 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated co-design of high-performance thermodynamic cycles via graph-based hierarchical reinforcement learning
Apr 14, 2026Thermodynamic cycles are pivotal in determining the efficacy of energy conversion systems. Traditional design methodologies, which rely on expert knowledge or exhaustive enumeration, are inefficient and lack scalability, thereby constraining the discovery of high-performance cycles. In this study, we introduce a graph-based hierarchical reinforcement learning approach for the co-design of structure parameters in thermodynamic cycles. These cycles are encoded as graphs, with components and connections depicted as nodes and edges, adhering to grammatical constraints. A deep learning-based thermophysical surrogate facilitates stable graph decoding and the simultaneous resolution of global parameters. Building on this foundation, we develop a hierarchical reinforcement learning framework wherein a high-level manager explores structural evolution and proposes candidate configurations, whereas a low-level worker optimizes parameters and provides performance rewards to steer the search towards high-performance regions. By integrating graph representation, thermophysical surrogate, and manager-worker learning, this method establishes a fully automated pipeline for encoding, decoding, and co-optimization. Using heat pump and heat engine cycles as case studies, the results demonstrate that the proposed method not only replicates classical cycle configurations but also identifies 18 and 21 novel heat pump and heat engine cycles, respectively. Relative to classical cycles, the novel configurations exhibit performance improvements of 4.6% and 133.3%, respectively, surpassing the traditional designs. This method effectively balances efficiency with broad applicability, providing a practical and scalable intelligent alternative to expert-driven thermodynamic cycle design.
PRBench: End-to-end Paper Reproduction in Physics Research
Mar 29, 2026AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
Towards Fair and Rigorous Evaluations: Hyperparameter Optimization for Top-N Recommendation Task with Implicit Feedback
Aug 14, 2024The widespread use of the internet has led to an overwhelming amount of data, which has resulted in the problem of information overload. Recommender systems have emerged as a solution to this problem by providing personalized recommendations to users based on their preferences and historical data. However, as recommendation models become increasingly complex, finding the best hyperparameter combination for different models has become a challenge. The high-dimensional hyperparameter search space poses numerous challenges for researchers, and failure to disclose hyperparameter settings may impede the reproducibility of research results. In this paper, we investigate the Top-N implicit recommendation problem and focus on optimizing the benchmark recommendation algorithm commonly used in comparative experiments using hyperparameter optimization algorithms. We propose a research methodology that follows the principles of a fair comparison, employing seven types of hyperparameter search algorithms to fine-tune six common recommendation algorithms on three datasets. We have identified the most suitable hyperparameter search algorithms for various recommendation algorithms on different types of datasets as a reference for later study. This study contributes to algorithmic research in recommender systems based on hyperparameter optimization, providing a fair basis for comparison.
Deep Graph Learning for Anomalous Citation Detection
Feb 23, 2022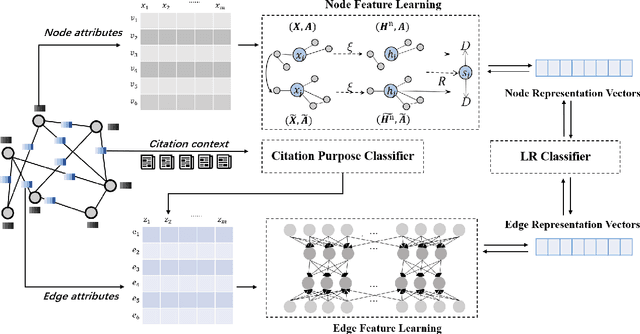
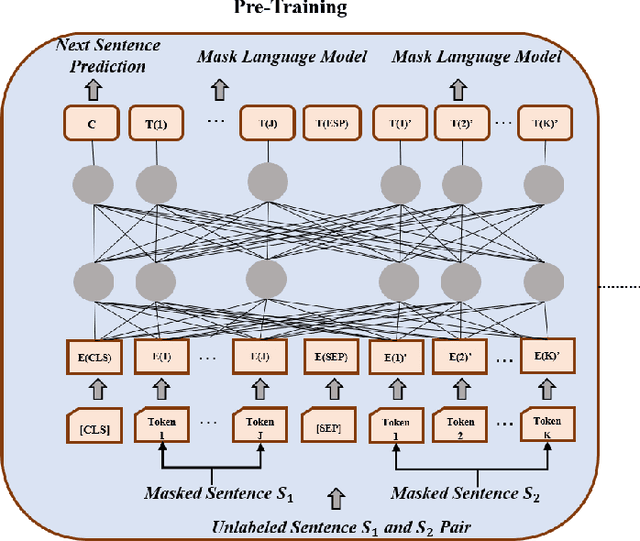
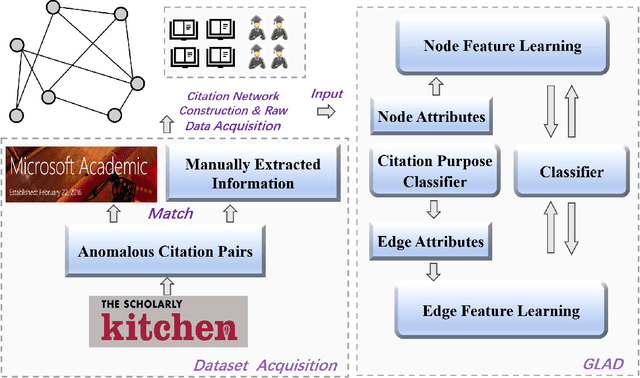
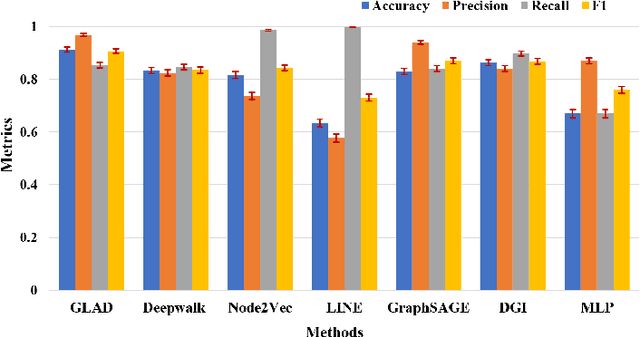
Anomaly detection is one of the most active research areas in various critical domains, such as healthcare, fintech, and public security. However, little attention has been paid to scholarly data, i.e., anomaly detection in a citation network. Citation is considered as one of the most crucial metrics to evaluate the impact of scientific research, which may be gamed in multiple ways. Therefore, anomaly detection in citation networks is of significant importance to identify manipulation and inflation of citations. To address this open issue, we propose a novel deep graph learning model, namely GLAD (Graph Learning for Anomaly Detection), to identify anomalies in citation networks. GLAD incorporates text semantic mining to network representation learning by adding both node attributes and link attributes via graph neural networks. It exploits not only the relevance of citation contents but also hidden relationships between papers. Within the GLAD framework, we propose an algorithm called CPU (Citation PUrpose) to discover the purpose of citation based on citation texts. The performance of GLAD is validated through a simulated anomalous citation dataset. Experimental results demonstrate the effectiveness of GLAD on the anomalous citation detection task.
Faster Matrix Completion Using Randomized SVD
Oct 16, 2018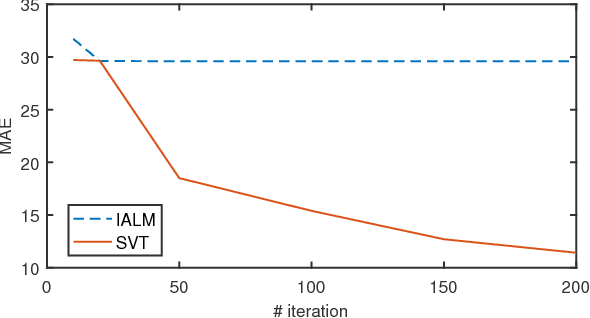

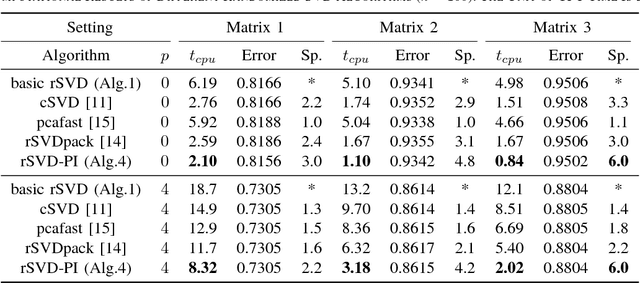

Matrix completion is a widely used technique for image inpainting and personalized recommender system, etc. In this work, we focus on accelerating the matrix completion using faster randomized singular value decomposition (rSVD). Firstly, two fast randomized algorithms (rSVD-PI and rSVD- BKI) are proposed for handling sparse matrix. They make use of an eigSVD procedure and several accelerating skills. Then, with the rSVD-BKI algorithm and a new subspace recycling technique, we accelerate the singular value thresholding (SVT) method in [1] to realize faster matrix completion. Experiments show that the proposed rSVD algorithms can be 6X faster than the basic rSVD algorithm [2] while keeping same accuracy. For image inpainting and movie-rating estimation problems, the proposed accelerated SVT algorithm consumes 15X and 8X less CPU time than the methods using svds and lansvd respectively, without loss of accuracy.
Fast Randomized PCA for Sparse Data
Oct 16, 2018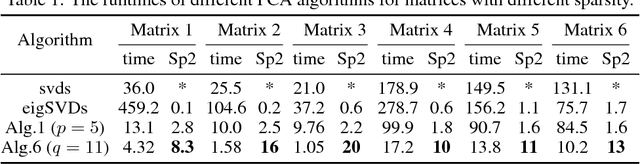
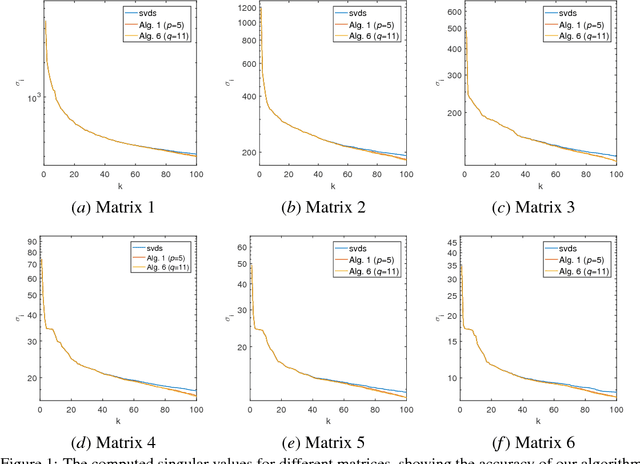
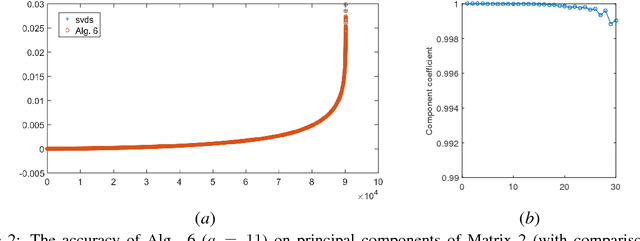
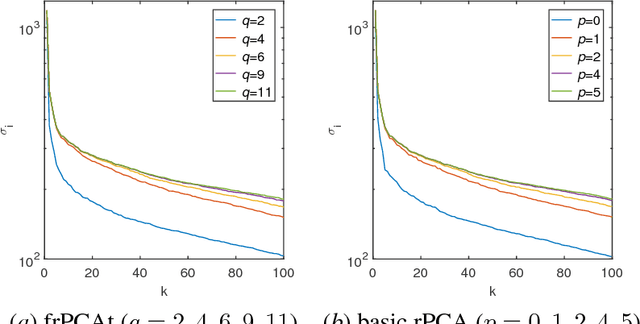
Principal component analysis (PCA) is widely used for dimension reduction and embedding of real data in social network analysis, information retrieval, and natural language processing, etc. In this work we propose a fast randomized PCA algorithm for processing large sparse data. The algorithm has similar accuracy to the basic randomized SVD (rPCA) algorithm (Halko et al., 2011), but is largely optimized for sparse data. It also has good flexibility to trade off runtime against accuracy for practical usage. Experiments on real data show that the proposed algorithm is up to 9.1X faster than the basic rPCA algorithm without accuracy loss, and is up to 20X faster than the svds in Matlab with little error. The algorithm computes the first 100 principal components of a large information retrieval data with 12,869,521 persons and 323,899 keywords in less than 400 seconds on a 24-core machine, while all conventional methods fail due to the out-of-memory issue.