 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeW2T: LoRA Weights Already Know What They Can Do
Mar 16, 2026Each LoRA checkpoint compactly stores task-specific updates in low-rank weight matrices, offering an efficient way to adapt large language models to new tasks and domains. In principle, these weights already encode what the adapter does and how well it performs. In this paper, we ask whether this information can be read directly from the weights, without running the base model or accessing training data. A key obstacle is that a single LoRA update can be factorized in infinitely many ways. Without resolving this ambiguity, models trained on the factors may fit the particular factorization rather than the underlying update. To this end, we propose \methodfull, which maps each LoRA update to a provably canonical form via QR decomposition followed by SVD, so that all equivalent factorizations share the same representation. The resulting components are then tokenized and processed by a Transformer to produce a weight-space embedding. Across language and vision LoRA collections, W2T achieves strong results on attribute classification, performance prediction, and adapter retrieval, demonstrating that LoRA weights reliably indicate model behavior once factorization ambiguity is removed. Code is available at https://github.com/xiaolonghan2000/Weight2Token.
A Survey of Weight Space Learning: Understanding, Representation, and Generation
Mar 10, 2026Neural network weights are typically viewed as the end product of training, while most deep learning research focuses on data, features, and architectures. However, recent advances show that the set of all possible weight values (weight space) itself contains rich structure: pretrained models form organized distributions, exhibit symmetries, and can be embedded, compared, or even generated. Understanding such structures has tremendous impact on how neural networks are analyzed and compared, and on how knowledge is transferred across models, beyond individual training instances. This emerging research direction, which we refer to as Weight Space Learning (WSL), treats neural weights as a meaningful domain for analysis and modeling. This survey provides the first unified taxonomy of WSL. We categorize existing methods into three core dimensions: Weight Space Understanding (WSU), which studies the geometry and symmetries of weights; Weight Space Representation (WSR), which learns embeddings over model weights; and Weight Space Generation (WSG), which synthesizes new weights through hypernetworks or generative models. We further show how these developments enable practical applications, including model retrieval, continual and federated learning, neural architecture search, and data-free reconstruction. By consolidating fragmented progress under a coherent framework, this survey highlights weight space as a learnable, structured domain with growing impact across model analysis, transferring, and weight generation. We release an accompanying resource at https://github.com/Zehong-Wang/Awesome-Weight-Space-Learning.
Cyberbullying Detection via Aggression-Enhanced Prompting
Aug 08, 2025Detecting cyberbullying on social media remains a critical challenge due to its subtle and varied expressions. This study investigates whether integrating aggression detection as an auxiliary task within a unified training framework can enhance the generalisation and performance of large language models (LLMs) in cyberbullying detection. Experiments are conducted on five aggression datasets and one cyberbullying dataset using instruction-tuned LLMs. We evaluated multiple strategies: zero-shot, few-shot, independent LoRA fine-tuning, and multi-task learning (MTL). Given the inconsistent results of MTL, we propose an enriched prompt pipeline approach in which aggression predictions are embedded into cyberbullying detection prompts to provide contextual augmentation. Preliminary results show that the enriched prompt pipeline consistently outperforms standard LoRA fine-tuning, indicating that aggression-informed context significantly boosts cyberbullying detection. This study highlights the potential of auxiliary tasks, such as aggression detection, to improve the generalisation of LLMs for safety-critical applications on social networks.
DASViT: Differentiable Architecture Search for Vision Transformer
Jul 17, 2025Designing effective neural networks is a cornerstone of deep learning, and Neural Architecture Search (NAS) has emerged as a powerful tool for automating this process. Among the existing NAS approaches, Differentiable Architecture Search (DARTS) has gained prominence for its efficiency and ease of use, inspiring numerous advancements. Since the rise of Vision Transformers (ViT), researchers have applied NAS to explore ViT architectures, often focusing on macro-level search spaces and relying on discrete methods like evolutionary algorithms. While these methods ensure reliability, they face challenges in discovering innovative architectural designs, demand extensive computational resources, and are time-intensive. To address these limitations, we introduce Differentiable Architecture Search for Vision Transformer (DASViT), which bridges the gap in differentiable search for ViTs and uncovers novel designs. Experiments show that DASViT delivers architectures that break traditional Transformer encoder designs, outperform ViT-B/16 on multiple datasets, and achieve superior efficiency with fewer parameters and FLOPs.
ConAM: Confidence Attention Module for Convolutional Neural Networks
Oct 27, 2021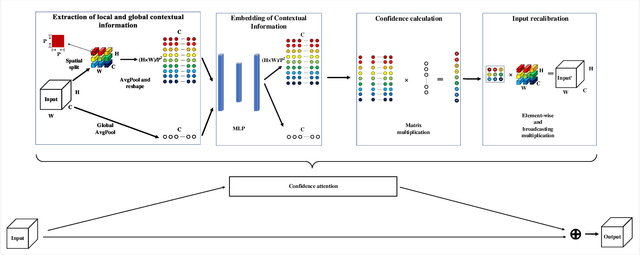

The so-called ``attention'' is an efficient mechanism to improve the performance of convolutional neural networks. It uses contextual information to recalibrate the input to strengthen the propagation of informative features. However, the majority of the attention mechanisms only consider either local or global contextual information, which is singular to extract features. Moreover, many existing mechanisms directly use the contextual information to recalibrate the input, which unilaterally enhances the propagation of the informative features, but does not suppress the useless ones. This paper proposes a new attention mechanism module based on the correlation between local and global contextual information and we name this correlation as confidence. The novel attention mechanism extracts the local and global contextual information simultaneously, and calculates the confidence between them, then uses this confidence to recalibrate the input pixels. The extraction of local and global contextual information increases the diversity of features. The recalibration with confidence suppresses useless information while enhancing the informative one with fewer parameters. We use CIFAR-10 and CIFAR-100 in our experiments and explore the performance of our method's components by sufficient ablation studies. Finally, we compare our method with a various state-of-the-art convolutional neural networks and the results show that our method completely surpasses these models. We implement ConAM with the Python library, Pytorch, and the code and models will be publicly available.
Multi-objective Feature Selection with Missing Data in Classification
Apr 18, 2021
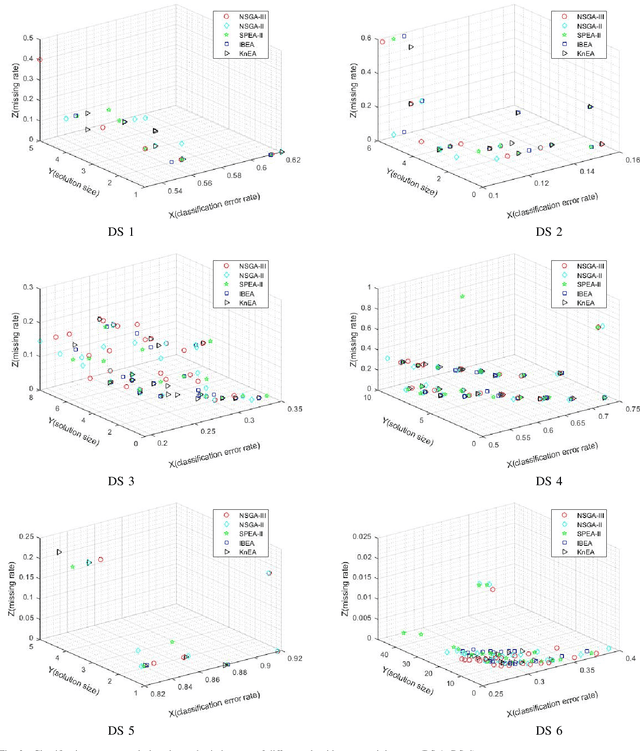

Feature selection (FS) is an important research topic in machine learning. Usually, FS is modelled as a+ bi-objective optimization problem whose objectives are: 1) classification accuracy; 2) number of features. One of the main issues in real-world applications is missing data. Databases with missing data are likely to be unreliable. Thus, FS performed on a data set missing some data is also unreliable. In order to directly control this issue plaguing the field, we propose in this study a novel modelling of FS: we include reliability as the third objective of the problem. In order to address the modified problem, we propose the application of the non-dominated sorting genetic algorithm-III (NSGA-III). We selected six incomplete data sets from the University of California Irvine (UCI) machine learning repository. We used the mean imputation method to deal with the missing data. In the experiments, k-nearest neighbors (K-NN) is used as the classifier to evaluate the feature subsets. Experimental results show that the proposed three-objective model coupled with NSGA-III efficiently addresses the FS problem for the six data sets included in this study.
Multi-Strategy Coevolving Aging Particle Optimization
Oct 11, 2018
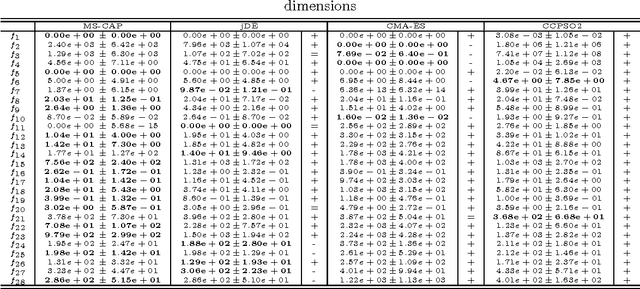

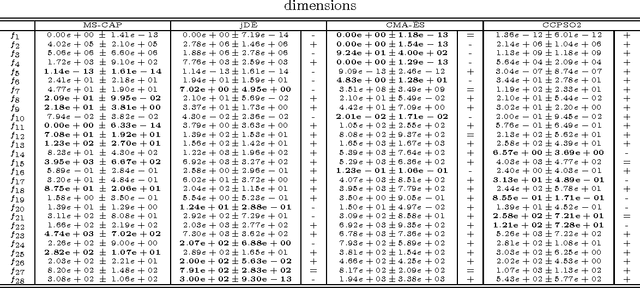
We propose Multi-Strategy Coevolving Aging Particles (MS-CAP), a novel population-based algorithm for black-box optimization. In a memetic fashion, MS-CAP combines two components with complementary algorithm logics. In the first stage, each particle is perturbed independently along each dimension with a progressively shrinking (decaying) radius, and attracted towards the current best solution with an increasing force. In the second phase, the particles are mutated and recombined according to a multi-strategy approach in the fashion of the ensemble of mutation strategies in Differential Evolution. The proposed algorithm is tested, at different dimensionalities, on two complete black-box optimization benchmarks proposed at the Congress on Evolutionary Computation 2010 and 2013. To demonstrate the applicability of the approach, we also test MS-CAP to train a Feedforward Neural Network modelling the kinematics of an 8-link robot manipulator. The numerical results show that MS-CAP, for the setting considered in this study, tends to outperform the state-of-the-art optimization algorithms on a large set of problems, thus resulting in a robust and versatile optimizer.