 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Evolution and Exploration Within Latent Level-Design Space of Generative Adversarial Networks
Mar 31, 2020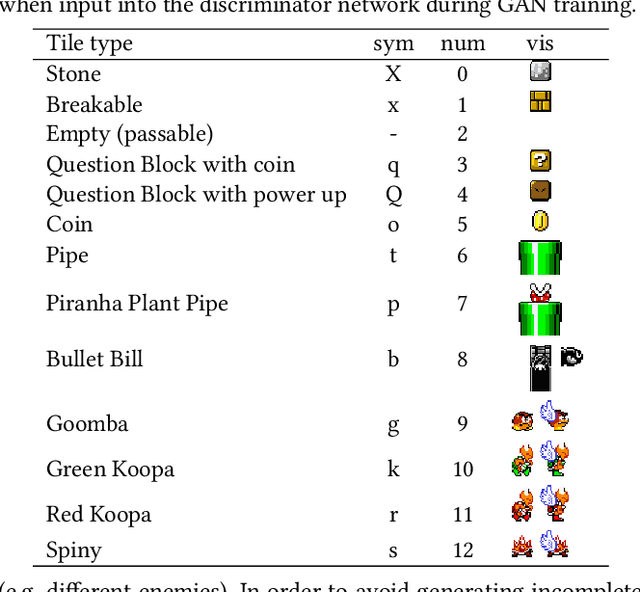
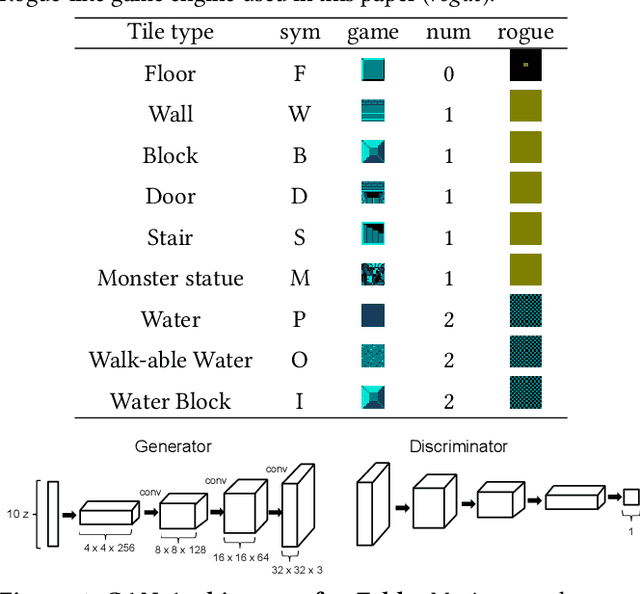
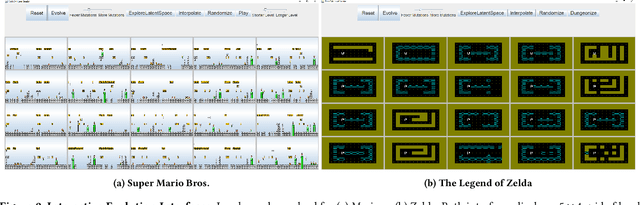
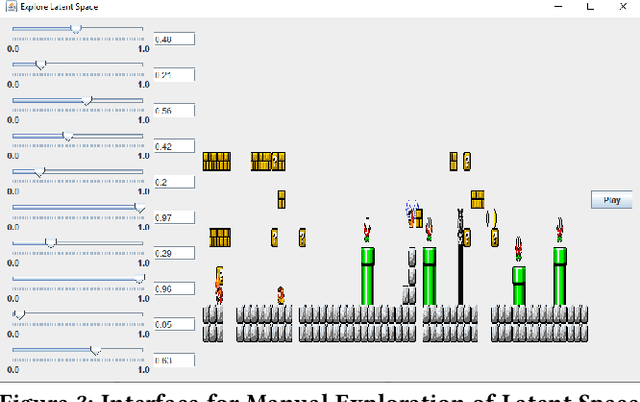
Generative Adversarial Networks (GANs) are an emerging form of indirect encoding. The GAN is trained to induce a latent space on training data, and a real-valued evolutionary algorithm can search that latent space. Such Latent Variable Evolution (LVE) has recently been applied to game levels. However, it is hard for objective scores to capture level features that are appealing to players. Therefore, this paper introduces a tool for interactive LVE of tile-based levels for games. The tool also allows for direct exploration of the latent dimensions, and allows users to play discovered levels. The tool works for a variety of GAN models trained for both Super Mario Bros. and The Legend of Zelda, and is easily generalizable to other games. A user study shows that both the evolution and latent space exploration features are appreciated, with a slight preference for direct exploration, but combining these features allows users to discover even better levels. User feedback also indicates how this system could eventually grow into a commercial design tool, with the addition of a few enhancements.
Learning Convolutional Sparse Coding on Complex Domain for Interferometric Phase Restoration
Mar 06, 2020
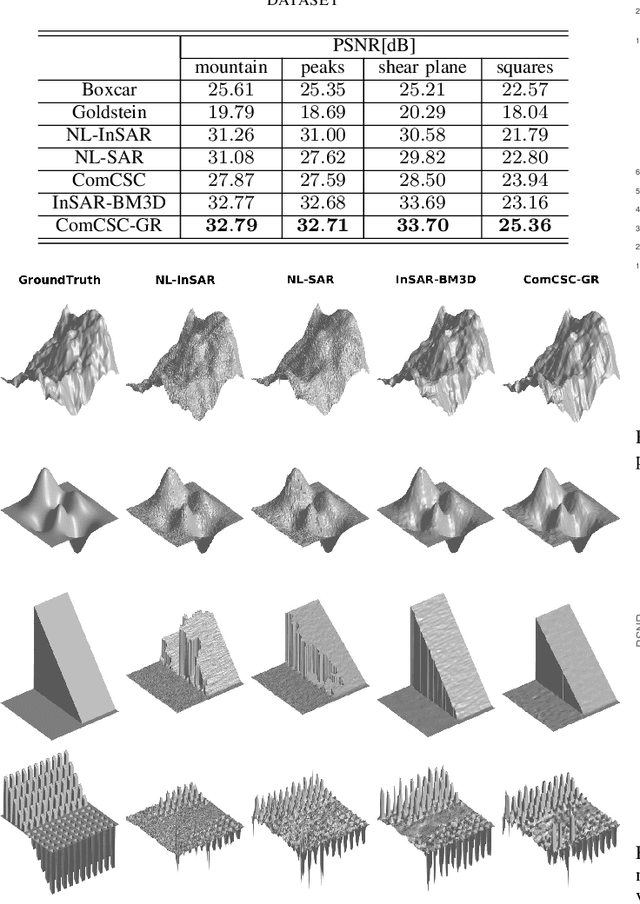
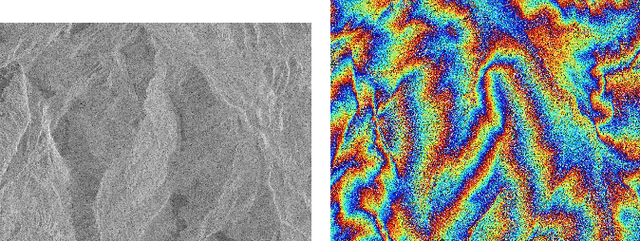
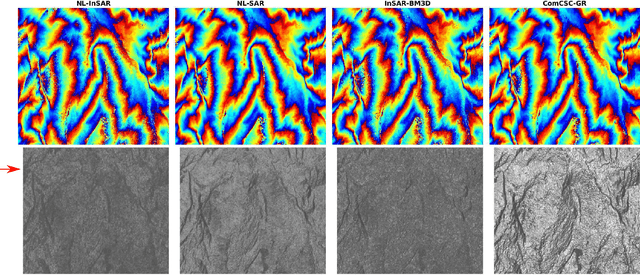
Interferometric phase restoration has been investigated for decades and most of the state-of-the-art methods have achieved promising performances for InSAR phase restoration. These methods generally follow the nonlocal filtering processing chain aiming at circumventing the staircase effect and preserving the details of phase variations. In this paper, we propose an alternative approach for InSAR phase restoration, i.e. Complex Convolutional Sparse Coding (ComCSC) and its gradient regularized version. To our best knowledge, this is the first time that we solve the InSAR phase restoration problem in a deconvolutional fashion. The proposed methods can not only suppress interferometric phase noise, but also avoid the staircase effect and preserve the details. Furthermore, they provide an insight of the elementary phase components for the interferometric phases. The experimental results on synthetic and realistic high- and medium-resolution datasets from TerraSAR-X StripMap and Sentinel-1 interferometric wide swath mode, respectively, show that our method outperforms those previous state-of-the-art methods based on nonlocal InSAR filters, particularly the state-of-the-art method: InSAR-BM3D. The source code of this paper will be made publicly available for reproducible research inside the community.
Task Augmentation by Rotating for Meta-Learning
Feb 08, 2020
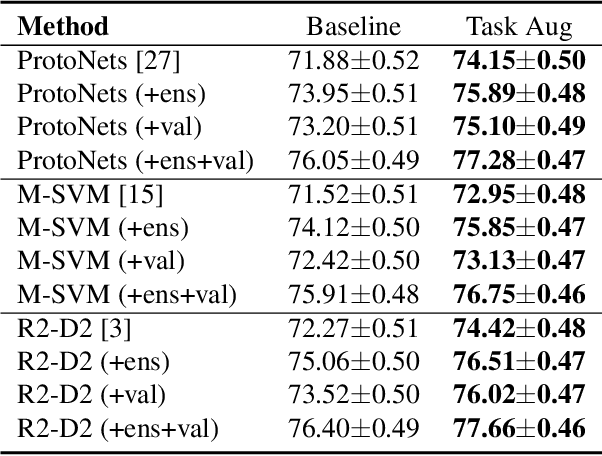

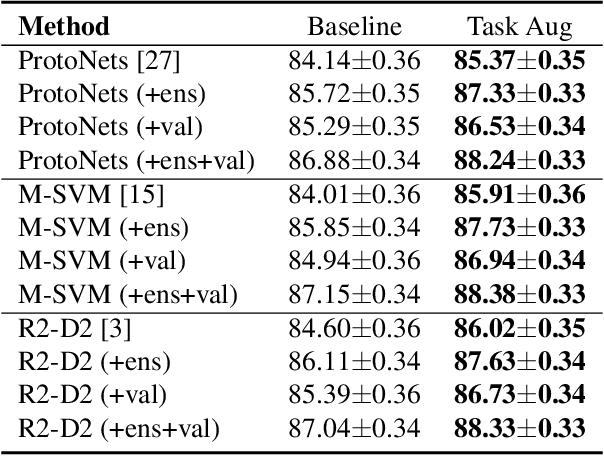
Data augmentation is one of the most effective approaches for improving the accuracy of modern machine learning models, and it is also indispensable to train a deep model for meta-learning. In this paper, we introduce a task augmentation method by rotating, which increases the number of classes by rotating the original images 90, 180 and 270 degrees, different from traditional augmentation methods which increase the number of images. With a larger amount of classes, we can sample more diverse task instances during training. Therefore, task augmentation by rotating allows us to train a deep network by meta-learning methods with little over-fitting. Experimental results show that our approach is better than the rotation for increasing the number of images and achieves state-of-the-art performance on miniImageNet, CIFAR-FS, and FC100 few-shot learning benchmarks. The code is available on \url{www.github.com/AceChuse/TaskLevelAug}.
Decoder Choice Network for Meta-Learning
Sep 25, 2019
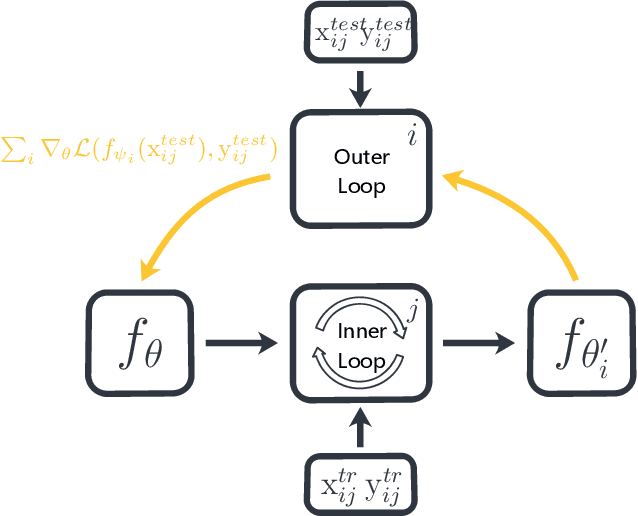
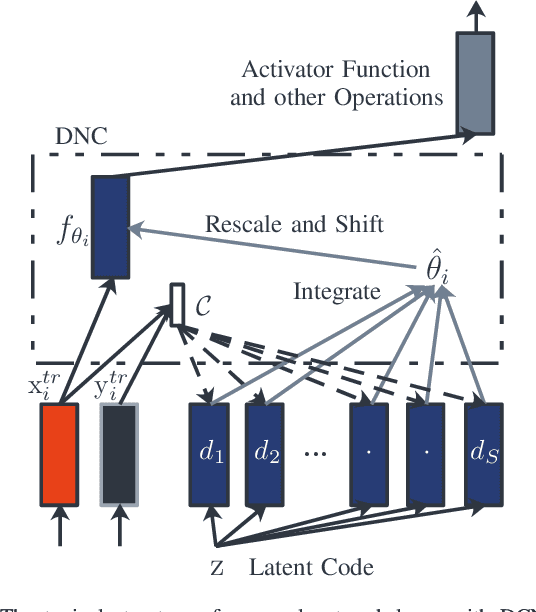
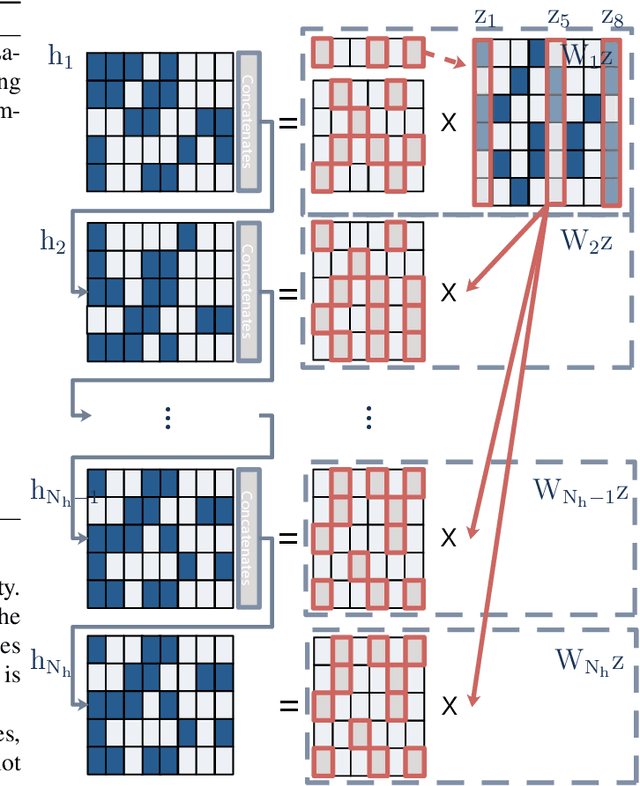
Meta-learning has been widely used for implementing few-shot learning and fast model adaptation. One kind of meta-learning methods attempt to learn how to control the gradient descent process in order to make the gradient-based learning have high speed and generalization. This work proposes a method that controls the gradient descent process of the model parameters of a neural network by limiting the model parameters in a low-dimensional latent space. The main challenge of this idea is that a decoder with too many parameters is required. This work designs a decoder with typical structure and shares a part of weights in the decoder to reduce the number of the required parameters. Besides, this work has introduced ensemble learning to work with the proposed approach for improving performance. The results show that the proposed approach is witnessed by the superior performance over the Omniglot classification and the miniImageNet classification tasks.
Stock Prices Prediction using Deep Learning Models
Sep 25, 2019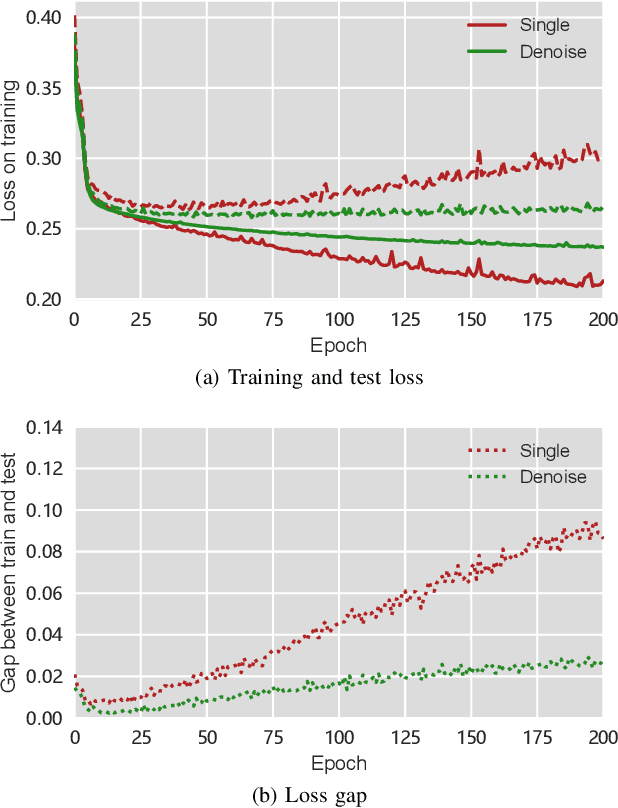
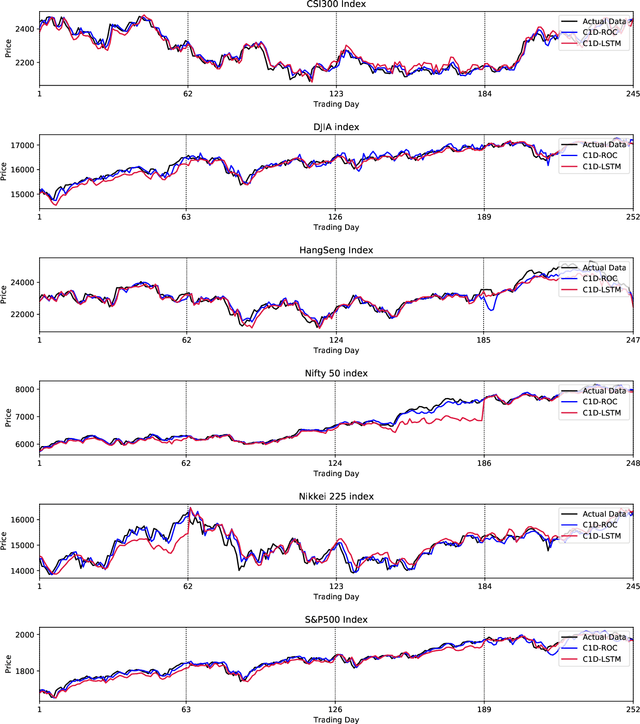
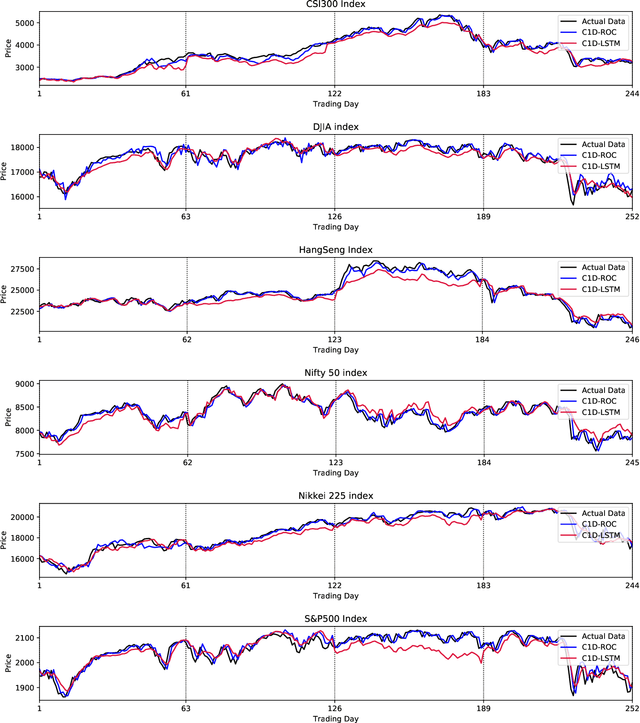
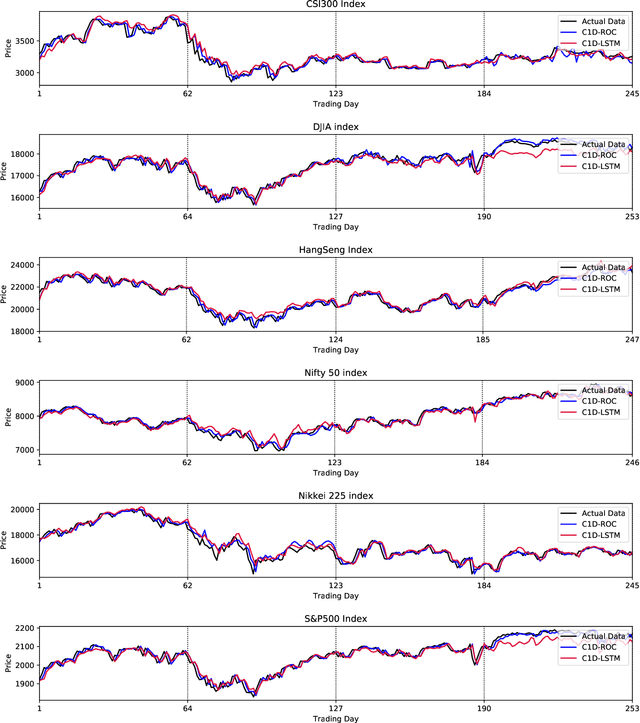
Financial markets have a vital role in the development of modern society. They allow the deployment of economic resources. Changes in stock prices reflect changes in the market. In this study, we focus on predicting stock prices by deep learning model. This is a challenge task, because there is much noise and uncertainty in information that is related to stock prices. So this work uses sparse autoencoders with one-dimension (1-D) residual convolutional networks which is a deep learning model, to de-noise the data. Long-short term memory (LSTM) is then used to predict the stock price. The prices, indices and macroeconomic variables in past are the features used to predict the next day's price. Experiment results show that 1-D residual convolutional networks can de-noise data and extract deep features better than a model that combines wavelet transforms (WT) and stacked autoencoders (SAEs). In addition, we compare the performances of model with two different forecast targets of stock price: absolute stock price and price rate of change. The results show that predicting stock price through price rate of change is better than predicting absolute prices directly.
Gradient Boost with Convolution Neural Network for Stock Forecast
Sep 19, 2019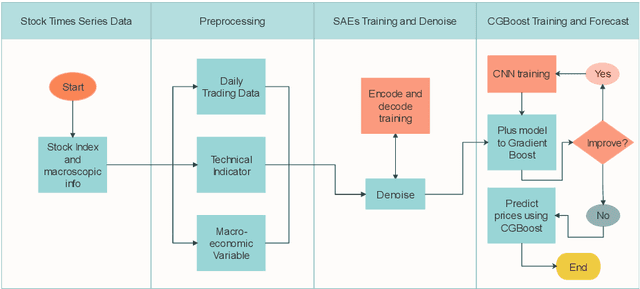
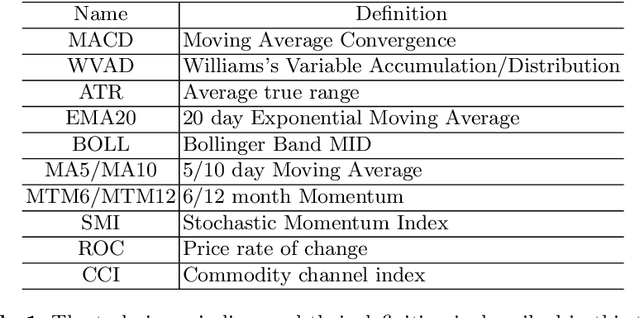
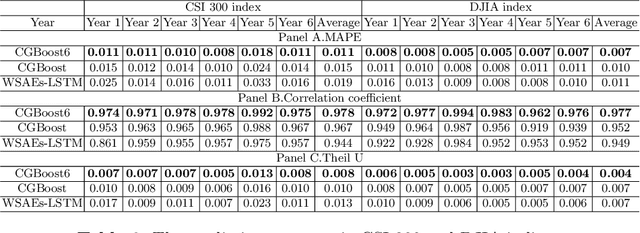
Market economy closely connects aspects to all walks of life. The stock forecast is one of task among studies on the market economy. However, information on markets economy contains a lot of noise and uncertainties, which lead economy forecasting to become a challenging task. Ensemble learning and deep learning are the most methods to solve the stock forecast task. In this paper, we present a model combining the advantages of two methods to forecast the change of stock price. The proposed method combines CNN and GBoost. The experimental results on six market indexes show that the proposed method has better performance against current popular methods.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019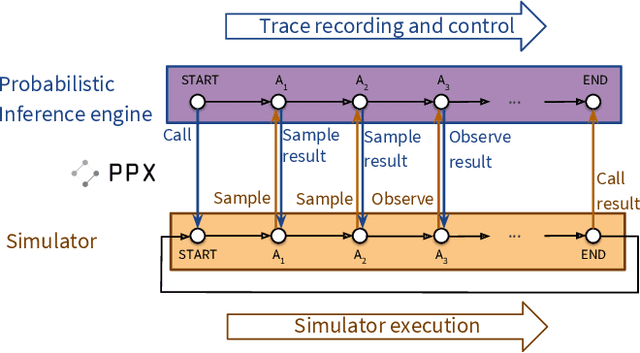

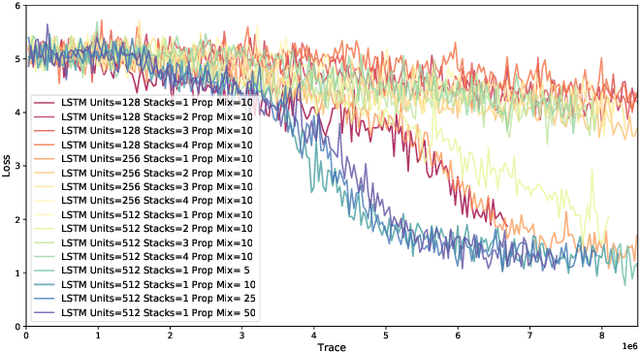
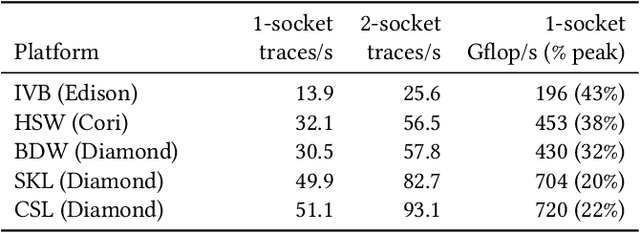
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
Plug-and-Play Methods Provably Converge with Properly Trained Denoisers
May 14, 2019
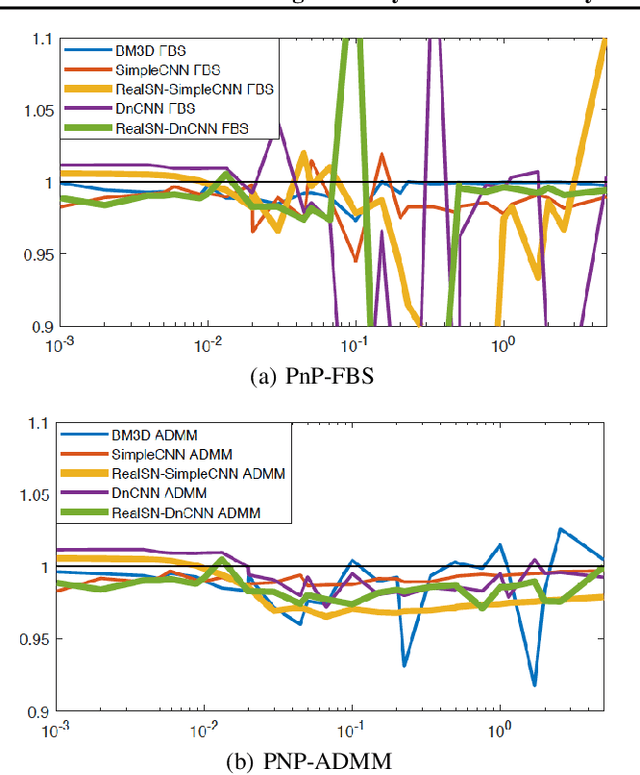

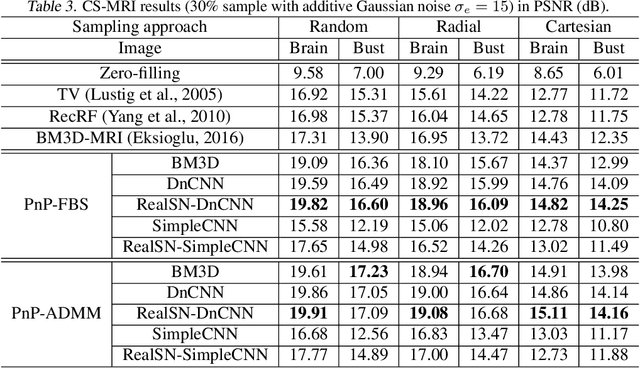
Plug-and-play (PnP) is a non-convex framework that integrates modern denoising priors, such as BM3D or deep learning-based denoisers, into ADMM or other proximal algorithms. An advantage of PnP is that one can use pre-trained denoisers when there is not sufficient data for end-to-end training. Although PnP has been recently studied extensively with great empirical success, theoretical analysis addressing even the most basic question of convergence has been insufficient. In this paper, we theoretically establish convergence of PnP-FBS and PnP-ADMM, without using diminishing stepsizes, under a certain Lipschitz condition on the denoisers. We then propose real spectral normalization, a technique for training deep learning-based denoisers to satisfy the proposed Lipschitz condition. Finally, we present experimental results validating the theory.
Algorithm Portfolio for Individual-based Surrogate-Assisted Evolutionary Algorithms
Apr 22, 2019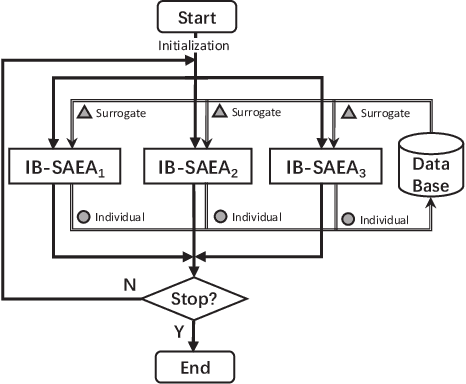
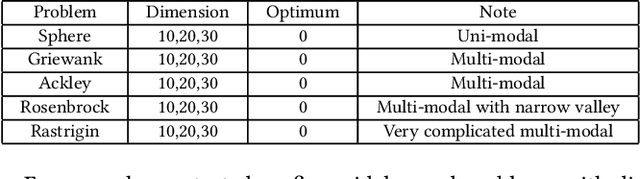
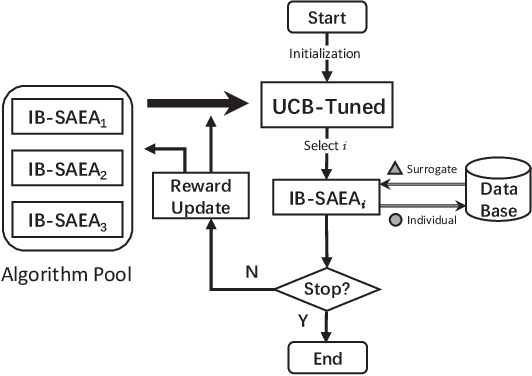
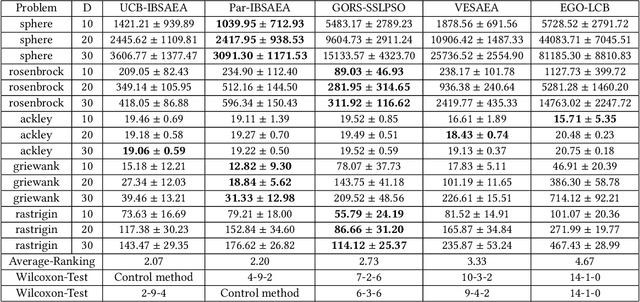
Surrogate-assisted evolutionary algorithms (SAEAs) are powerful optimisation tools for computationally expensive problems (CEPs). However, a randomly selected algorithm may fail in solving unknown problems due to no free lunch theorems, and it will cause more computational resource if we re-run the algorithm or try other algorithms to get a much solution, which is more serious in CEPs. In this paper, we consider an algorithm portfolio for SAEAs to reduce the risk of choosing an inappropriate algorithm for CEPs. We propose two portfolio frameworks for very expensive problems in which the maximal number of fitness evaluations is only 5 times of the problem's dimension. One framework named Par-IBSAEA runs all algorithm candidates in parallel and a more sophisticated framework named UCB-IBSAEA employs the Upper Confidence Bound (UCB) policy from reinforcement learning to help select the most appropriate algorithm at each iteration. An effective reward definition is proposed for the UCB policy. We consider three state-of-the-art individual-based SAEAs on different problems and compare them to the portfolios built from their instances on several benchmark problems given limited computation budgets. Our experimental studies demonstrate that our proposed portfolio frameworks significantly outperform any single algorithm on the set of benchmark problems.
Rinascimento: Optimising Statistical Forward Planning Agents for Playing Splendor
Apr 03, 2019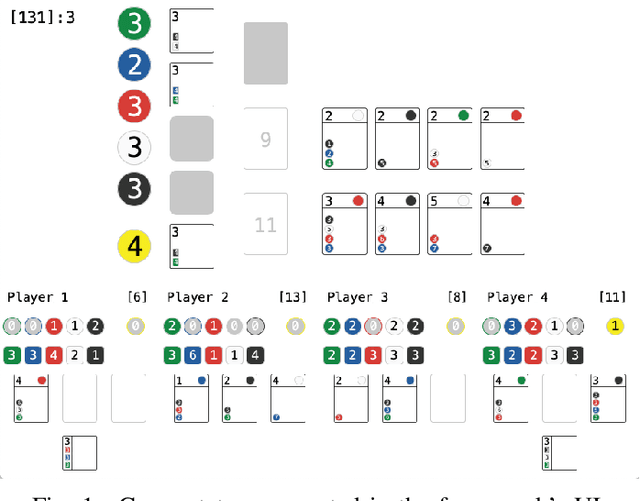

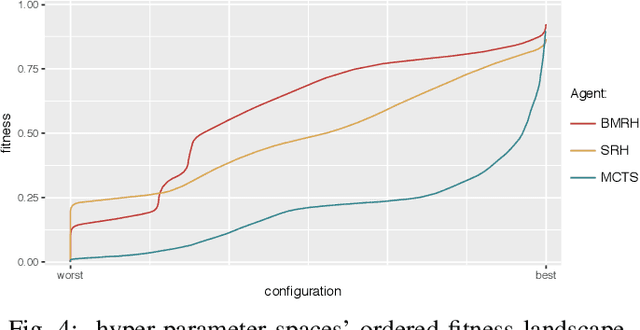
Game-based benchmarks have been playing an essential role in the development of Artificial Intelligence (AI) techniques. Providing diverse challenges is crucial to push research toward innovation and understanding in modern techniques. Rinascimento provides a parameterised partially-observable multiplayer card-based board game, these parameters can easily modify the rules, objectives and items in the game. We describe the framework in all its features and the game-playing challenge providing baseline game-playing AIs and analysis of their skills. We reserve to agents' hyper-parameter tuning a central role in the experiments highlighting how it can heavily influence the performance. The base-line agents contain several additional contribution to Statistical Forward Planning algorithms.