtained and utilized for guiding MB-RHS's digital and analog beamforming design. For better adaptability while preserving privacy, an FL framework is proposed for users to collaboratively train a position estimator, where we exploit the transfer learning technique to handle the lack of position labels of the users. Moreover, a scheduling algorithm for the BS to select which users train the position estimator is designed, jointly considering the convergence and efficiency of FL. Our simulation results confirm that HoloFed achieves a 57% lower positioning error variance compared to a beam-scanning baseline and can effectively adapt to diverse environments.
OCHID-Fi: Occlusion-Robust Hand Pose Estimation in 3D via RF-Vision
Aug 20, 2023



Hand Pose Estimation (HPE) is crucial to many applications, but conventional cameras-based CM-HPE methods are completely subject to Line-of-Sight (LoS), as cameras cannot capture occluded objects. In this paper, we propose to exploit Radio-Frequency-Vision (RF-vision) capable of bypassing obstacles for achieving occluded HPE, and we introduce OCHID-Fi as the first RF-HPE method with 3D pose estimation capability. OCHID-Fi employs wideband RF sensors widely available on smart devices (e.g., iPhones) to probe 3D human hand pose and extract their skeletons behind obstacles. To overcome the challenge in labeling RF imaging given its human incomprehensible nature, OCHID-Fi employs a cross-modality and cross-domain training process. It uses a pre-trained CM-HPE network and a synchronized CM/RF dataset, to guide the training of its complex-valued RF-HPE network under LoS conditions. It further transfers knowledge learned from labeled LoS domain to unlabeled occluded domain via adversarial learning, enabling OCHID-Fi to generalize to unseen occluded scenarios. Experimental results demonstrate the superiority of OCHID-Fi: it achieves comparable accuracy to CM-HPE under normal conditions while maintaining such accuracy even in occluded scenarios, with empirical evidence for its generalizability to new domains.
AutoFed: Heterogeneity-Aware Federated Multimodal Learning for Robust Autonomous Driving
Feb 24, 2023Object detection with on-board sensors (e.g., lidar, radar, and camera) play a crucial role in autonomous driving (AD), and these sensors complement each other in modalities. While crowdsensing may potentially exploit these sensors (of huge quantity) to derive more comprehensive knowledge, \textit{federated learning} (FL) appears to be the necessary tool to reach this potential: it enables autonomous vehicles (AVs) to train machine learning models without explicitly sharing raw sensory data. However, the multimodal sensors introduce various data heterogeneity across distributed AVs (e.g., label quantity skews and varied modalities), posing critical challenges to effective FL. To this end, we present AutoFed as a heterogeneity-aware FL framework to fully exploit multimodal sensory data on AVs and thus enable robust AD. Specifically, we first propose a novel model leveraging pseudo-labeling to avoid mistakenly treating unlabeled objects as the background. We also propose an autoencoder-based data imputation method to fill missing data modality (of certain AVs) with the available ones. To further reconcile the heterogeneity, we finally present a client selection mechanism exploiting the similarities among client models to improve both training stability and convergence rate. Our experiments on benchmark dataset confirm that AutoFed substantially improves over status quo approaches in both precision and recall, while demonstrating strong robustness to adverse weather conditions.
Adv-4-Adv: Thwarting Changing Adversarial Perturbations via Adversarial Domain Adaptation
Dec 04, 2021
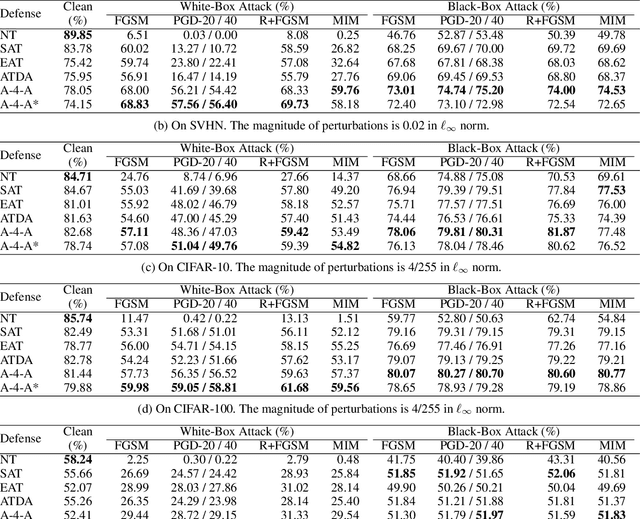
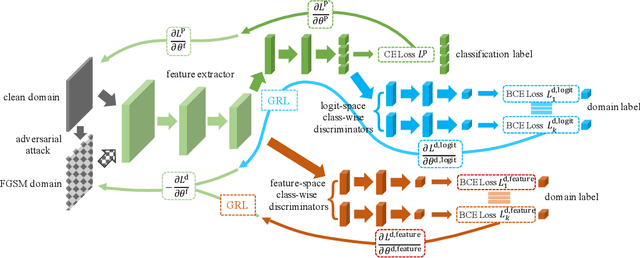
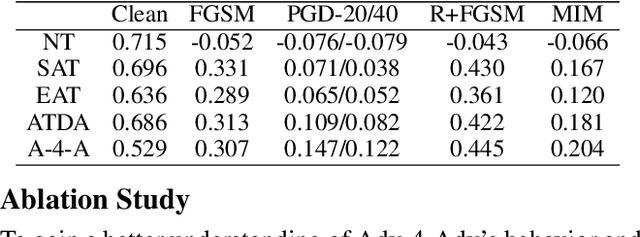
Whereas adversarial training can be useful against specific adversarial perturbations, they have also proven ineffective in generalizing towards attacks deviating from those used for training. However, we observe that this ineffectiveness is intrinsically connected to domain adaptability, another crucial issue in deep learning for which adversarial domain adaptation appears to be a promising solution. Consequently, we proposed Adv-4-Adv as a novel adversarial training method that aims to retain robustness against unseen adversarial perturbations. Essentially, Adv-4-Adv treats attacks incurring different perturbations as distinct domains, and by leveraging the power of adversarial domain adaptation, it aims to remove the domain/attack-specific features. This forces a trained model to learn a robust domain-invariant representation, which in turn enhances its generalization ability. Extensive evaluations on Fashion-MNIST, SVHN, CIFAR-10, and CIFAR-100 demonstrate that a model trained by Adv-4-Adv based on samples crafted by simple attacks (e.g., FGSM) can be generalized to more advanced attacks (e.g., PGD), and the performance exceeds state-of-the-art proposals on these datasets.
MoRe-Fi: Motion-robust and Fine-grained Respiration Monitoring via Deep-Learning UWB Radar
Nov 16, 2021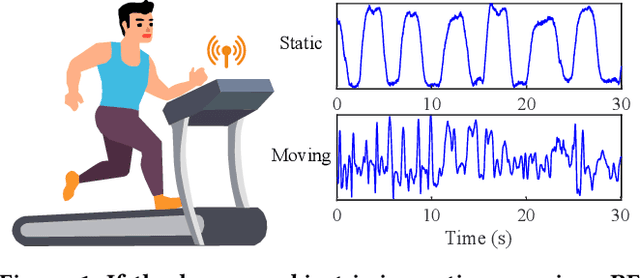
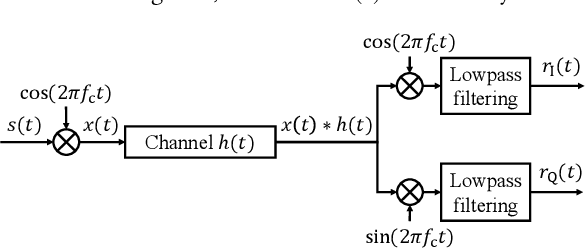
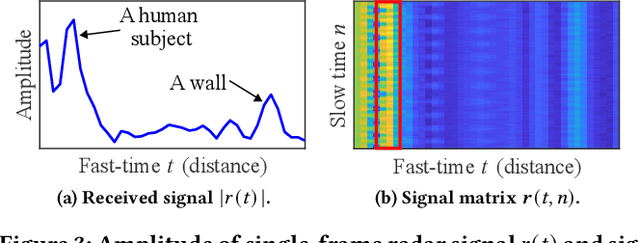
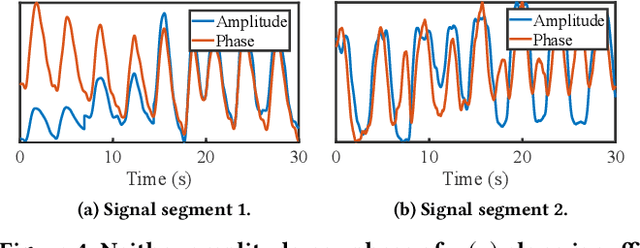
Crucial for healthcare and biomedical applications, respiration monitoring often employs wearable sensors in practice, causing inconvenience due to their direct contact with human bodies. Therefore, researchers have been constantly searching for contact-free alternatives. Nonetheless, existing contact-free designs mostly require human subjects to remain static, largely confining their adoptions in everyday environments where body movements are inevitable. Fortunately, radio-frequency (RF) enabled contact-free sensing, though suffering motion interference inseparable by conventional filtering, may offer a potential to distill respiratory waveform with the help of deep learning. To realize this potential, we introduce MoRe-Fi to conduct fine-grained respiration monitoring under body movements. MoRe-Fi leverages an IR-UWB radar to achieve contact-free sensing, and it fully exploits the complex radar signal for data augmentation. The core of MoRe-Fi is a novel variational encoder-decoder network; it aims to single out the respiratory waveforms that are modulated by body movements in a non-linear manner. Our experiments with 12 subjects and 66-hour data demonstrate that MoRe-Fi accurately recovers respiratory waveform despite the interference caused by body movements. We also discuss potential applications of MoRe-Fi for pulmonary disease diagnoses.
* 14 pages