 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinHarness: An Inline Lifecycle Safety Harness for Finance LLM Agents
May 26, 2026Finance LLM agents must simultaneously block prompt-induced unauthorized actions and approve legitimate multi-step business workflows. However, boundary filters often miss irreversible mid-trajectory tool calls, while post-hoc LLM judges perform auditing only after termination -- too late for intervention and at a computational cost that scales linearly with trace length. We present FinHarness, an inline safety harness that wraps a finance agent end-to-end with three components: a Query Monitor that fuses single-turn intent with cross-turn drift, a Tool Monitor that evaluates each prospective tool call, and a Cascade module that integrates per-step risk and adaptively routes verification between a lightweight and an advanced-tier LLM judge. Fired risk factors are re-injected into the agent input as ex-ante evidence, enabling the agent to refuse, re-plan, or approve on its own. On FinVault, routed FinHarness cuts ASR from 38.3% to 15.0% while largely preserving benign approval ($41.1\% \to 39.3\%$), and uses $4.7\times$ fewer advanced-judge calls than an always-advanced ablation.
ExTax: Explainable Disinformation Detection via Persuasion, Emotion, and Narrative Role Taxonomies
May 26, 2026The democratization of LLMs has accelerated the generation and circulation of highly fluent disinformation, making traditional syntax-semantic verification increasingly insufficient. Such deception rarely relies solely on surface-level falsity; instead, it often combines persuasive rhetoric, emotional manipulation, and narrative role construction to influence readers' interpretations through multiple cognitive pathways. However, existing detectors typically emphasize isolated signals -- such as syntax, external knowledge, persuasion, or affective cues -- and therefore struggle to capture the multi-faceted manipulative intents underlying disinformation or provide human-auditable explanations. To address this gap, we present \textbf{ExTax}, a taxonomy-aligned framework for explainable disinformation detection. ExTax unifies persuasive rhetoric, emotional manipulation, and narrative roles into a 17-dimensional taxonomic space, covering 6 persuasive-rhetoric strategies, 5 emotional-manipulation methods, and 6 narrative-role categories. It elicits attributes from multiple frontier LLMs, reconciles their disagreements through Entropy-driven Dynamic Label Smoothing, and fuses the resulting taxonomic representations with contextual encodings via Heterogeneous Multi-Head Attention, grounding each prediction in an interpretable manipulation profile. Across five cross-domain and cross-genre benchmarks, ExTax achieves an overall Macro $F_1$ of $0.8456$, outperforming state-of-the-art deep learning and LLM-based baselines. It also remains robust under severe genre imbalance, where the strongest deep baseline degrades from $0.9454$ to $0.6194$.
Multi-objective Feature Selection with Missing Data in Classification
Apr 18, 2021
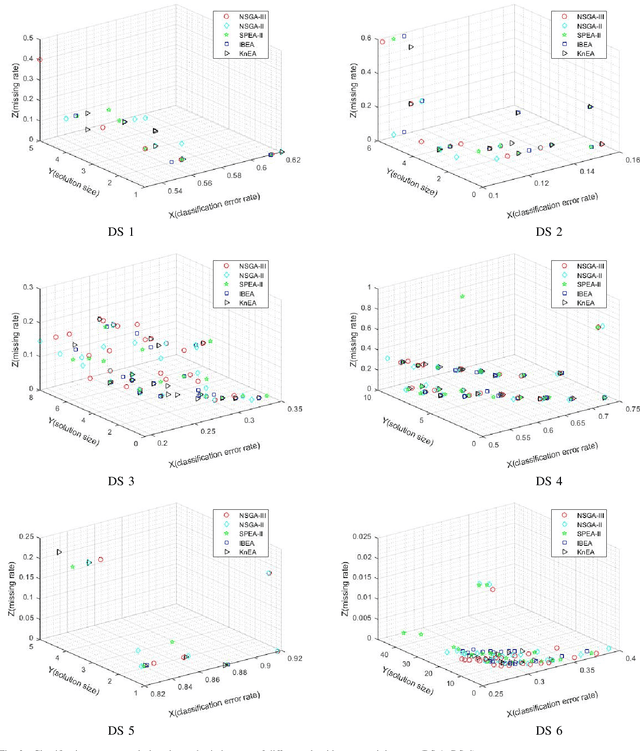

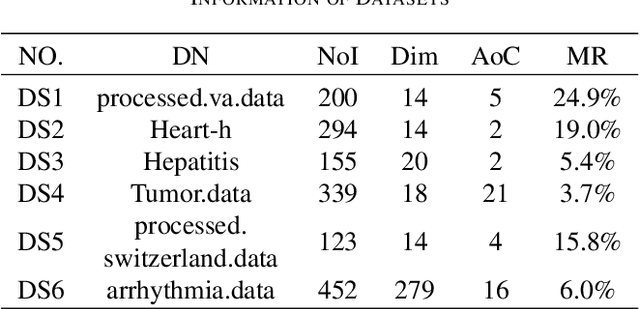
Feature selection (FS) is an important research topic in machine learning. Usually, FS is modelled as a+ bi-objective optimization problem whose objectives are: 1) classification accuracy; 2) number of features. One of the main issues in real-world applications is missing data. Databases with missing data are likely to be unreliable. Thus, FS performed on a data set missing some data is also unreliable. In order to directly control this issue plaguing the field, we propose in this study a novel modelling of FS: we include reliability as the third objective of the problem. In order to address the modified problem, we propose the application of the non-dominated sorting genetic algorithm-III (NSGA-III). We selected six incomplete data sets from the University of California Irvine (UCI) machine learning repository. We used the mean imputation method to deal with the missing data. In the experiments, k-nearest neighbors (K-NN) is used as the classifier to evaluate the feature subsets. Experimental results show that the proposed three-objective model coupled with NSGA-III efficiently addresses the FS problem for the six data sets included in this study.