 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Data-Dependent Transform for Learned Image Compression
Mar 30, 2022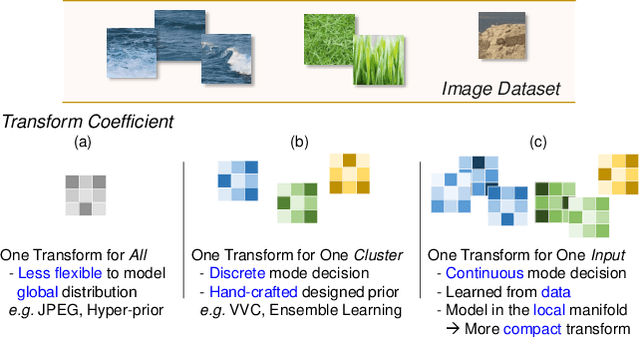
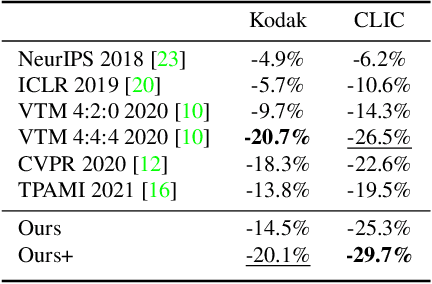
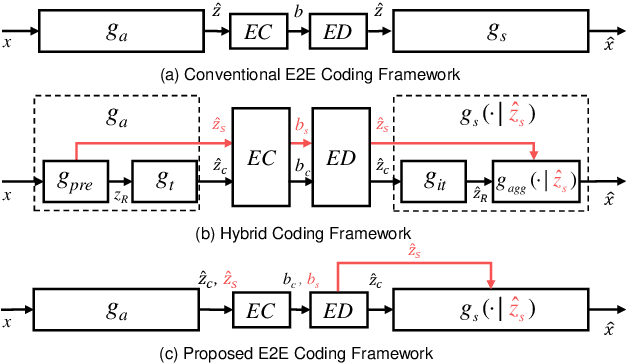
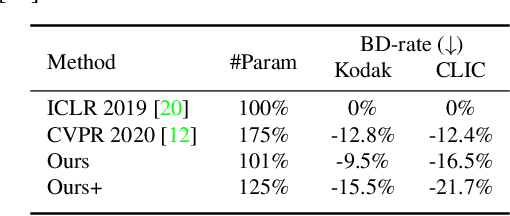
Learned image compression has achieved great success due to its excellent modeling capacity, but seldom further considers the Rate-Distortion Optimization (RDO) of each input image. To explore this potential in the learned codec, we make the first attempt to build a neural data-dependent transform and introduce a continuous online mode decision mechanism to jointly optimize the coding efficiency for each individual image. Specifically, apart from the image content stream, we employ an additional model stream to generate the transform parameters at the decoder side. The presence of a model stream enables our model to learn more abstract neural-syntax, which helps cluster the latent representations of images more compactly. Beyond the transform stage, we also adopt neural-syntax based post-processing for the scenarios that require higher quality reconstructions regardless of extra decoding overhead. Moreover, the involvement of the model stream further makes it possible to optimize both the representation and the decoder in an online way, i.e. RDO at the testing time. It is equivalent to a continuous online mode decision, like coding modes in the traditional codecs, to improve the coding efficiency based on the individual input image. The experimental results show the effectiveness of the proposed neural-syntax design and the continuous online mode decision mechanism, demonstrating the superiority of our method in coding efficiency compared to the latest conventional standard Versatile Video Coding (VVC) and other state-of-the-art learning-based methods.
Deep Graph Learning for Anomalous Citation Detection
Feb 23, 2022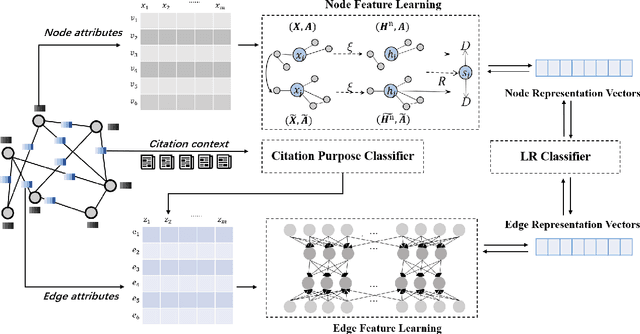
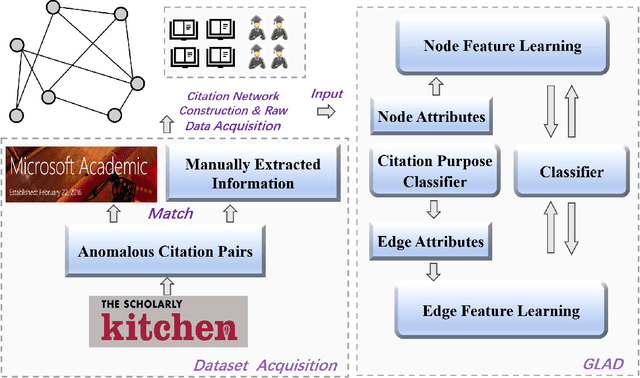
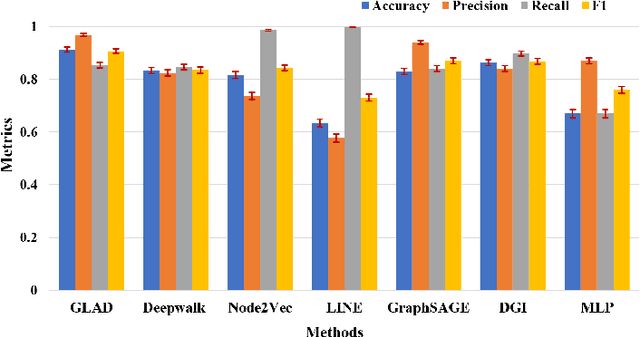
Anomaly detection is one of the most active research areas in various critical domains, such as healthcare, fintech, and public security. However, little attention has been paid to scholarly data, i.e., anomaly detection in a citation network. Citation is considered as one of the most crucial metrics to evaluate the impact of scientific research, which may be gamed in multiple ways. Therefore, anomaly detection in citation networks is of significant importance to identify manipulation and inflation of citations. To address this open issue, we propose a novel deep graph learning model, namely GLAD (Graph Learning for Anomaly Detection), to identify anomalies in citation networks. GLAD incorporates text semantic mining to network representation learning by adding both node attributes and link attributes via graph neural networks. It exploits not only the relevance of citation contents but also hidden relationships between papers. Within the GLAD framework, we propose an algorithm called CPU (Citation PUrpose) to discover the purpose of citation based on citation texts. The performance of GLAD is validated through a simulated anomalous citation dataset. Experimental results demonstrate the effectiveness of GLAD on the anomalous citation detection task.
Web of Scholars: A Scholar Knowledge Graph
Feb 23, 2022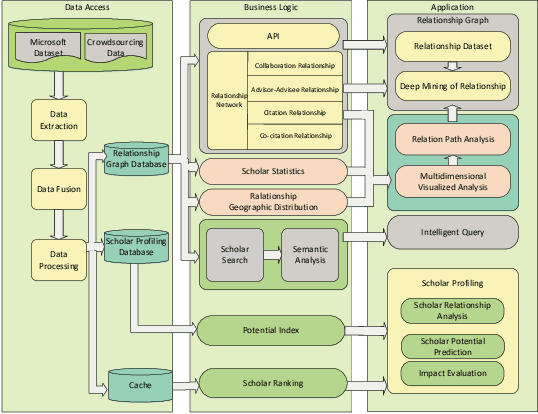
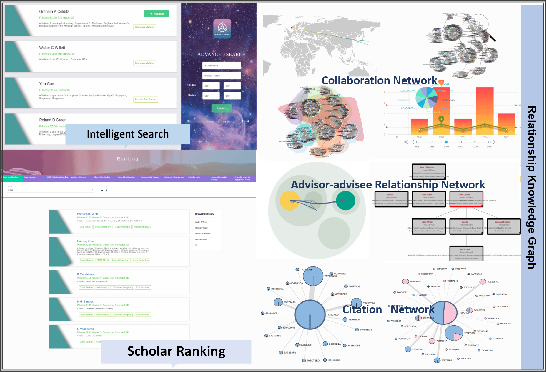
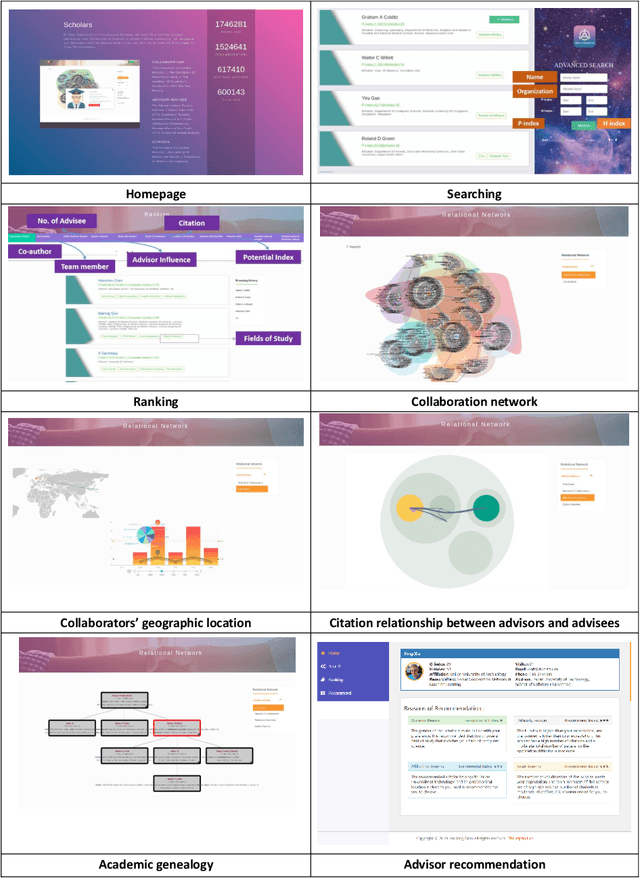
In this work, we demonstrate a novel system, namely Web of Scholars, which integrates state-of-the-art mining techniques to search, mine, and visualize complex networks behind scholars in the field of Computer Science. Relying on the knowledge graph, it provides services for fast, accurate, and intelligent semantic querying as well as powerful recommendations. In addition, in order to realize information sharing, it provides an open API to be served as the underlying architecture for advanced functions. Web of Scholars takes advantage of knowledge graph, which means that it will be able to access more knowledge if more search exist. It can be served as a useful and interoperable tool for scholars to conduct in-depth analysis within Science of Science.
Towards Low Light Enhancement with RAW Images
Dec 28, 2021



In this paper, we make the first benchmark effort to elaborate on the superiority of using RAW images in the low light enhancement and develop a novel alternative route to utilize RAW images in a more flexible and practical way. Inspired by a full consideration on the typical image processing pipeline, we are inspired to develop a new evaluation framework, Factorized Enhancement Model (FEM), which decomposes the properties of RAW images into measurable factors and provides a tool for exploring how properties of RAW images affect the enhancement performance empirically. The empirical benchmark results show that the Linearity of data and Exposure Time recorded in meta-data play the most critical role, which brings distinct performance gains in various measures over the approaches taking the sRGB images as input. With the insights obtained from the benchmark results in mind, a RAW-guiding Exposure Enhancement Network (REENet) is developed, which makes trade-offs between the advantages and inaccessibility of RAW images in real applications in a way of using RAW images only in the training phase. REENet projects sRGB images into linear RAW domains to apply constraints with corresponding RAW images to reduce the difficulty of modeling training. After that, in the testing phase, our REENet does not rely on RAW images. Experimental results demonstrate not only the superiority of REENet to state-of-the-art sRGB-based methods and but also the effectiveness of the RAW guidance and all components.
Deep Video Coding with Dual-Path Generative Adversarial Network
Nov 29, 2021

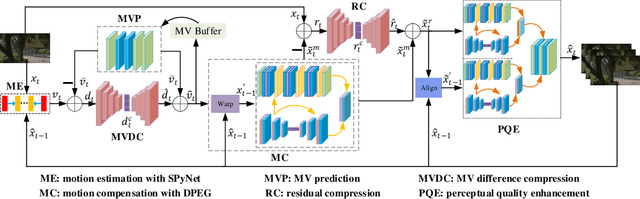
The deep-learning-based video coding has attracted substantial attention for its great potential to squeeze out the spatial-temporal redundancies of video sequences. This paper proposes an efficient codec namely dual-path generative adversarial network-based video codec (DGVC). First, we propose a dual-path enhancement with generative adversarial network (DPEG) to reconstruct the compressed video details. The DPEG consists of an $\alpha$-path of auto-encoder and convolutional long short-term memory (ConvLSTM), which facilitates the structure feature reconstruction with a large receptive field and multi-frame references, and a $\beta$-path of residual attention blocks, which facilitates the reconstruction of local texture features. Both paths are fused and co-trained by a generative-adversarial process. Second, we reuse the DPEG network in both motion compensation and quality enhancement modules, which are further combined with motion estimation and entropy coding modules in our DGVC framework. Third, we employ a joint training of deep video compression and enhancement to further improve the rate-distortion (RD) performance. Compared with x265 LDP very fast mode, our DGVC reduces the average bit-per-pixel (bpp) by 39.39%/54.92% at the same PSNR/MS-SSIM, which outperforms the state-of-the art deep video codecs by a considerable margin.
Video Coding for Machine: Compact Visual Representation Compression for Intelligent Collaborative Analytics
Oct 18, 2021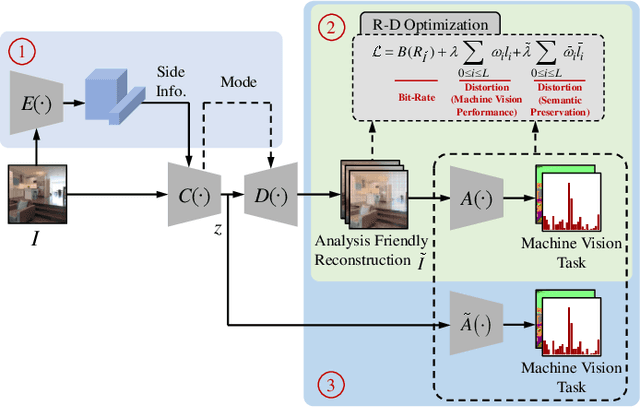
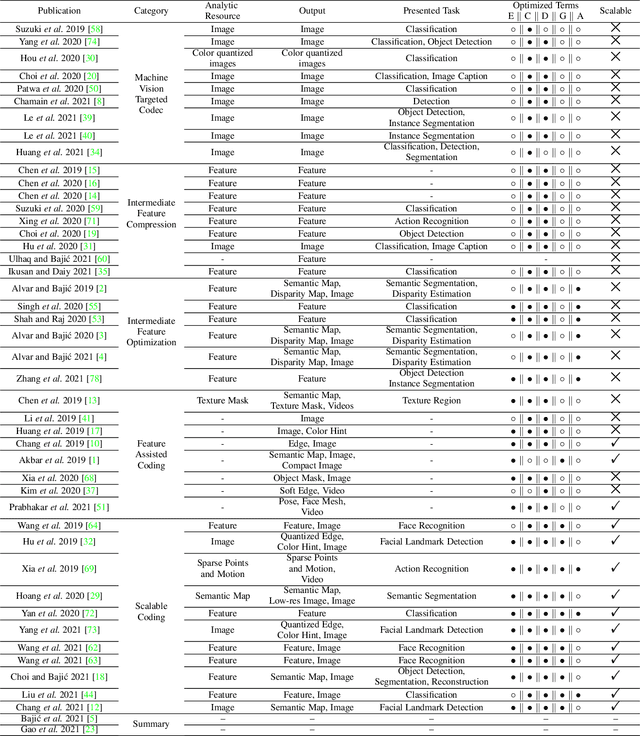
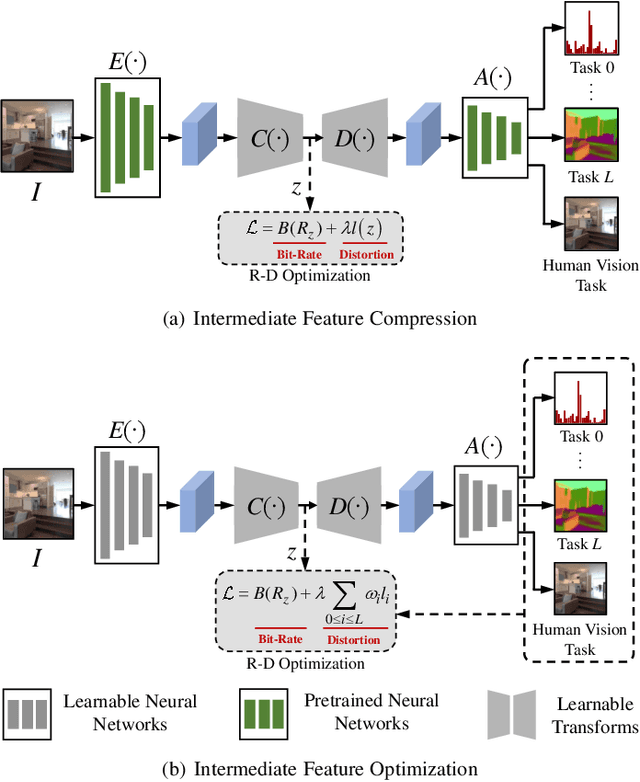
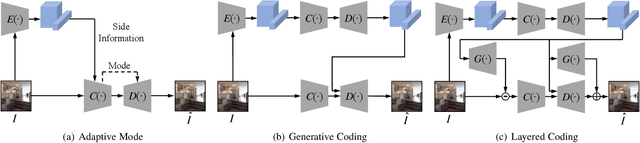
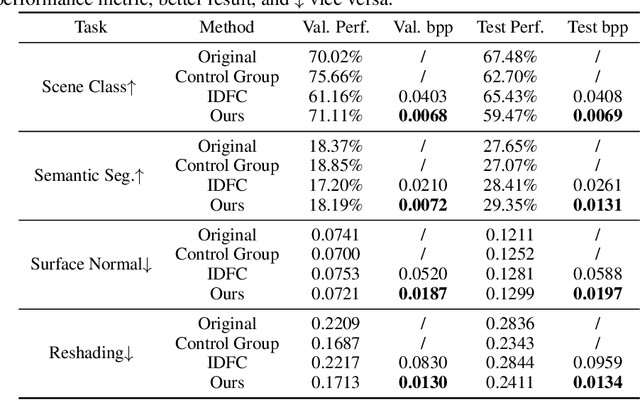
Video Coding for Machines (VCM) is committed to bridging to an extent separate research tracks of video/image compression and feature compression, and attempts to optimize compactness and efficiency jointly from a unified perspective of high accuracy machine vision and full fidelity human vision. In this paper, we summarize VCM methodology and philosophy based on existing academia and industrial efforts. The development of VCM follows a general rate-distortion optimization, and the categorization of key modules or techniques is established. From previous works, it is demonstrated that, although existing works attempt to reveal the nature of scalable representation in bits when dealing with machine and human vision tasks, there remains a rare study in the generality of low bit rate representation, and accordingly how to support a variety of visual analytic tasks. Therefore, we investigate a novel visual information compression for the analytics taxonomy problem to strengthen the capability of compact visual representations extracted from multiple tasks for visual analytics. A new perspective of task relationships versus compression is revisited. By keeping in mind the transferability among different machine vision tasks (e.g. high-level semantic and mid-level geometry-related), we aim to support multiple tasks jointly at low bit rates. In particular, to narrow the dimensionality gap between neural network generated features extracted from pixels and a variety of machine vision features/labels (e.g. scene class, segmentation labels), a codebook hyperprior is designed to compress the neural network-generated features. As demonstrated in our experiments, this new hyperprior model is expected to improve feature compression efficiency by estimating the signal entropy more accurately, which enables further investigation of the granularity of abstracting compact features among different tasks.
SalienTrack: providing salient information for semi-automated self-tracking feedback with model explanations
Sep 21, 2021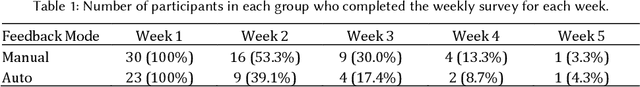
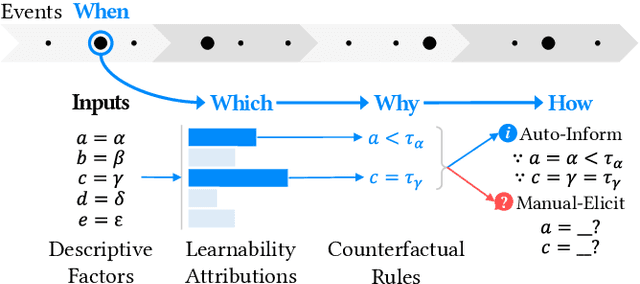
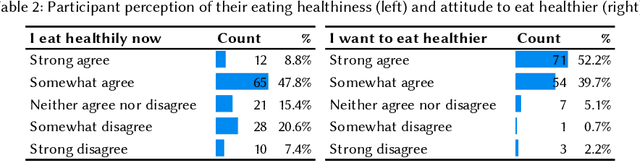
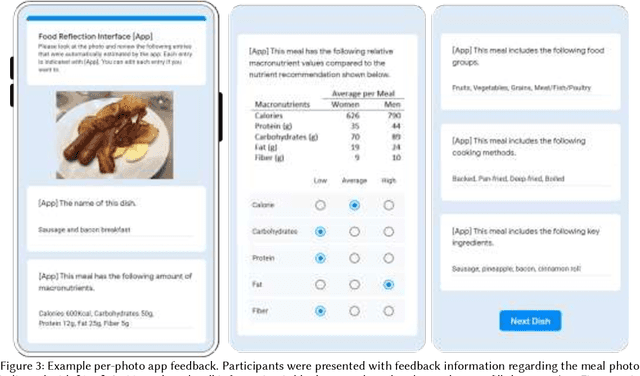
Self-tracking can improve people's awareness of their unhealthy behaviors to provide insights towards behavior change. Prior work has explored how self-trackers reflect on their logged data, but it remains unclear how much they learn from the tracking feedback, and which information is more useful. Indeed, the feedback can still be overwhelming, and making it concise can improve learning by increasing focus and reducing interpretation burden. We conducted a field study of mobile food logging with two feedback modes (manual journaling and automatic annotation of food images) and identified learning differences regarding nutrition, assessment, behavioral, and contextual information. We propose a Self-Tracking Feedback Saliency Framework to define when to provide feedback, on which specific information, why those details, and how to present them (as manual inquiry or automatic feedback). We propose SalienTrack to implement these requirements. Using the data collected from the user study, we trained a machine learning model to predict whether a user would learn from each tracked event. Using explainable AI (XAI) techniques, we identified the most salient features per instance and why they lead to positive learning outcomes. We discuss implications for learnability in self-tracking, and how adding model explainability expands opportunities for improving feedback experience.
Revisit Visual Representation in Analytics Taxonomy: A Compression Perspective
Jun 16, 2021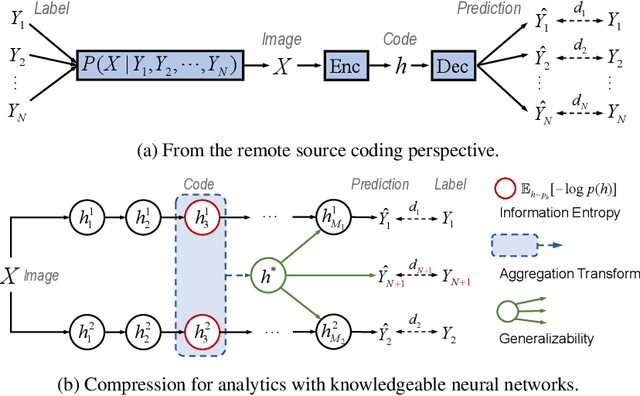
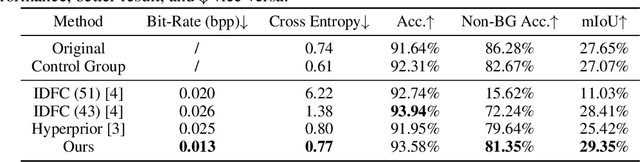
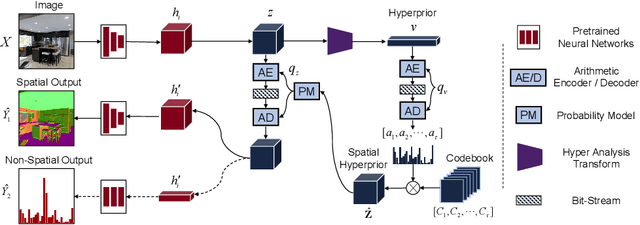
Visual analytics have played an increasingly critical role in the Internet of Things, where massive visual signals have to be compressed and fed into machines. But facing such big data and constrained bandwidth capacity, existing image/video compression methods lead to very low-quality representations, while existing feature compression techniques fail to support diversified visual analytics applications/tasks with low-bit-rate representations. In this paper, we raise and study the novel problem of supporting multiple machine vision analytics tasks with the compressed visual representation, namely, the information compression problem in analytics taxonomy. By utilizing the intrinsic transferability among different tasks, our framework successfully constructs compact and expressive representations at low bit-rates to support a diversified set of machine vision tasks, including both high-level semantic-related tasks and mid-level geometry analytic tasks. In order to impose compactness in the representations, we propose a codebook-based hyperprior, which helps map the representation into a low-dimensional manifold. As it well fits the signal structure of the deep visual feature, it facilitates more accurate entropy estimation, and results in higher compression efficiency. With the proposed framework and the codebook-based hyperprior, we further investigate the relationship of different task features owning different levels of abstraction granularity. Experimental results demonstrate that with the proposed scheme, a set of diversified tasks can be supported at a significantly lower bit-rate, compared with existing compression schemes.
Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight
Jun 08, 2021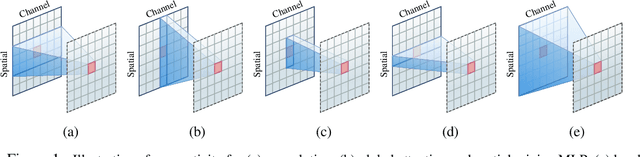
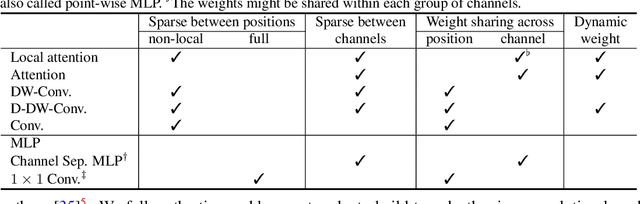
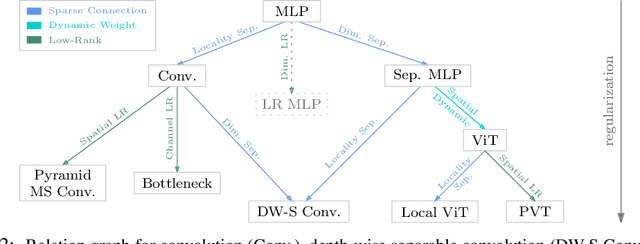
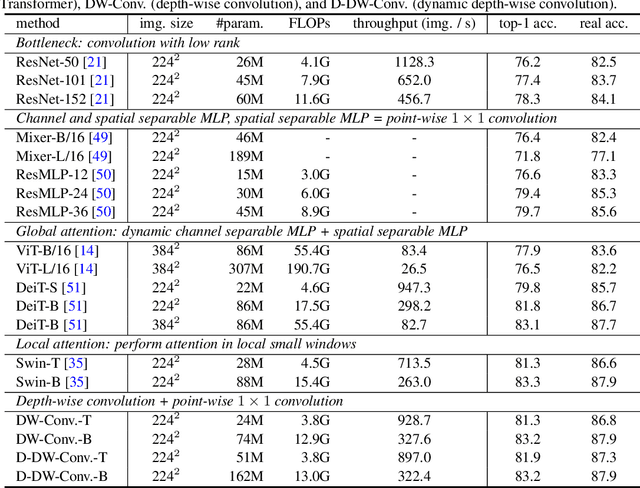
Vision Transformer (ViT) attains state-of-the-art performance in visual recognition, and the variant, Local Vision Transformer, makes further improvements. The major component in Local Vision Transformer, local attention, performs the attention separately over small local windows. We rephrase local attention as a channel-wise locally-connected layer and analyze it from two network regularization manners, sparse connectivity and weight sharing, as well as weight computation. Sparse connectivity: there is no connection across channels, and each position is connected to the positions within a small local window. Weight sharing: the connection weights for one position are shared across channels or within each group of channels. Dynamic weight: the connection weights are dynamically predicted according to each image instance. We point out that local attention resembles depth-wise convolution and its dynamic version in sparse connectivity. The main difference lies in weight sharing - depth-wise convolution shares connection weights (kernel weights) across spatial positions. We empirically observe that the models based on depth-wise convolution and the dynamic variant with lower computation complexity perform on-par with or sometimes slightly better than Swin Transformer, an instance of Local Vision Transformer, for ImageNet classification, COCO object detection and ADE semantic segmentation. These observations suggest that Local Vision Transformer takes advantage of two regularization forms and dynamic weight to increase the network capacity.
HLA-Face: Joint High-Low Adaptation for Low Light Face Detection
Apr 05, 2021
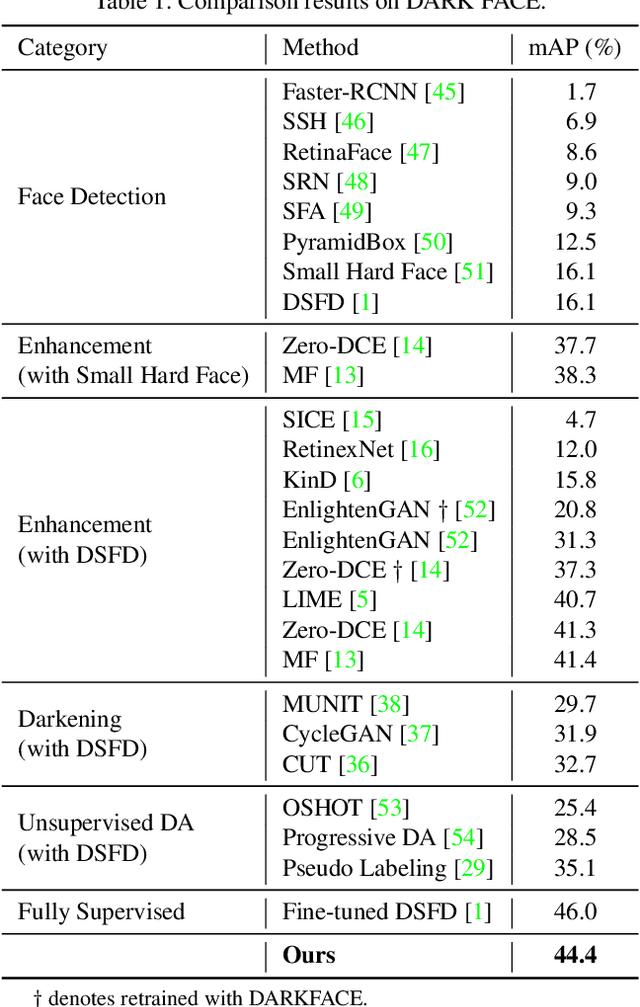
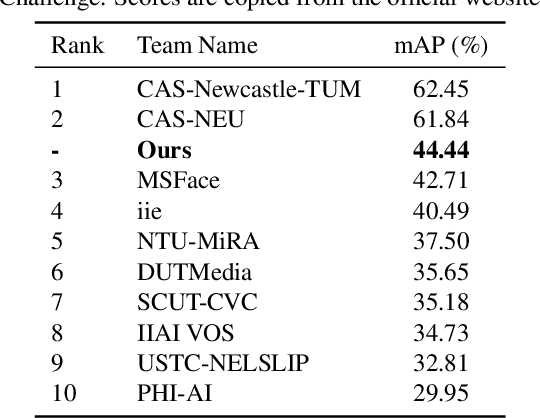
Face detection in low light scenarios is challenging but vital to many practical applications, e.g., surveillance video, autonomous driving at night. Most existing face detectors heavily rely on extensive annotations, while collecting data is time-consuming and laborious. To reduce the burden of building new datasets for low light conditions, we make full use of existing normal light data and explore how to adapt face detectors from normal light to low light. The challenge of this task is that the gap between normal and low light is too huge and complex for both pixel-level and object-level. Therefore, most existing low-light enhancement and adaptation methods do not achieve desirable performance. To address the issue, we propose a joint High-Low Adaptation (HLA) framework. Through a bidirectional low-level adaptation and multi-task high-level adaptation scheme, our HLA-Face outperforms state-of-the-art methods even without using dark face labels for training. Our project is publicly available at https://daooshee.github.io/HLA-Face-Website/