 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultigrain-aware Semantic Prototype Scanning and Tri-Token Prompt Learning Embraced High-Order RWKV for Pan-Sharpening
Apr 16, 2026In this work, we propose a Multigrain-aware Semantic Prototype Scanning paradigm for pan-sharpening, built upon a high-order RWKV architecture and a tri-token prompting mechanism derived from semantic clustering. Specifically, our method contains three key components: 1) Multigrain-aware Semantic Prototype Scanning. Although RWKV offers a efficient linear-complexity alternative to Transformers, its conventional bidirectional raster scanning is still semantic-agnostic and prone to positional bias. To address this issue, we introduce a semantic-driven scanning strategy that leverages locality-sensitive hashing to group semantically related regions and construct multi-grain semantic prototypes, enabling context-aware token reordering and more coherent global interaction. 2) Tri-token Prompt Learning. We design a tri-token prompting mechanism consisting of a global token, cluster-derived prototype tokens, and a learnable register token. The global and prototype tokens provide complementary semantic priors for RWKV modeling, while the register token helps suppress noisy and artifact-prone intermediate representations. 3) Invertible Q-Shift. To counteract spatial details, we apply center difference convolution on the value pathway to inject high-frequency information, and introduce an invertible multi-scale Q-shift operation for efficient and lossless feature transformation without parameter-heavy receptive field expansion. Experimental results demonstrate the superiority of our method.
4KDehazeFlow: Ultra-High-Definition Image Dehazing via Flow Matching
Nov 12, 2025Ultra-High-Definition (UHD) image dehazing faces challenges such as limited scene adaptability in prior-based methods and high computational complexity with color distortion in deep learning approaches. To address these issues, we propose 4KDehazeFlow, a novel method based on Flow Matching and the Haze-Aware vector field. This method models the dehazing process as a progressive optimization of continuous vector field flow, providing efficient data-driven adaptive nonlinear color transformation for high-quality dehazing. Specifically, our method has the following advantages: 1) 4KDehazeFlow is a general method compatible with various deep learning networks, without relying on any specific network architecture. 2) We propose a learnable 3D lookup table (LUT) that encodes haze transformation parameters into a compact 3D mapping matrix, enabling efficient inference through precomputed mappings. 3) We utilize a fourth-order Runge-Kutta (RK4) ordinary differential equation (ODE) solver to stably solve the dehazing flow field through an accurate step-by-step iterative method, effectively suppressing artifacts. Extensive experiments show that 4KDehazeFlow exceeds seven state-of-the-art methods. It delivers a 2dB PSNR increase and better performance in dense haze and color fidelity.
Semi-Supervised State-Space Model with Dynamic Stacking Filter for Real-World Video Deraining
May 22, 2025



Significant progress has been made in video restoration under rainy conditions over the past decade, largely propelled by advancements in deep learning. Nevertheless, existing methods that depend on paired data struggle to generalize effectively to real-world scenarios, primarily due to the disparity between synthetic and authentic rain effects. To address these limitations, we propose a dual-branch spatio-temporal state-space model to enhance rain streak removal in video sequences. Specifically, we design spatial and temporal state-space model layers to extract spatial features and incorporate temporal dependencies across frames, respectively. To improve multi-frame feature fusion, we derive a dynamic stacking filter, which adaptively approximates statistical filters for superior pixel-wise feature refinement. Moreover, we develop a median stacking loss to enable semi-supervised learning by generating pseudo-clean patches based on the sparsity prior of rain. To further explore the capacity of deraining models in supporting other vision-based tasks in rainy environments, we introduce a novel real-world benchmark focused on object detection and tracking in rainy conditions. Our method is extensively evaluated across multiple benchmarks containing numerous synthetic and real-world rainy videos, consistently demonstrating its superiority in quantitative metrics, visual quality, efficiency, and its utility for downstream tasks.
FaceInsight: A Multimodal Large Language Model for Face Perception
Apr 22, 2025



Recent advances in multimodal large language models (MLLMs) have demonstrated strong capabilities in understanding general visual content. However, these general-domain MLLMs perform poorly in face perception tasks, often producing inaccurate or misleading responses to face-specific queries. To address this gap, we propose FaceInsight, the versatile face perception MLLM that provides fine-grained facial information. Our approach introduces visual-textual alignment of facial knowledge to model both uncertain dependencies and deterministic relationships among facial information, mitigating the limitations of language-driven reasoning. Additionally, we incorporate face segmentation maps as an auxiliary perceptual modality, enriching the visual input with localized structural cues to enhance semantic understanding. Comprehensive experiments and analyses across three face perception tasks demonstrate that FaceInsight consistently outperforms nine compared MLLMs under both training-free and fine-tuned settings.
A Hybrid Transformer-Mamba Network for Single Image Deraining
Aug 31, 2024



Existing deraining Transformers employ self-attention mechanisms with fixed-range windows or along channel dimensions, limiting the exploitation of non-local receptive fields. In response to this issue, we introduce a novel dual-branch hybrid Transformer-Mamba network, denoted as TransMamba, aimed at effectively capturing long-range rain-related dependencies. Based on the prior of distinct spectral-domain features of rain degradation and background, we design a spectral-banded Transformer blocks on the first branch. Self-attention is executed within the combination of the spectral-domain channel dimension to improve the ability of modeling long-range dependencies. To enhance frequency-specific information, we present a spectral enhanced feed-forward module that aggregates features in the spectral domain. In the second branch, Mamba layers are equipped with cascaded bidirectional state space model modules to additionally capture the modeling of both local and global information. At each stage of both the encoder and decoder, we perform channel-wise concatenation of dual-branch features and achieve feature fusion through channel reduction, enabling more effective integration of the multi-scale information from the Transformer and Mamba branches. To better reconstruct innate signal-level relations within clean images, we also develop a spectral coherence loss. Extensive experiments on diverse datasets and real-world images demonstrate the superiority of our method compared against the state-of-the-art approaches.
An extended description logic system with knowledge element based on ALC
Apr 16, 2019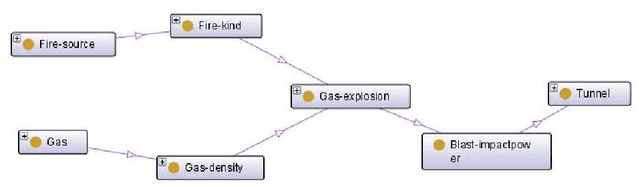
With the rise of knowledge management and knowledge economy, the knowledge elements that directly link and embody the knowledge system have become the research focus and hotspot in certain areas. The existing knowledge element representation methods are limited in functions to deal with the formality, logic and reasoning. Based on description logic ALC and the common knowledge element model, in order to describe the knowledge element, the description logic ALC is expanded. The concept is extended to two diferent ones (that is, the object knowledge element concept and the attribute knowledge element concept). The relationship is extended to three (that is, relationship between object knowledge element concept and attribute knowledge element concept, relationship among object knowledge element concepts, relationship among attribute knowledge element concepts), and the inverse relationship constructor is added to propose a description logic KEDL system. By demonstrating, the relevant properties, such as completeness, reliability,of the described logic system KEDL are obtained. Finally, it is verified by the example that the description logic KEDL system has strong knowledge element description ability.