 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHitem3D 2.0: Multi-View Guided Native 3D Texture Generation
Apr 10, 2026Although recent advances have improved the quality of 3D texture generation, existing methods still struggle with incomplete texture coverage, cross-view inconsistency, and misalignment between geometry and texture. To address these limitations, we propose Hitem3D 2.0, a multi-view guided native 3D texture generation framework that enhances texture quality through the integration of 2D multi-view generation priors and native 3D texture representations. Hitem3D 2.0 comprises two key components: a multi-view synthesis framework and a native 3D texture generation model. The multi-view generation is built upon a pre-trained image editing backbone and incorporates plug-and-play modules that explicitly promote geometric alignment, cross-view consistency, and illumination uniformity, thereby enabling the synthesis of high-fidelity multi-view images. Conditioned on the generated views and 3D geometry, the native 3D texture generation model projects multi-view textures onto 3D surfaces while plausibly completing textures in unseen regions. Through the integration of multi-view consistency constraints with native 3D texture modeling, Hitem3D 2.0 significantly improves texture completeness, cross-view coherence, and geometric alignment. Experimental results demonstrate that Hitem3D 2.0 outperforms existing methods in terms of texture detail, fidelity, consistency, coherence, and alignment.
More diverse more adaptive: Comprehensive Multi-task Learning for Improved LLM Domain Adaptation in E-commerce
Apr 09, 2025



In recent years, Large Language Models (LLMs) have been widely applied across various domains due to their powerful domain adaptation capabilities. Previous studies have suggested that diverse, multi-modal data can enhance LLMs' domain adaptation performance. However, this hypothesis remains insufficiently validated in the e-commerce sector. To address this gap, we propose a comprehensive e-commerce multi-task framework and design empirical experiments to examine the impact of diverse data and tasks on LLMs from two perspectives: "capability comprehensiveness" and "task comprehensiveness." Specifically, we observe significant improvements in LLM performance by progressively introducing tasks related to new major capability areas and by continuously adding subtasks within different major capability domains. Furthermore, we observe that increasing model capacity amplifies the benefits of diversity, suggesting a synergistic relationship between model capacity and data diversity. Finally, we validate the best-performing model from our empirical experiments in the KDD Cup 2024, achieving a rank 5 in Task 1. This outcome demonstrates the significance of our research for advancing LLMs in the e-commerce domain.
BiCSI: A Binary Encoding and Fingerprint-Based Matching Algorithm for Wi-Fi Indoor Positioning
Dec 03, 2024



Traditional global positioning systems often underperform indoors, whereas Wi-Fi has become an effective medium for various radio sensing services. Specifically, utilizing channel state information (CSI) from Wi-Fi networks provides a non-contact method for precise indoor positioning; yet, accurately interpreting the complex CSI matrix to develop a reliable strategy for physical similarity measurement remains challenging. This paper presents BiCSI, which merges binary encoding with fingerprint-based techniques to improve position matching for detecting semi-stationary targets. Inspired by gene sequencing processes, BiCSI initially converts CSI matrices into binary sequences and employs Hamming distances to evaluate signal similarity. The results show that BiCSI achieves an average accuracy above 98% and a mean absolute error (MAE) of less than three centimeters, outperforming algorithms directly dependent on physical measurements by at least two-fold. Moreover, the proposed method for extracting feature vectors from CSI matrices as fingerprints significantly reduces data storage requirements to the kilobyte range, far below the megabytes typically required by conventional machine learning models. Additionally, the results demonstrate that the proposed algorithm adapts well to multiple physical similarity metrics, and remains robust over different time periods, enhancing its utility and versatility in various scenarios.
Convolution with even-sized kernels and symmetric padding
Mar 20, 2019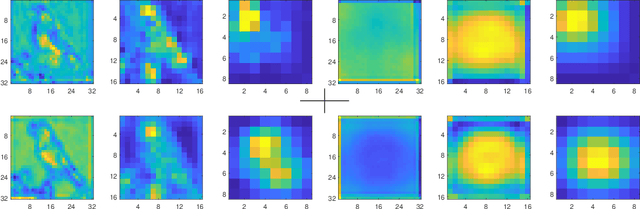
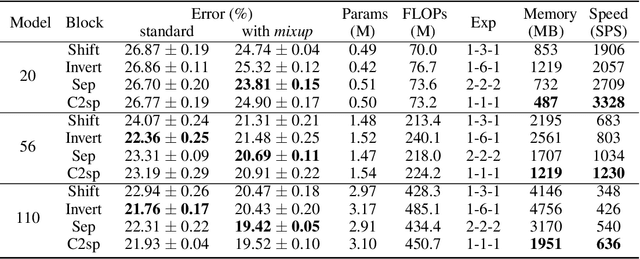
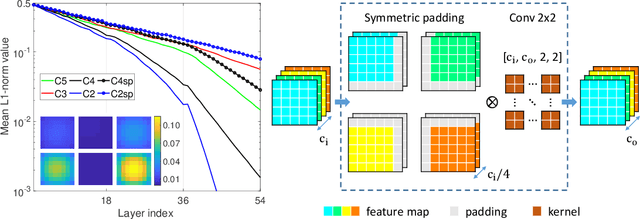
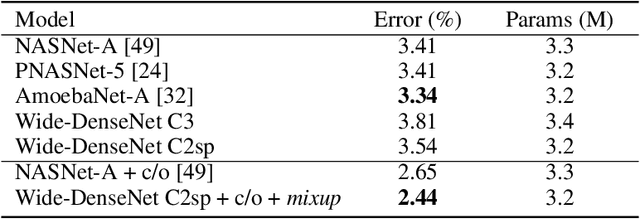
Compact convolutional neural networks gain efficiency mainly through depthwise convolutions, expanded channels and complex topologies, which contrarily aggravate the training efforts. In this work, we identify the shift problem occurs in even-sized kernel (2x2, 4x4) convolutions, and eliminate it by proposing symmetric padding on each side of the feature maps (C2sp, C4sp). Symmetric padding enlarges the receptive fields of even-sized kernels with little computational cost. In classification tasks, C2sp outperforms the conventional 3x3 convolution and obtains comparable accuracies to existing compact convolution blocks, but consumes less memory and time during training. In generation tasks, C2sp and C4sp both achieve improved image qualities and stabilized training. Symmetric padding coupled with even-sized convolution is easy to be implemented into deep learning frameworks, providing promising building units for architecture designs that emphasize training efforts on online and continual learning occasions.