 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Design of Metamaterials with Manufacturing-Guiding Spectrum-to-Structure Conditional Diffusion Model
Jun 08, 2025Metamaterials are artificially engineered structures that manipulate electromagnetic waves, having optical properties absent in natural materials. Recently, machine learning for the inverse design of metamaterials has drawn attention. However, the highly nonlinear relationship between the metamaterial structures and optical behaviour, coupled with fabrication difficulties, poses challenges for using machine learning to design and manufacture complex metamaterials. Herein, we propose a general framework that implements customised spectrum-to-shape and size parameters to address one-to-many metamaterial inverse design problems using conditional diffusion models. Our method exhibits superior spectral prediction accuracy, generates a diverse range of patterns compared to other typical generative models, and offers valuable prior knowledge for manufacturing through the subsequent analysis of the diverse generated results, thereby facilitating the experimental fabrication of metamaterial designs. We demonstrate the efficacy of the proposed method by successfully designing and fabricating a free-form metamaterial with a tailored selective emission spectrum for thermal camouflage applications.
CRYSIM: Prediction of Symmetric Structures of Large Crystals with GPU-based Ising Machines
Apr 09, 2025Solving black-box optimization problems with Ising machines is increasingly common in materials science. However, their application to crystal structure prediction (CSP) is still ineffective due to symmetry agnostic encoding of atomic coordinates. We introduce CRYSIM, an algorithm that encodes the space group, the Wyckoff positions combination, and coordinates of independent atomic sites as separate variables. This encoding reduces the search space substantially by exploiting the symmetry in space groups. When CRYSIM is interfaced to Fixstars Amplify, a GPU-based Ising machine, its prediction performance was competitive with CALYPSO and Bayesian optimization for crystals containing more than 150 atoms in a unit cell. Although it is not realistic to interface CRYSIM to current small-scale quantum devices, it has the potential to become the standard CSP algorithm in the coming quantum age.
On Synthetic Data Strategies for Domain-Specific Generative Retrieval
Feb 25, 2025



This paper investigates synthetic data generation strategies in developing generative retrieval models for domain-specific corpora, thereby addressing the scalability challenges inherent in manually annotating in-domain queries. We study the data strategies for a two-stage training framework: in the first stage, which focuses on learning to decode document identifiers from queries, we investigate LLM-generated queries across multiple granularity (e.g. chunks, sentences) and domain-relevant search constraints that can better capture nuanced relevancy signals. In the second stage, which aims to refine document ranking through preference learning, we explore the strategies for mining hard negatives based on the initial model's predictions. Experiments on public datasets over diverse domains demonstrate the effectiveness of our synthetic data generation and hard negative sampling approach.
You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL
Sep 18, 2024



While significant progress has been made on the text-to-SQL task, recent solutions repeatedly encode the same database schema for every question, resulting in unnecessary high inference cost and often overlooking crucial database knowledge. To address these issues, we propose You Only Read Once (YORO), a novel paradigm that directly internalizes database knowledge into the parametric knowledge of a text-to-SQL model during training and eliminates the need for schema encoding during inference. YORO significantly reduces the input token length by 66%-98%. Despite its shorter inputs, our empirical results demonstrate YORO's competitive performances with traditional systems on three benchmarks as well as its significant outperformance on large databases. Furthermore, YORO excels in handling questions with challenging value retrievals such as abbreviation.
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Apr 24, 2024Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
Propagation and Pitfalls: Reasoning-based Assessment of Knowledge Editing through Counterfactual Tasks
Jan 31, 2024Current approaches of knowledge editing struggle to effectively propagate updates to interconnected facts. In this work, we delve into the barriers that hinder the appropriate propagation of updated knowledge within these models for accurate reasoning. To support our analysis, we introduce a novel reasoning-based benchmark -- ReCoE (Reasoning-based Counterfactual Editing dataset) -- which covers six common reasoning schemes in real world. We conduct a thorough analysis of existing knowledge editing techniques, including input augmentation, finetuning, and locate-and-edit. We found that all model editing methods show notably low performance on this dataset, especially in certain reasoning schemes. Our analysis over the chain-of-thought generation of edited models further uncover key reasons behind the inadequacy of existing knowledge editing methods from a reasoning standpoint, involving aspects on fact-wise editing, fact recall ability, and coherence in generation. We will make our benchmark publicly available.
UNITE: A Unified Benchmark for Text-to-SQL Evaluation
May 26, 2023


A practical text-to-SQL system should generalize well on a wide variety of natural language questions, unseen database schemas, and novel SQL query structures. To comprehensively evaluate text-to-SQL systems, we introduce a \textbf{UNI}fied benchmark for \textbf{T}ext-to-SQL \textbf{E}valuation (UNITE). It is composed of publicly available text-to-SQL datasets, containing natural language questions from more than 12 domains, SQL queries from more than 3.9K patterns, and 29K databases. Compared to the widely used Spider benchmark \cite{yu-etal-2018-spider}, we introduce $\sim$120K additional examples and a threefold increase in SQL patterns, such as comparative and boolean questions. We conduct a systematic study of six state-of-the-art (SOTA) text-to-SQL parsers on our new benchmark and show that: 1) Codex performs surprisingly well on out-of-domain datasets; 2) specially designed decoding methods (e.g. constrained beam search) can improve performance for both in-domain and out-of-domain settings; 3) explicitly modeling the relationship between questions and schemas further improves the Seq2Seq models. More importantly, our benchmark presents key challenges towards compositional generalization and robustness issues -- which these SOTA models cannot address well. \footnote{Our code and data processing script will be available at \url{https://github.com/XXXX.}}
RxnScribe: A Sequence Generation Model for Reaction Diagram Parsing
May 19, 2023Reaction diagram parsing is the task of extracting reaction schemes from a diagram in the chemistry literature. The reaction diagrams can be arbitrarily complex, thus robustly parsing them into structured data is an open challenge. In this paper, we present RxnScribe, a machine learning model for parsing reaction diagrams of varying styles. We formulate this structured prediction task with a sequence generation approach, which condenses the traditional pipeline into an end-to-end model. We train RxnScribe on a dataset of 1,378 diagrams and evaluate it with cross validation, achieving an 80.0% soft match F1 score, with significant improvements over previous models. Our code and data are publicly available at https://github.com/thomas0809/RxnScribe.
Robust Molecular Image Recognition: A Graph Generation Approach
May 28, 2022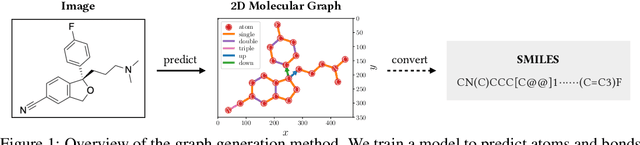
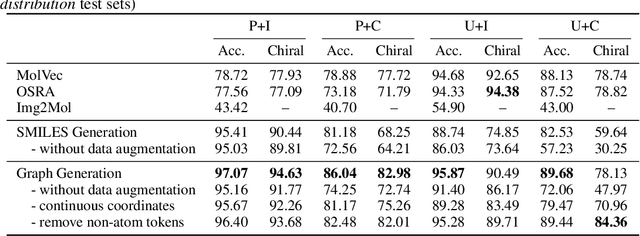
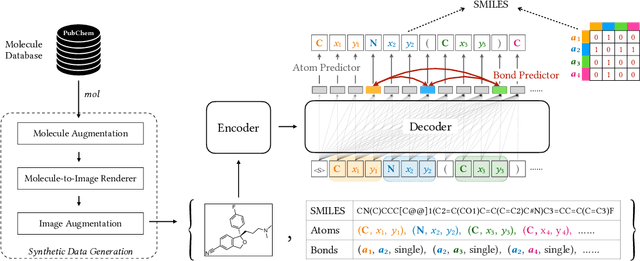
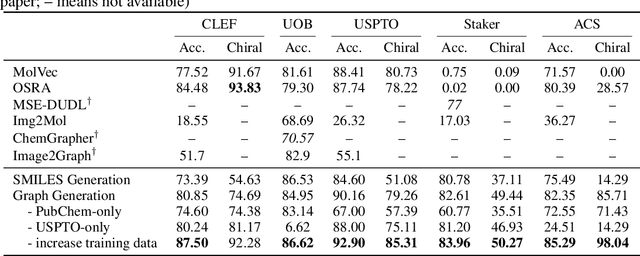
Molecular image recognition is a fundamental task in information extraction from chemistry literature. Previous data-driven models formulate it as an image-to-sequence task, to generate a sequential representation of the molecule (e.g. SMILES string) from its graphical representation. Although they perform adequately on certain benchmarks, these models are not robust in real-world situations, where molecular images differ in style, quality, and chemical patterns. In this paper, we propose a novel graph generation approach that explicitly predicts atoms and bonds, along with their geometric layouts, to construct the molecular graph. We develop data augmentation strategies for molecules and images to increase the robustness of our model against domain shifts. Our model is flexible to incorporate chemistry constraints, and produces more interpretable predictions than SMILES. In experiments on both synthetic and realistic molecular images, our model significantly outperforms previous models, achieving 84-93% accuracy on five benchmarks. We also conduct human evaluation and show that our model reduces the time for a chemist to extract molecular structures from images by roughly 50%.
Designing thermal radiation metamaterials via hybrid adversarial autoencoder and Bayesian optimization
Apr 26, 2022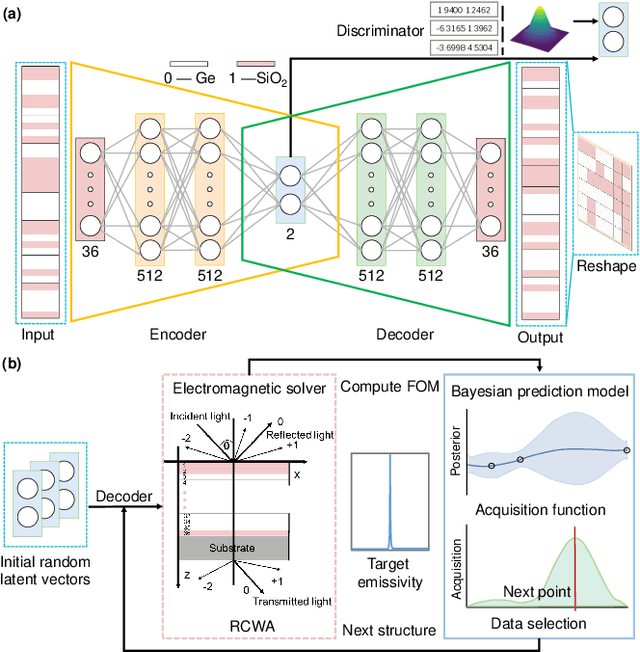
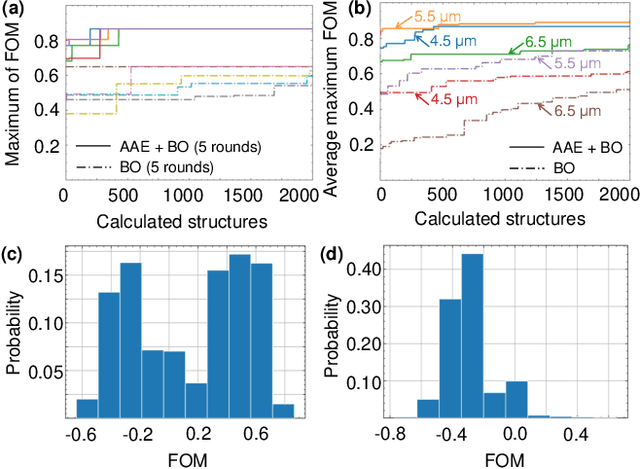
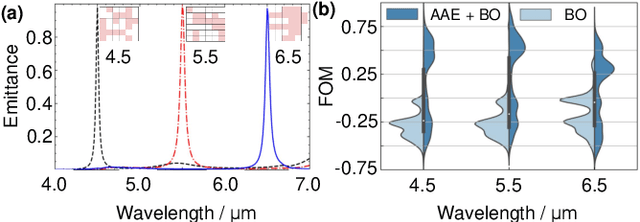
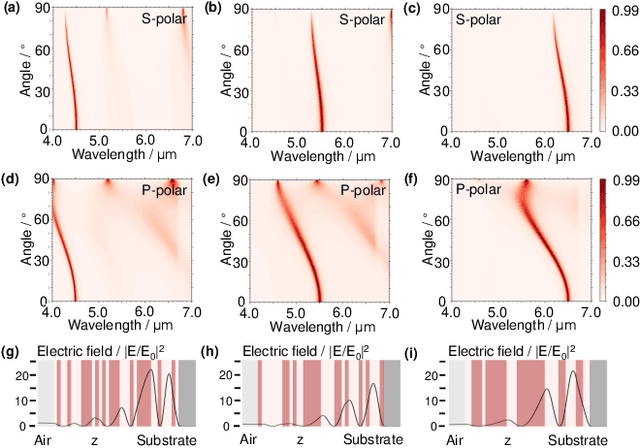
Designing thermal radiation metamaterials is challenging especially for problems with high degrees of freedom and complex objective. In this letter, we have developed a hybrid materials informatics approach which combines the adversarial autoencoder and Bayesian optimization to design narrowband thermal emitters at different target wavelengths. With only several hundreds of training data sets, new structures with optimal properties can be quickly figured out in a compressed 2-dimensional latent space. This enables the optimal design by calculating far less than 0.001\% of the total candidate structures, which greatly decreases the design period and cost. The proposed design framework can be easily extended to other thermal radiation metamaterials design with higher dimensional features.