 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos
Mar 23, 2021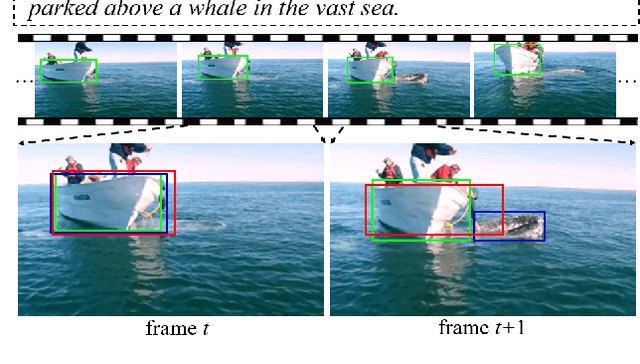
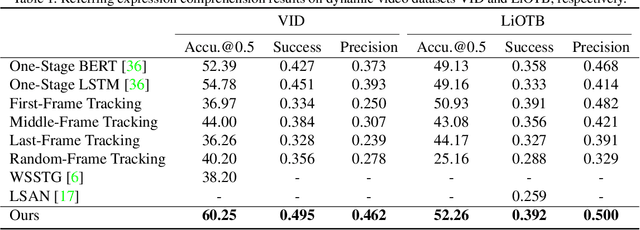
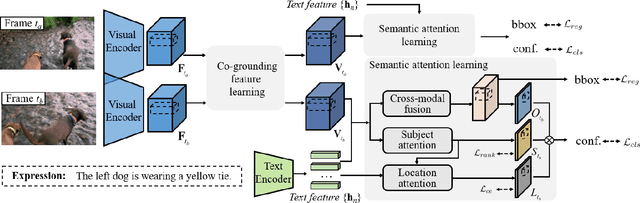
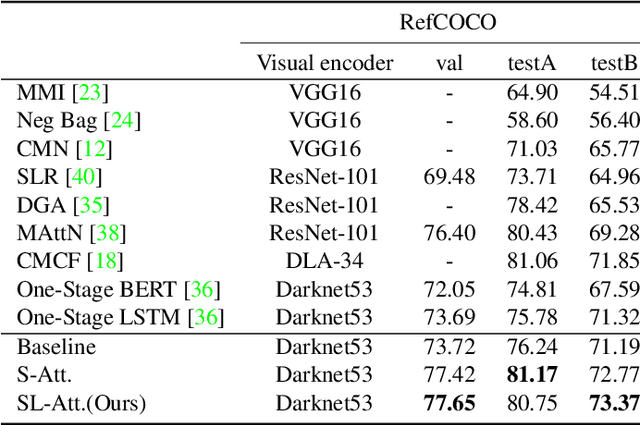
In this paper, we address the problem of referring expression comprehension in videos, which is challenging due to complex expression and scene dynamics. Unlike previous methods which solve the problem in multiple stages (i.e., tracking, proposal-based matching), we tackle the problem from a novel perspective, \textbf{co-grounding}, with an elegant one-stage framework. We enhance the single-frame grounding accuracy by semantic attention learning and improve the cross-frame grounding consistency with co-grounding feature learning. Semantic attention learning explicitly parses referring cues in different attributes to reduce the ambiguity in the complex expression. Co-grounding feature learning boosts visual feature representations by integrating temporal correlation to reduce the ambiguity caused by scene dynamics. Experiment results demonstrate the superiority of our framework on the video grounding datasets VID and LiOTB in generating accurate and stable results across frames. Our model is also applicable to referring expression comprehension in images, illustrated by the improved performance on the RefCOCO dataset. Our project is available at https://sijiesong.github.io/co-grounding.
Progressive residual learning for single image dehazing
Mar 14, 2021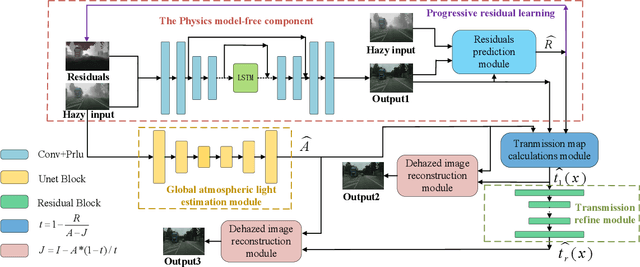



The recent physical model-free dehazing methods have achieved state-of-the-art performances. However, without the guidance of physical models, the performances degrade rapidly when applied to real scenarios due to the unavailable or insufficient data problems. On the other hand, the physical model-based methods have better interpretability but suffer from multi-objective optimizations of parameters, which may lead to sub-optimal dehazing results. In this paper, a progressive residual learning strategy has been proposed to combine the physical model-free dehazing process with reformulated scattering model-based dehazing operations, which enjoys the merits of dehazing methods in both categories. Specifically, the global atmosphere light and transmission maps are interactively optimized with the aid of accurate residual information and preliminary dehazed restorations from the initial physical model-free dehazing process. The proposed method performs favorably against the state-of-the-art methods on public dehazing benchmarks with better model interpretability and adaptivity for complex hazy data.
Graph Force Learning
Mar 07, 2021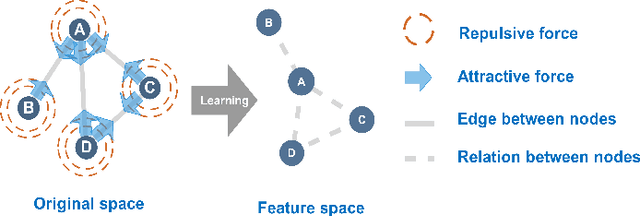
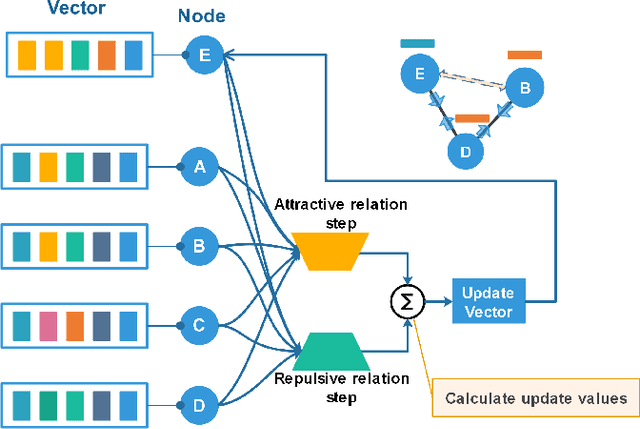
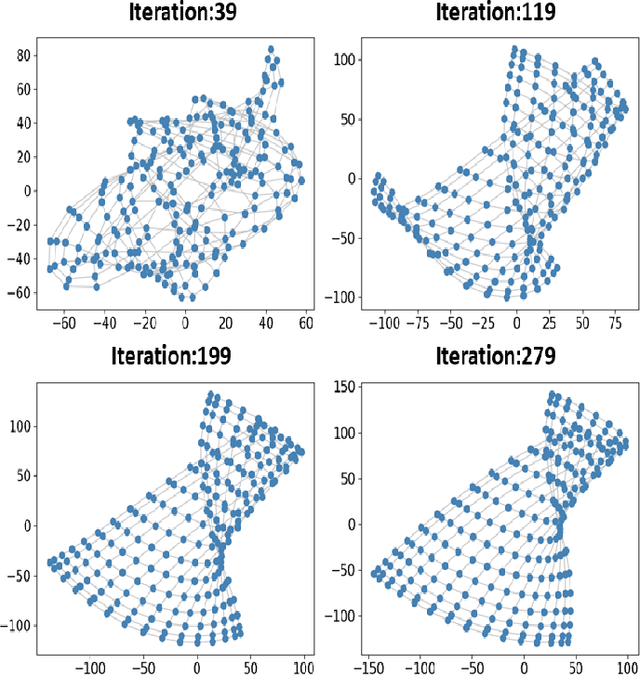
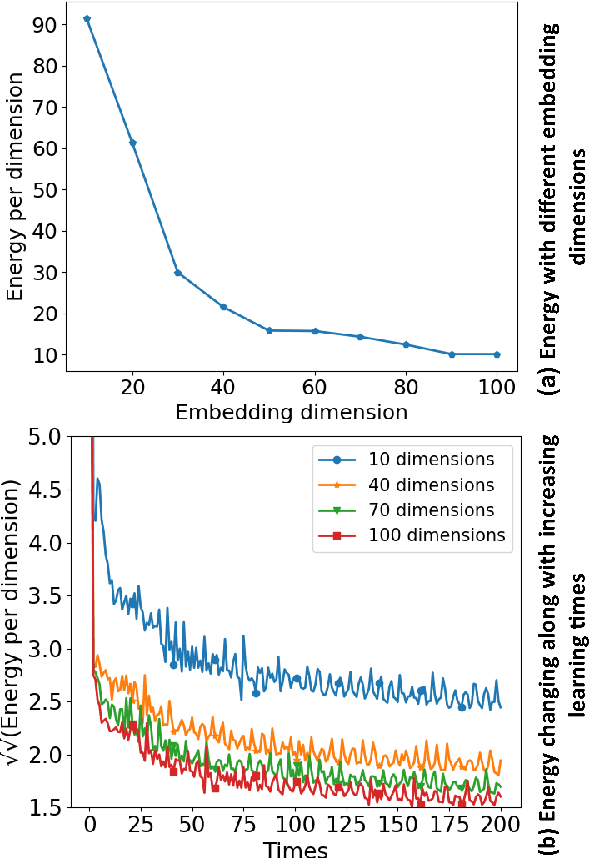
Features representation leverages the great power in network analysis tasks. However, most features are discrete which poses tremendous challenges to effective use. Recently, increasing attention has been paid on network feature learning, which could map discrete features to continued space. Unfortunately, current studies fail to fully preserve the structural information in the feature space due to random negative sampling strategy during training. To tackle this problem, we study the problem of feature learning and novelty propose a force-based graph learning model named GForce inspired by the spring-electrical model. GForce assumes that nodes are in attractive forces and repulsive forces, thus leading to the same representation with the original structural information in feature learning. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed framework. Furthermore, GForce opens up opportunities to use physics models to model node interaction for graph learning.
Progressive Depth Learning for Single Image Dehazing
Feb 21, 2021
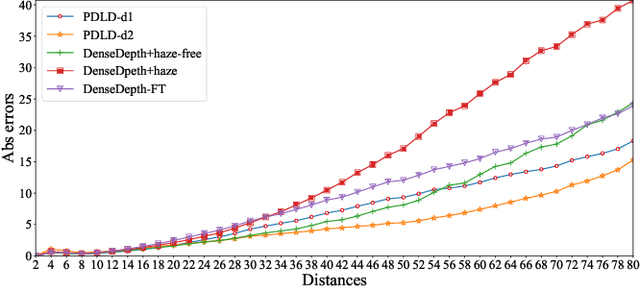
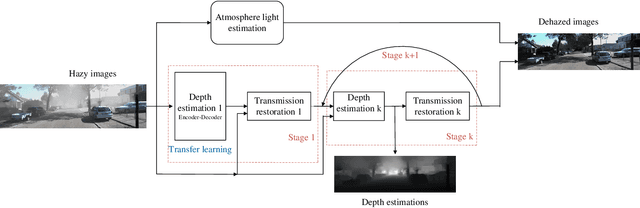

The formulation of the hazy image is mainly dominated by the reflected lights and ambient airlight. Existing dehazing methods often ignore the depth cues and fail in distant areas where heavier haze disturbs the visibility. However, we note that the guidance of the depth information for transmission estimation could remedy the decreased visibility as distances increase. In turn, the good transmission estimation could facilitate the depth estimation for hazy images. In this paper, a deep end-to-end model that iteratively estimates image depths and transmission maps is proposed to perform an effective depth prediction for hazy images and improve the dehazing performance with the guidance of depth information. The image depth and transmission map are progressively refined to better restore the dehazed image. Our approach benefits from explicitly modeling the inner relationship of image depth and transmission map, which is especially effective for distant hazy areas. Extensive results on the benchmarks demonstrate that our proposed network performs favorably against the state-of-the-art dehazing methods in terms of depth estimation and haze removal.
Template-Free Try-on Image Synthesis via Semantic-guided Optimization
Feb 06, 2021
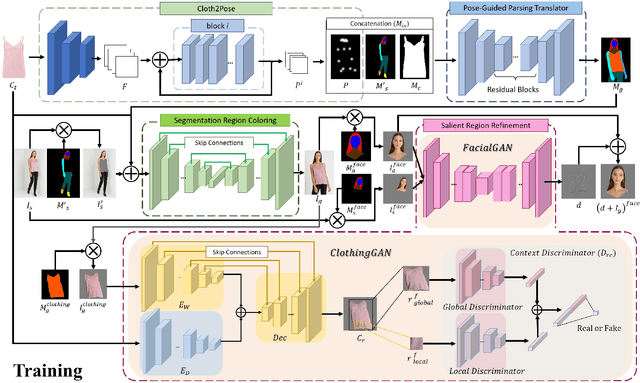


The virtual try-on task is so attractive that it has drawn considerable attention in the field of computer vision. However, presenting the three-dimensional (3D) physical characteristic (e.g., pleat and shadow) based on a 2D image is very challenging. Although there have been several previous studies on 2D-based virtual try-on work, most 1) required user-specified target poses that are not user-friendly and may not be the best for the target clothing, and 2) failed to address some problematic cases, including facial details, clothing wrinkles and body occlusions. To address these two challenges, in this paper, we propose an innovative template-free try-on image synthesis (TF-TIS) network. The TF-TIS first synthesizes the target pose according to the user-specified in-shop clothing. Afterward, given an in-shop clothing image, a user image, and a synthesized pose, we propose a novel model for synthesizing a human try-on image with the target clothing in the best fitting pose. The qualitative and quantitative experiments both indicate that the proposed TF-TIS outperforms the state-of-the-art methods, especially for difficult cases.
MS$^2$L: Multi-Task Self-Supervised Learning for Skeleton Based Action Recognition
Oct 14, 2020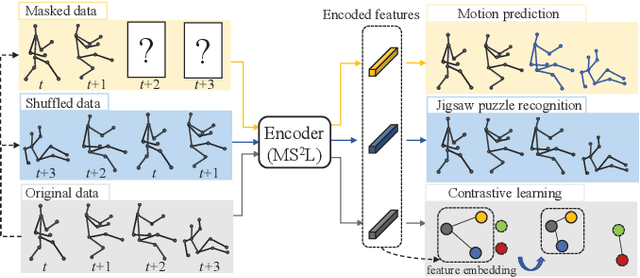

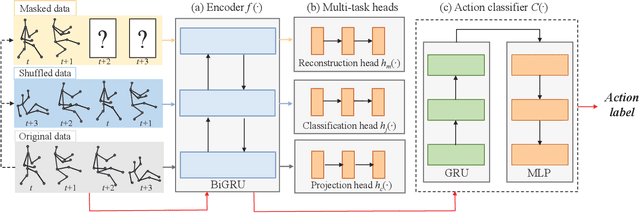
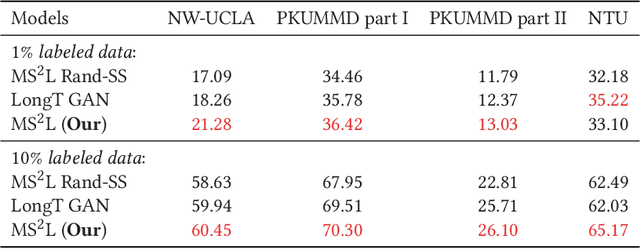
In this paper, we address self-supervised representation learning from human skeletons for action recognition. Previous methods, which usually learn feature presentations from a single reconstruction task, may come across the overfitting problem, and the features are not generalizable for action recognition. Instead, we propose to integrate multiple tasks to learn more general representations in a self-supervised manner. To realize this goal, we integrate motion prediction, jigsaw puzzle recognition, and contrastive learning to learn skeleton features from different aspects. Skeleton dynamics can be modeled through motion prediction by predicting the future sequence. And temporal patterns, which are critical for action recognition, are learned through solving jigsaw puzzles. We further regularize the feature space by contrastive learning. Besides, we explore different training strategies to utilize the knowledge from self-supervised tasks for action recognition. We evaluate our multi-task self-supervised learning approach with action classifiers trained under different configurations, including unsupervised, semi-supervised and fully-supervised settings. Our experiments on the NW-UCLA, NTU RGB+D, and PKUMMD datasets show remarkable performance for action recognition, demonstrating the superiority of our method in learning more discriminative and general features. Our project website is available at https://langlandslin.github.io/projects/MSL/.
From Design Draft to Real Attire: Unaligned Fashion Image Translation
Sep 16, 2020

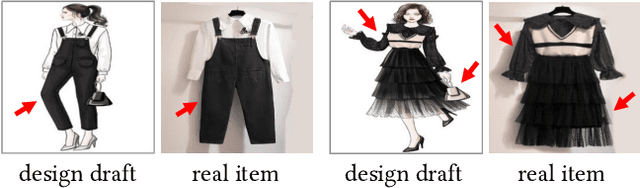
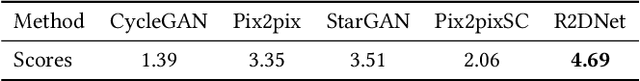
Fashion manipulation has attracted growing interest due to its great application value, which inspires many researches towards fashion images. However, little attention has been paid to fashion design draft. In this paper, we study a new unaligned translation problem between design drafts and real fashion items, whose main challenge lies in the huge misalignment between the two modalities. We first collect paired design drafts and real fashion item images without pixel-wise alignment. To solve the misalignment problem, our main idea is to train a sampling network to adaptively adjust the input to an intermediate state with structure alignment to the output. Moreover, built upon the sampling network, we present design draft to real fashion item translation network (D2RNet), where two separate translation streams that focus on texture and shape, respectively, are combined tactfully to get both benefits. D2RNet is able to generate realistic garments with both texture and shape consistency to their design drafts. We show that this idea can be effectively applied to the reverse translation problem and present R2DNet accordingly. Extensive experiments on unaligned fashion design translation demonstrate the superiority of our method over state-of-the-art methods. Our project website is available at: https://victoriahy.github.io/MM2020/ .
Understanding the Advisor-advisee Relationship via Scholarly Data Analysis
Aug 20, 2020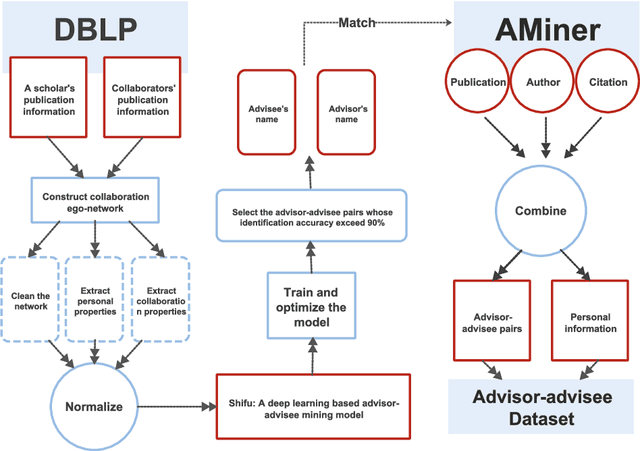


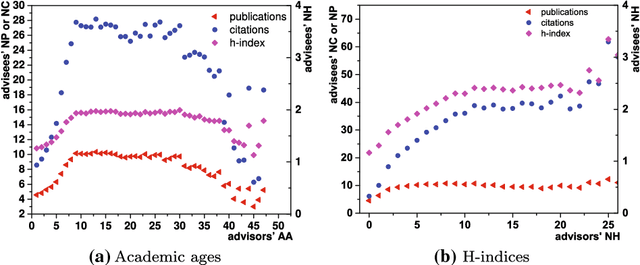
Advisor-advisee relationship is important in academic networks due to its universality and necessity. Despite the increasing desire to analyze the career of newcomers, however, the outcomes of different collaboration patterns between advisors and advisees remain unknown. The purpose of this paper is to find out the correlation between advisors' academic characteristics and advisees' academic performance in Computer Science. Employing both quantitative and qualitative analysis, we find that with the increase of advisors' academic age, advisees' performance experiences an initial growth, follows a sustaining stage, and finally ends up with a declining trend. We also discover the phenomenon that accomplished advisors can bring up skilled advisees. We explore the conclusion from two aspects: (1) Advisees mentored by advisors with high academic level have better academic performance than the rest; (2) Advisors with high academic level can raise their advisees' h-index ranking. This work provides new insights on promoting our understanding of the relationship between advisors' academic characteristics and advisees' performance, as well as on advisor choosing.
Shifu2: A Network Representation Learning Based Model for Advisor-advisee Relationship Mining
Aug 17, 2020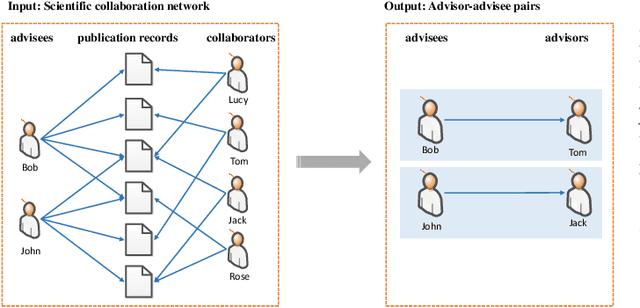
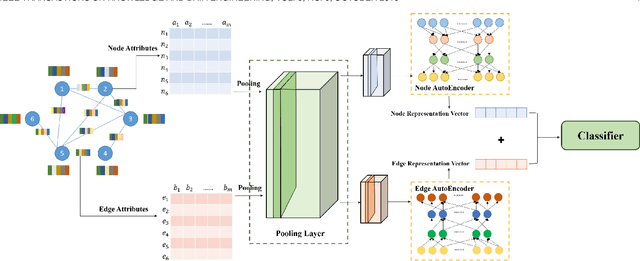


The advisor-advisee relationship represents direct knowledge heritage, and such relationship may not be readily available from academic libraries and search engines. This work aims to discover advisor-advisee relationships hidden behind scientific collaboration networks. For this purpose, we propose a novel model based on Network Representation Learning (NRL), namely Shifu2, which takes the collaboration network as input and the identified advisor-advisee relationship as output. In contrast to existing NRL models, Shifu2 considers not only the network structure but also the semantic information of nodes and edges. Shifu2 encodes nodes and edges into low-dimensional vectors respectively, both of which are then utilized to identify advisor-advisee relationships. Experimental results illustrate improved stability and effectiveness of the proposed model over state-of-the-art methods. In addition, we generate a large-scale academic genealogy dataset by taking advantage of Shifu2.
DINE: A Framework for Deep Incomplete Network Embedding
Aug 09, 2020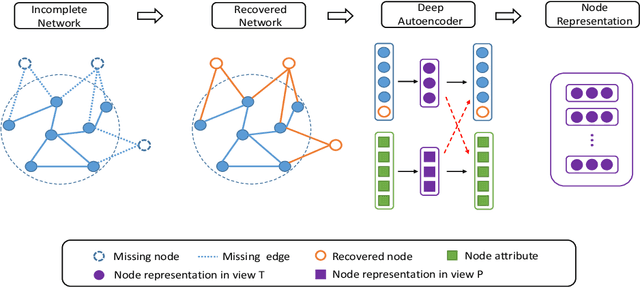


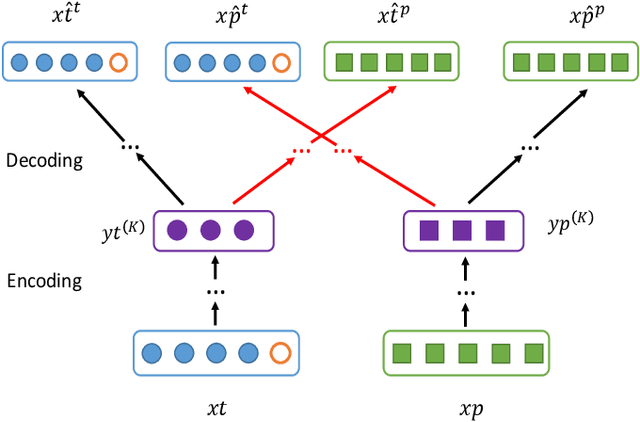
Network representation learning (NRL) plays a vital role in a variety of tasks such as node classification and link prediction. It aims to learn low-dimensional vector representations for nodes based on network structures or node attributes. While embedding techniques on complete networks have been intensively studied, in real-world applications, it is still a challenging task to collect complete networks. To bridge the gap, in this paper, we propose a Deep Incomplete Network Embedding method, namely DINE. Specifically, we first complete the missing part including both nodes and edges in a partially observable network by using the expectation-maximization framework. To improve the embedding performance, we consider both network structures and node attributes to learn node representations. Empirically, we evaluate DINE over three networks on multi-label classification and link prediction tasks. The results demonstrate the superiority of our proposed approach compared against state-of-the-art baselines.
* 12 pages, 3 figures