 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Boosting Adaptive Learning under Concept Drift for Multistream Classification
Jan 01, 2024



Multistream classification poses significant challenges due to the necessity for rapid adaptation in dynamic streaming processes with concept drift. Despite the growing research outcomes in this area, there has been a notable oversight regarding the temporal dynamic relationships between these streams, leading to the issue of negative transfer arising from irrelevant data. In this paper, we propose a novel Online Boosting Adaptive Learning (OBAL) method that effectively addresses this limitation by adaptively learning the dynamic correlation among different streams. Specifically, OBAL operates in a dual-phase mechanism, in the first of which we design an Adaptive COvariate Shift Adaptation (AdaCOSA) algorithm to construct an initialized ensemble model using archived data from various source streams, thus mitigating the covariate shift while learning the dynamic correlations via an adaptive re-weighting strategy. During the online process, we employ a Gaussian Mixture Model-based weighting mechanism, which is seamlessly integrated with the acquired correlations via AdaCOSA to effectively handle asynchronous drift. This approach significantly improves the predictive performance and stability of the target stream. We conduct comprehensive experiments on several synthetic and real-world data streams, encompassing various drifting scenarios and types. The results clearly demonstrate that OBAL achieves remarkable advancements in addressing multistream classification problems by effectively leveraging positive knowledge derived from multiple sources.
Meta OOD Learning for Continuously Adaptive OOD Detection
Sep 21, 2023



Out-of-distribution (OOD) detection is crucial to modern deep learning applications by identifying and alerting about the OOD samples that should not be tested or used for making predictions. Current OOD detection methods have made significant progress when in-distribution (ID) and OOD samples are drawn from static distributions. However, this can be unrealistic when applied to real-world systems which often undergo continuous variations and shifts in ID and OOD distributions over time. Therefore, for an effective application in real-world systems, the development of OOD detection methods that can adapt to these dynamic and evolving distributions is essential. In this paper, we propose a novel and more realistic setting called continuously adaptive out-of-distribution (CAOOD) detection which targets on developing an OOD detection model that enables dynamic and quick adaptation to a new arriving distribution, with insufficient ID samples during deployment time. To address CAOOD, we develop meta OOD learning (MOL) by designing a learning-to-adapt diagram such that a good initialized OOD detection model is learned during the training process. In the testing process, MOL ensures OOD detection performance over shifting distributions by quickly adapting to new distributions with a few adaptations. Extensive experiments on several OOD benchmarks endorse the effectiveness of our method in preserving both ID classification accuracy and OOD detection performance on continuously shifting distributions.
Graph Convolutional Neural Networks with Diverse Negative Samples via Decomposed Determinant Point Processes
Dec 05, 2022Graph convolutional networks (GCNs) have achieved great success in graph representation learning by extracting high-level features from nodes and their topology. Since GCNs generally follow a message-passing mechanism, each node aggregates information from its first-order neighbour to update its representation. As a result, the representations of nodes with edges between them should be positively correlated and thus can be considered positive samples. However, there are more non-neighbour nodes in the whole graph, which provide diverse and useful information for the representation update. Two non-adjacent nodes usually have different representations, which can be seen as negative samples. Besides the node representations, the structural information of the graph is also crucial for learning. In this paper, we used quality-diversity decomposition in determinant point processes (DPP) to obtain diverse negative samples. When defining a distribution on diverse subsets of all non-neighbouring nodes, we incorporate both graph structure information and node representations. Since the DPP sampling process requires matrix eigenvalue decomposition, we propose a new shortest-path-base method to improve computational efficiency. Finally, we incorporate the obtained negative samples into the graph convolution operation. The ideas are evaluated empirically in experiments on node classification tasks. These experiments show that the newly proposed methods not only improve the overall performance of standard representation learning but also significantly alleviate over-smoothing problems.
Is Out-of-Distribution Detection Learnable?
Oct 26, 2022Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms. To study the generalization of OOD detection, in this paper, we investigate the probably approximately correct (PAC) learning theory of OOD detection, which is proposed by researchers as an open problem. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we also offer theoretical supports for several representative OOD detection works based on our OOD theory.
Streaming PAC-Bayes Gaussian process regression with a performance guarantee for online decision making
Oct 16, 2022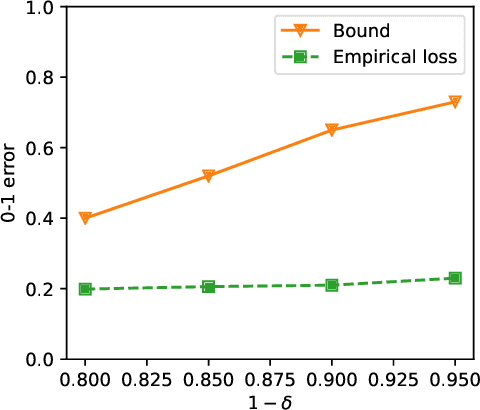

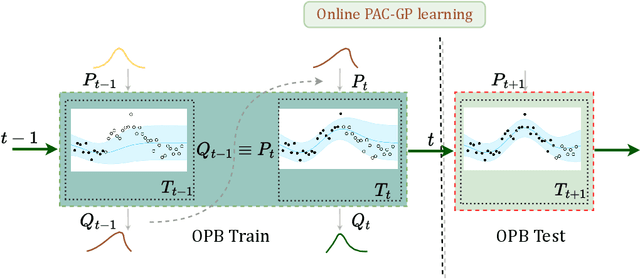
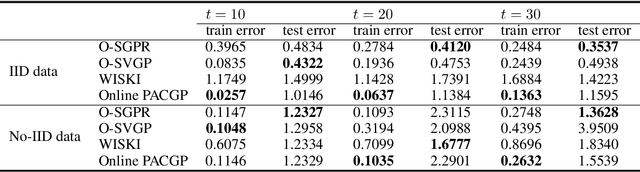
As a powerful Bayesian non-parameterized algorithm, the Gaussian process (GP) has performed a significant role in Bayesian optimization and signal processing. GPs have also advanced online decision-making systems because their posterior distribution has a closed-form solution. However, its training and inference process requires all historic data to be stored and the GP model to be trained from scratch. For those reasons, several online GP algorithms, such as O-SGPR and O-SVGP, have been specifically designed for streaming settings. In this paper, we present a new theoretical framework for online GPs based on the online probably approximately correct (PAC) Bayes theory. The framework offers both a guarantee of generalized performance and good accuracy. Instead of minimizing the marginal likelihood, our algorithm optimizes both the empirical risk function and a regularization item, which is in proportion to the divergence between the prior distribution and posterior distribution of parameters. In addition to its theoretical appeal, the algorithm performs well empirically on several regression datasets. Compared to other online GP algorithms, ours yields a generalization guarantee and very competitive accuracy.
Learning from the Dark: Boosting Graph Convolutional Neural Networks with Diverse Negative Samples
Oct 03, 2022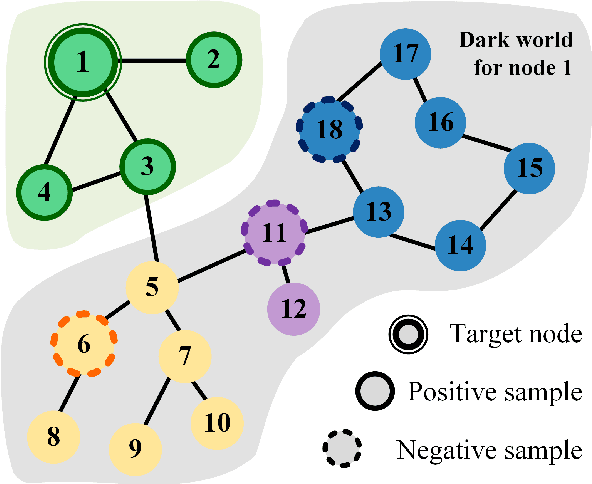

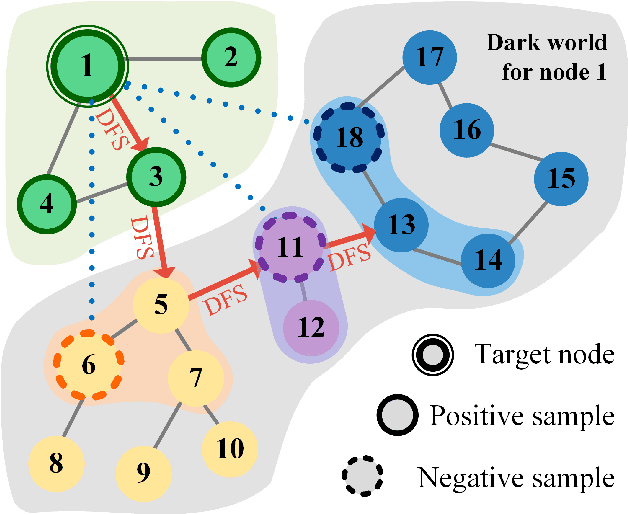
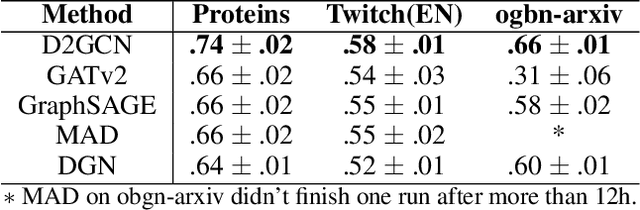
Graph Convolutional Neural Networks (GCNs) has been generally accepted to be an effective tool for node representations learning. An interesting way to understand GCNs is to think of them as a message passing mechanism where each node updates its representation by accepting information from its neighbours (also known as positive samples). However, beyond these neighbouring nodes, graphs have a large, dark, all-but forgotten world in which we find the non-neighbouring nodes (negative samples). In this paper, we show that this great dark world holds a substantial amount of information that might be useful for representation learning. Most specifically, it can provide negative information about the node representations. Our overall idea is to select appropriate negative samples for each node and incorporate the negative information contained in these samples into the representation updates. Moreover, we show that the process of selecting the negative samples is not trivial. Our theme therefore begins by describing the criteria for a good negative sample, followed by a determinantal point process algorithm for efficiently obtaining such samples. A GCN, boosted by diverse negative samples, then jointly considers the positive and negative information when passing messages. Experimental evaluations show that this idea not only improves the overall performance of standard representation learning but also significantly alleviates over-smoothing problems.
Multi-class Classification with Fuzzy-feature Observations: Theory and Algorithms
Jun 09, 2022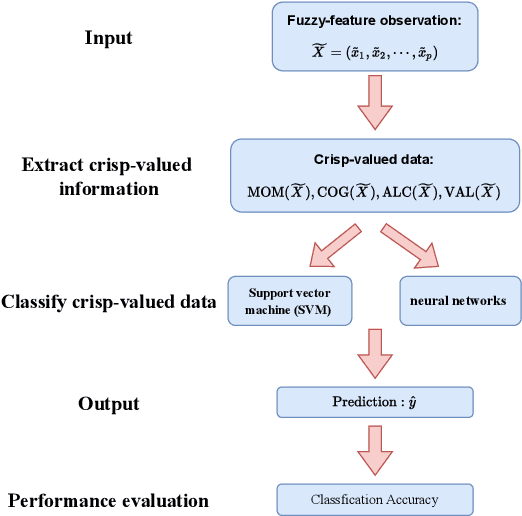
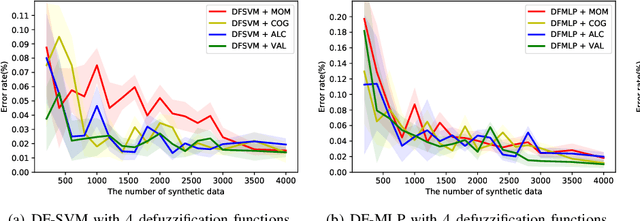
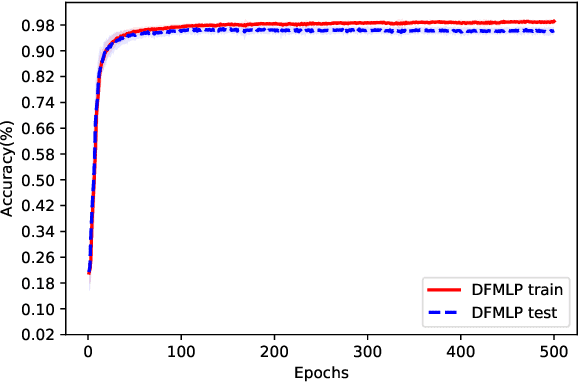
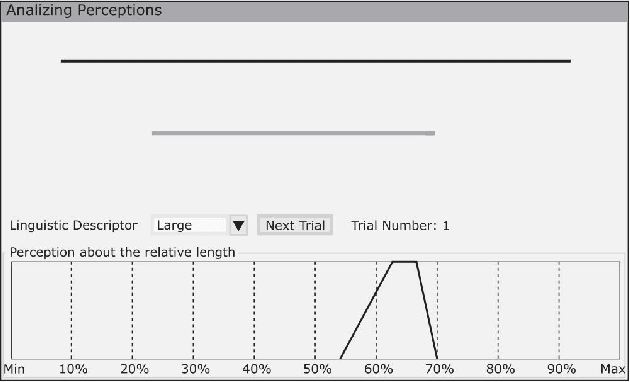
The theoretical analysis of multi-class classification has proved that the existing multi-class classification methods can train a classifier with high classification accuracy on the test set, when the instances are precise in the training and test sets with same distribution and enough instances can be collected in the training set. However, one limitation with multi-class classification has not been solved: how to improve the classification accuracy of multi-class classification problems when only imprecise observations are available. Hence, in this paper, we propose a novel framework to address a new realistic problem called multi-class classification with imprecise observations (MCIMO), where we need to train a classifier with fuzzy-feature observations. Firstly, we give the theoretical analysis of the MCIMO problem based on fuzzy Rademacher complexity. Then, two practical algorithms based on support vector machine and neural networks are constructed to solve the proposed new problem. Experiments on both synthetic and real-world datasets verify the rationality of our theoretical analysis and the efficacy of the proposed algorithms.
Bayesian Transfer Learning: An Overview of Probabilistic Graphical Models for Transfer Learning
Sep 27, 2021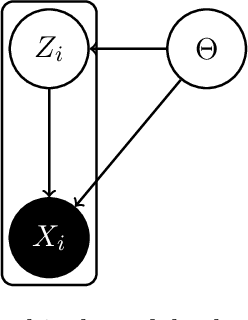

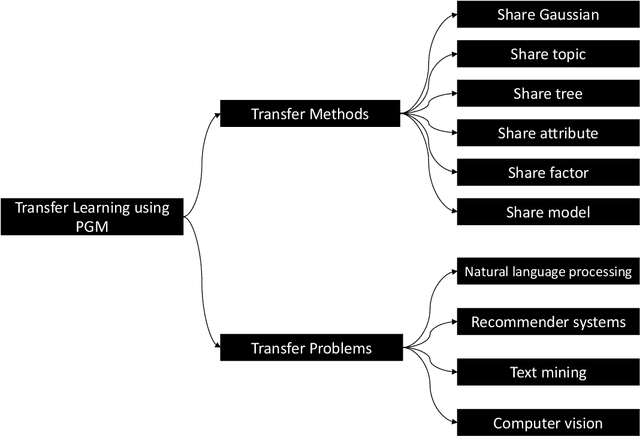
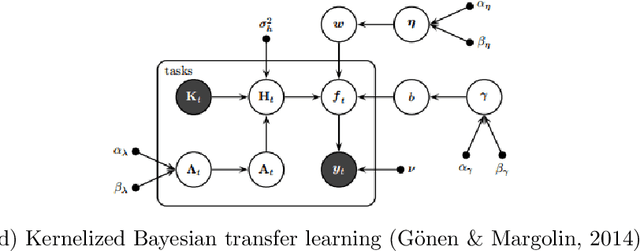
Transfer learning where the behavior of extracting transferable knowledge from the source domain(s) and reusing this knowledge to target domain has become a research area of great interest in the field of artificial intelligence. Probabilistic graphical models (PGMs) have been recognized as a powerful tool for modeling complex systems with many advantages, e.g., the ability to handle uncertainty and possessing good interpretability. Considering the success of these two aforementioned research areas, it seems natural to apply PGMs to transfer learning. However, although there are already some excellent PGMs specific to transfer learning in the literature, the potential of PGMs for this problem is still grossly underestimated. This paper aims to boost the development of PGMs for transfer learning by 1) examining the pilot studies on PGMs specific to transfer learning, i.e., analyzing and summarizing the existing mechanisms particularly designed for knowledge transfer; 2) discussing examples of real-world transfer problems where existing PGMs have been successfully applied; and 3) exploring several potential research directions on transfer learning using PGM.
Deep Bayesian Estimation for Dynamic Treatment Regimes with a Long Follow-up Time
Sep 20, 2021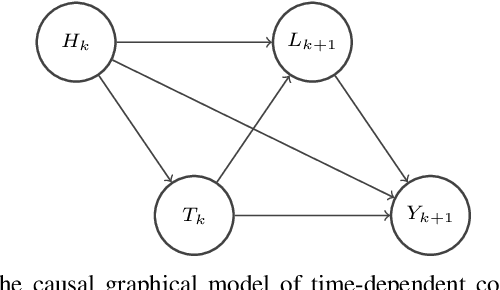
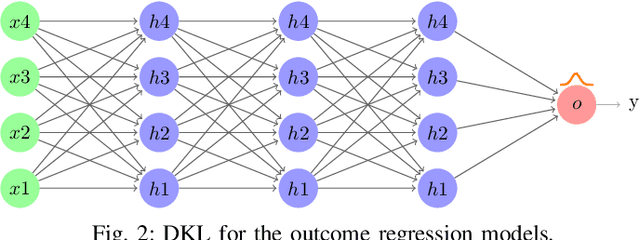
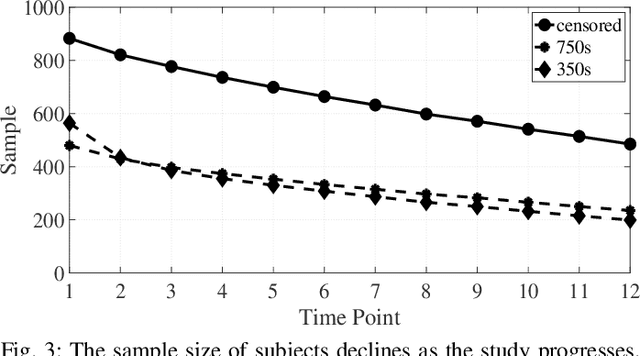
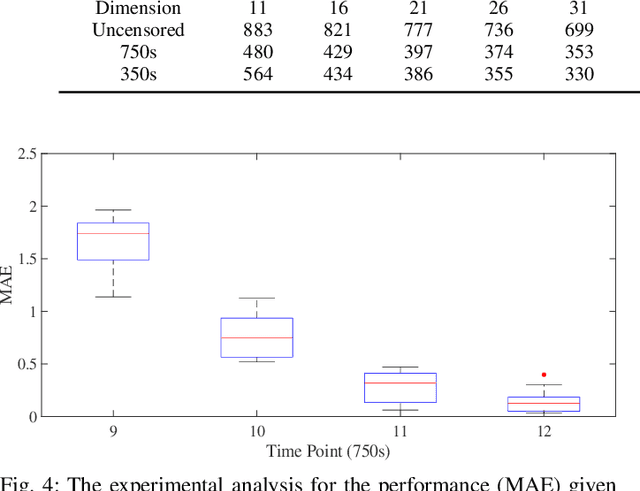
Causal effect estimation for dynamic treatment regimes (DTRs) contributes to sequential decision making. However, censoring and time-dependent confounding under DTRs are challenging as the amount of observational data declines over time due to a reducing sample size but the feature dimension increases over time. Long-term follow-up compounds these challenges. Another challenge is the highly complex relationships between confounders, treatments, and outcomes, which causes the traditional and commonly used linear methods to fail. We combine outcome regression models with treatment models for high dimensional features using uncensored subjects that are small in sample size and we fit deep Bayesian models for outcome regression models to reveal the complex relationships between confounders, treatments, and outcomes. Also, the developed deep Bayesian models can model uncertainty and output the prediction variance which is essential for the safety-aware applications, such as self-driving cars and medical treatment design. The experimental results on medical simulations of HIV treatment show the ability of the proposed method to obtain stable and accurate dynamic causal effect estimation from observational data, especially with long-term follow-up. Our technique provides practical guidance for sequential decision making, and policy-making.
Learning Bounds for Open-Set Learning
Jun 30, 2021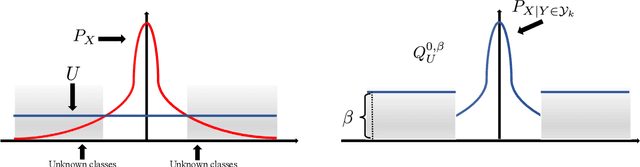
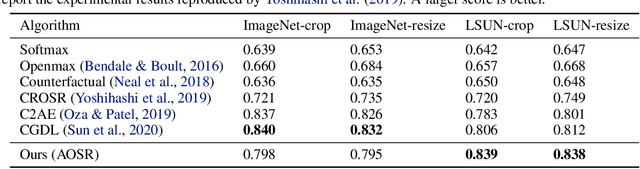

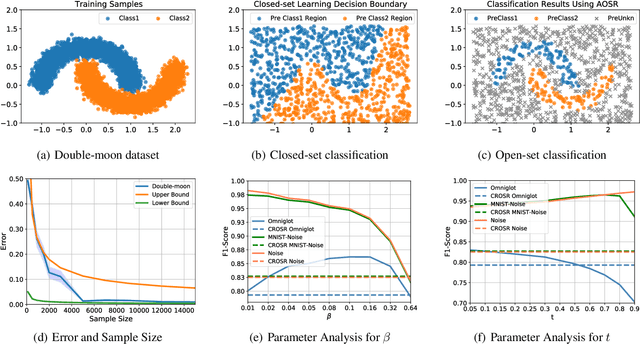
Traditional supervised learning aims to train a classifier in the closed-set world, where training and test samples share the same label space. In this paper, we target a more challenging and realistic setting: open-set learning (OSL), where there exist test samples from the classes that are unseen during training. Although researchers have designed many methods from the algorithmic perspectives, there are few methods that provide generalization guarantees on their ability to achieve consistent performance on different training samples drawn from the same distribution. Motivated by the transfer learning and probably approximate correct (PAC) theory, we make a bold attempt to study OSL by proving its generalization error-given training samples with size n, the estimation error will get close to order O_p(1/\sqrt{n}). This is the first study to provide a generalization bound for OSL, which we do by theoretically investigating the risk of the target classifier on unknown classes. According to our theory, a novel algorithm, called auxiliary open-set risk (AOSR) is proposed to address the OSL problem. Experiments verify the efficacy of AOSR. The code is available at github.com/Anjin-Liu/Openset_Learning_AOSR.