 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUME: A Unified Meta-Generalization Framework for Cross-Domain ETA
May 31, 2026Accurate Estimated Time of Arrival (ETA) prediction on checkout page is crucial in instant logistics for enhancing user satisfaction, optimizing dispatching, and controlling operational costs. In international on-demand delivery platforms, where ETA data originates from diverse countries or regions with different patterns, multi-domain modeling is of great importance and has been widely adopted. However, existing methods still face three critical challenges in real-world deployment. First, current multi-domain models struggle to generalize to completely unseen domains, failing to achieve zero-shot prediction during the initial cold-start phase. Second, cross-domain feature spaces are often assumed to be consistent, whereas new domains commonly suffer from structural missingness of offline (statistical) features due to the lack of historical data. Third, such feature missingness often compels industrial systems to model mature and cold-start domains separately, hindering knowledge transfer and increasing maintenance overhead. To address these challenges, we propose \textbf{UME}, a \textbf{U}nified \textbf{M}eta-generalization framework for \textbf{E}TA. Specifically, UME integrates a unified dual-branch architecture with a novel meta-learning mechanism that employs a hypernetwork-based meta learner. By leveraging domain-level knowledge and instance-level context, the meta learner empowers three meta modules to dynamically modulate feature gating, expert attention, and final prediction, capturing cross-domain correlations and facilitating intra-domain adaptation. A knowledge distillation strategy is further introduce to enhance performance. UME has now been deployed in Meituan-keeta delivery platform (the largest international food delivery platform in China). Extensive offline experiments and online A/B tests demonstrate that UME significantly outperforms existing baselines.
Hitem3D 2.0: Multi-View Guided Native 3D Texture Generation
Apr 10, 2026Although recent advances have improved the quality of 3D texture generation, existing methods still struggle with incomplete texture coverage, cross-view inconsistency, and misalignment between geometry and texture. To address these limitations, we propose Hitem3D 2.0, a multi-view guided native 3D texture generation framework that enhances texture quality through the integration of 2D multi-view generation priors and native 3D texture representations. Hitem3D 2.0 comprises two key components: a multi-view synthesis framework and a native 3D texture generation model. The multi-view generation is built upon a pre-trained image editing backbone and incorporates plug-and-play modules that explicitly promote geometric alignment, cross-view consistency, and illumination uniformity, thereby enabling the synthesis of high-fidelity multi-view images. Conditioned on the generated views and 3D geometry, the native 3D texture generation model projects multi-view textures onto 3D surfaces while plausibly completing textures in unseen regions. Through the integration of multi-view consistency constraints with native 3D texture modeling, Hitem3D 2.0 significantly improves texture completeness, cross-view coherence, and geometric alignment. Experimental results demonstrate that Hitem3D 2.0 outperforms existing methods in terms of texture detail, fidelity, consistency, coherence, and alignment.
Adaptive Query Prompting for Multi-Domain Landmark Detection
Apr 01, 2024



Medical landmark detection is crucial in various medical imaging modalities and procedures. Although deep learning-based methods have achieve promising performance, they are mostly designed for specific anatomical regions or tasks. In this work, we propose a universal model for multi-domain landmark detection by leveraging transformer architecture and developing a prompting component, named as Adaptive Query Prompting (AQP). Instead of embedding additional modules in the backbone network, we design a separate module to generate prompts that can be effectively extended to any other transformer network. In our proposed AQP, prompts are learnable parameters maintained in a memory space called prompt pool. The central idea is to keep the backbone frozen and then optimize prompts to instruct the model inference process. Furthermore, we employ a lightweight decoder to decode landmarks from the extracted features, namely Light-MLD. Thanks to the lightweight nature of the decoder and AQP, we can handle multiple datasets by sharing the backbone encoder and then only perform partial parameter tuning without incurring much additional cost. It has the potential to be extended to more landmark detection tasks. We conduct experiments on three widely used X-ray datasets for different medical landmark detection tasks. Our proposed Light-MLD coupled with AQP achieves SOTA performance on many metrics even without the use of elaborate structural designs or complex frameworks.
Tensor Restricted Isometry Property Analysis For a Large Class of Random Measurement Ensembles
Jun 04, 2019
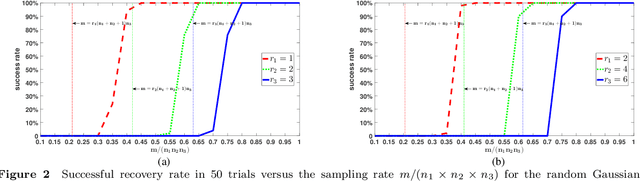
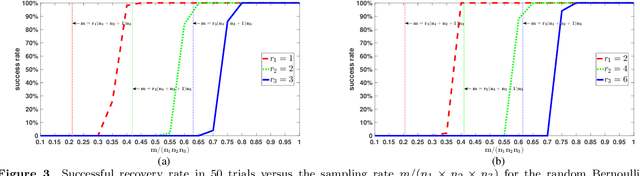
In previous work, theoretical analysis based on the tensor Restricted Isometry Property (t-RIP) established the robust recovery guarantees of a low-tubal-rank tensor. The obtained sufficient conditions depend strongly on the assumption that the linear measurement maps satisfy the t-RIP. In this paper, by exploiting the probabilistic arguments, we prove that such linear measurement maps exist under suitable conditions on the number of measurements in terms of the tubal rank r and the size of third-order tensor n1, n2, n3. And the obtained minimal possible number of linear measurements is nearly optimal compared with the degrees of freedom of a tensor with tubal rank r. Specially, we consider a random sub-Gaussian distribution that includes Gaussian, Bernoulli and all bounded distributions and construct a large class of linear maps that satisfy a t-RIP with high probability. Moreover, the validity of the required number of measurements is verified by numerical experiments.