 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIoT-based Android Malware Detection Using Graph Neural Network With Adversarial Defense
Dec 23, 2025



Since the Internet of Things (IoT) is widely adopted using Android applications, detecting malicious Android apps is essential. In recent years, Android graph-based deep learning research has proposed many approaches to extract relationships from applications as graphs to generate graph embeddings. First, we demonstrate the effectiveness of graph-based classification using a Graph Neural Network (GNN)-based classifier to generate API graph embeddings. The graph embeddings are combined with Permission and Intent features to train multiple machine learning and deep learning models for Android malware detection. The proposed classification approach achieves an accuracy of 98.33 percent on the CICMaldroid dataset and 98.68 percent on the Drebin dataset. However, graph-based deep learning models are vulnerable, as attackers can add fake relationships to evade detection by the classifier. Second, we propose a Generative Adversarial Network (GAN)-based attack algorithm named VGAE-MalGAN targeting graph-based GNN Android malware classifiers. The VGAE-MalGAN generator produces adversarial malware API graphs, while the VGAE-MalGAN substitute detector attempts to mimic the target detector. Experimental results show that VGAE-MalGAN can significantly reduce the detection rate of GNN-based malware classifiers. Although the model initially fails to detect adversarial malware, retraining with generated adversarial samples improves robustness and helps mitigate adversarial attacks.
* 13 pages
Insider Threat Detection Using GCN and Bi-LSTM with Explicit and Implicit Graph Representations
Dec 20, 2025



Insider threat detection (ITD) is challenging due to the subtle and concealed nature of malicious activities performed by trusted users. This paper proposes a post-hoc ITD framework that integrates explicit and implicit graph representations with temporal modelling to capture complex user behaviour patterns. An explicit graph is constructed using predefined organisational rules to model direct relationships among user activities. To mitigate noise and limitations in this hand-crafted structure, an implicit graph is learned from feature similarities using the Gumbel-Softmax trick, enabling the discovery of latent behavioural relationships. Separate Graph Convolutional Networks (GCNs) process the explicit and implicit graphs to generate node embeddings, which are concatenated and refined through an attention mechanism to emphasise threat-relevant features. The refined representations are then passed to a bidirectional Long Short-Term Memory (Bi-LSTM) network to capture temporal dependencies in user behaviour. Activities are flagged as anomalous when their probability scores fall below a predefined threshold. Extensive experiments on CERT r5.2 and r6.2 datasets demonstrate that the proposed framework outperforms state-of-the-art methods. On r5.2, the model achieves an AUC of 98.62, a detection rate of 100%, and a false positive rate of 0.05. On the more challenging r6.2 dataset, it attains an AUC of 88.48, a detection rate of 80.15%, and a false positive rate of 0.15, highlighting the effectiveness of combining graph-based and temporal representations for robust ITD.
Comprehensive Botnet Detection by Mitigating Adversarial Attacks, Navigating the Subtleties of Perturbation Distances and Fortifying Predictions with Conformal Layers
Sep 01, 2024



Botnets are computer networks controlled by malicious actors that present significant cybersecurity challenges. They autonomously infect, propagate, and coordinate to conduct cybercrimes, necessitating robust detection methods. This research addresses the sophisticated adversarial manipulations posed by attackers, aiming to undermine machine learning-based botnet detection systems. We introduce a flow-based detection approach, leveraging machine learning and deep learning algorithms trained on the ISCX and ISOT datasets. The detection algorithms are optimized using the Genetic Algorithm and Particle Swarm Optimization to obtain a baseline detection method. The Carlini & Wagner (C&W) attack and Generative Adversarial Network (GAN) generate deceptive data with subtle perturbations, targeting each feature used for classification while preserving their semantic and syntactic relationships, which ensures that the adversarial samples retain meaningfulness and realism. An in-depth analysis of the required L2 distance from the original sample for the malware sample to misclassify is performed across various iteration checkpoints, showing different levels of misclassification at different L2 distances of the Pertrub sample from the original sample. Our work delves into the vulnerability of various models, examining the transferability of adversarial examples from a Neural Network surrogate model to Tree-based algorithms. Subsequently, models that initially misclassified the perturbed samples are retrained, enhancing their resilience and detection capabilities. In the final phase, a conformal prediction layer is integrated, significantly rejecting incorrect predictions, of 58.20 % in the ISCX dataset and 98.94 % in the ISOT dataset.
* 46 pages
3C: Confidence-Guided Clustering and Contrastive Learning for Unsupervised Person Re-Identification
Aug 18, 2024



Unsupervised person re-identification (Re-ID) aims to learn a feature network with cross-camera retrieval capability in unlabelled datasets. Although the pseudo-label based methods have achieved great progress in Re-ID, their performance in the complex scenario still needs to sharpen up. In order to reduce potential misguidance, including feature bias, noise pseudo-labels and invalid hard samples, accumulated during the learning process, in this pa per, a confidence-guided clustering and contrastive learning (3C) framework is proposed for unsupervised person Re-ID. This 3C framework presents three confidence degrees. i) In the clustering stage, the confidence of the discrepancy between samples and clusters is proposed to implement a harmonic discrepancy clustering algorithm (HDC). ii) In the forward-propagation training stage, the confidence of the camera diversity of a cluster is evaluated via a novel camera information entropy (CIE). Then, the clusters with high CIE values will play leading roles in training the model. iii) In the back-propagation training stage, the confidence of the hard sample in each cluster is designed and further used in a confidence integrated harmonic discrepancy (CHD), to select the informative sample for updating the memory in contrastive learning. Extensive experiments on three popular Re-ID benchmarks demonstrate the superiority of the proposed framework. Particularly, the 3C framework achieves state-of-the-art results: 86.7%/94.7%, 45.3%/73.1% and 47.1%/90.6% in terms of mAP/Rank-1 accuracy on Market-1501, the com plex datasets MSMT17 and VeRi-776, respectively. Code is available at https://github.com/stone5265/3C-reid.
Geometric Features Enhanced Human-Object Interaction Detection
Jun 26, 2024



Cameras are essential vision instruments to capture images for pattern detection and measurement. Human-object interaction (HOI) detection is one of the most popular pattern detection approaches for captured human-centric visual scenes. Recently, Transformer-based models have become the dominant approach for HOI detection due to their advanced network architectures and thus promising results. However, most of them follow the one-stage design of vanilla Transformer, leaving rich geometric priors under-exploited and leading to compromised performance especially when occlusion occurs. Given that geometric features tend to outperform visual ones in occluded scenarios and offer information that complements visual cues, we propose a novel end-to-end Transformer-style HOI detection model, i.e., geometric features enhanced HOI detector (GeoHOI). One key part of the model is a new unified self-supervised keypoint learning method named UniPointNet that bridges the gap of consistent keypoint representation across diverse object categories, including humans. GeoHOI effectively upgrades a Transformer-based HOI detector benefiting from the keypoints similarities measuring the likelihood of human-object interactions as well as local keypoint patches to enhance interaction query representation, so as to boost HOI predictions. Extensive experiments show that the proposed method outperforms the state-of-the-art models on V-COCO and achieves competitive performance on HICO-DET. Case study results on the post-disaster rescue with vision-based instruments showcase the applicability of the proposed GeoHOI in real-world applications.
Detect2Interact: Localizing Object Key Field in Visual Question Answering (VQA) with LLMs
Apr 01, 2024Localization plays a crucial role in enhancing the practicality and precision of VQA systems. By enabling fine-grained identification and interaction with specific parts of an object, it significantly improves the system's ability to provide contextually relevant and spatially accurate responses, crucial for applications in dynamic environments like robotics and augmented reality. However, traditional systems face challenges in accurately mapping objects within images to generate nuanced and spatially aware responses. In this work, we introduce "Detect2Interact", which addresses these challenges by introducing an advanced approach for fine-grained object visual key field detection. First, we use the segment anything model (SAM) to generate detailed spatial maps of objects in images. Next, we use Vision Studio to extract semantic object descriptions. Third, we employ GPT-4's common sense knowledge, bridging the gap between an object's semantics and its spatial map. As a result, Detect2Interact achieves consistent qualitative results on object key field detection across extensive test cases and outperforms the existing VQA system with object detection by providing a more reasonable and finer visual representation.
Overview of Human Activity Recognition Using Sensor Data
Sep 12, 2023

Human activity recognition (HAR) is an essential research field that has been used in different applications including home and workplace automation, security and surveillance as well as healthcare. Starting from conventional machine learning methods to the recently developing deep learning techniques and the Internet of things, significant contributions have been shown in the HAR area in the last decade. Even though several review and survey studies have been published, there is a lack of sensor-based HAR overview studies focusing on summarising the usage of wearable sensors and smart home sensors data as well as applications of HAR and deep learning techniques. Hence, we overview sensor-based HAR, discuss several important applications that rely on HAR, and highlight the most common machine learning methods that have been used for HAR. Finally, several challenges of HAR are explored that should be addressed to further improve the robustness of HAR.
Error Controlled Actor-Critic
Sep 07, 2021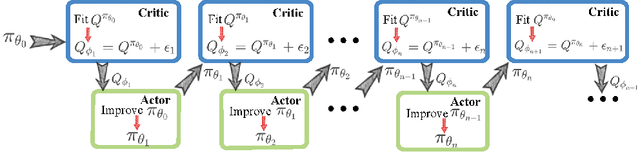
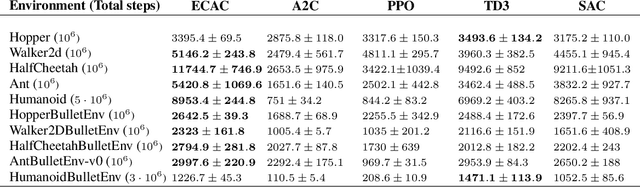
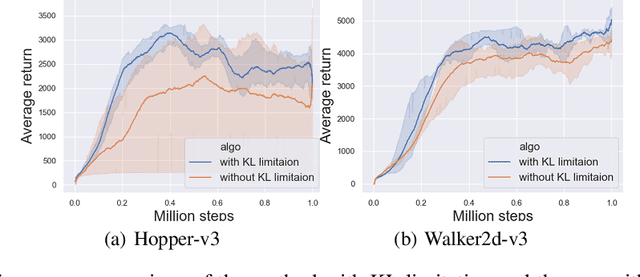

On error of value function inevitably causes an overestimation phenomenon and has a negative impact on the convergence of the algorithms. To mitigate the negative effects of the approximation error, we propose Error Controlled Actor-critic which ensures confining the approximation error in value function. We present an analysis of how the approximation error can hinder the optimization process of actor-critic methods.Then, we derive an upper boundary of the approximation error of Q function approximator and find that the error can be lowered by restricting on the KL-divergence between every two consecutive policies when training the policy. The results of experiments on a range of continuous control tasks demonstrate that the proposed actor-critic algorithm apparently reduces the approximation error and significantly outperforms other model-free RL algorithms.
Decoder Choice Network for Meta-Learning
Sep 25, 2019
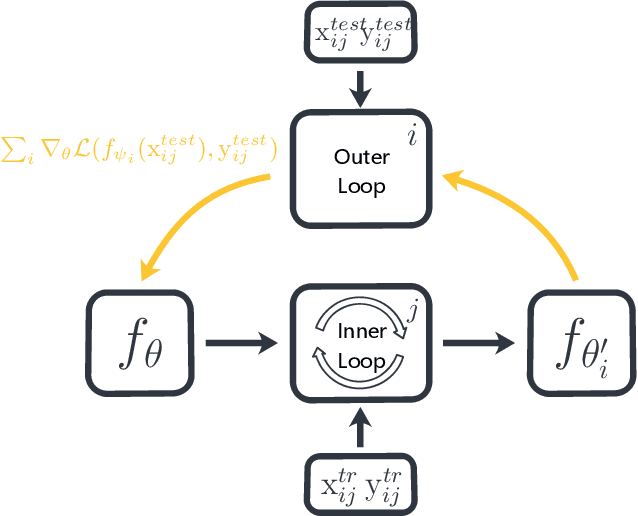
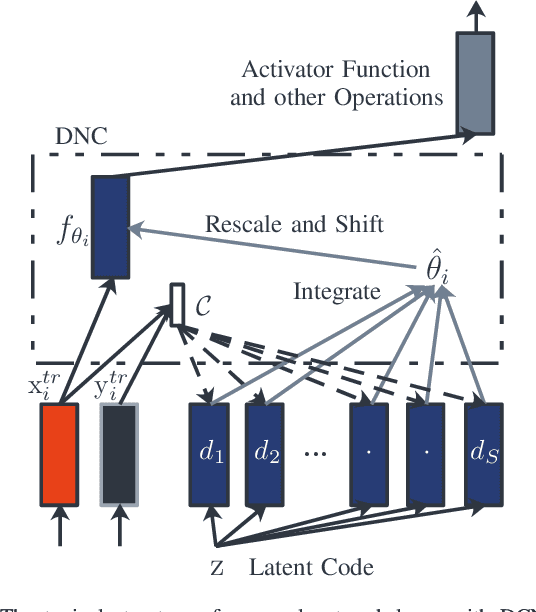
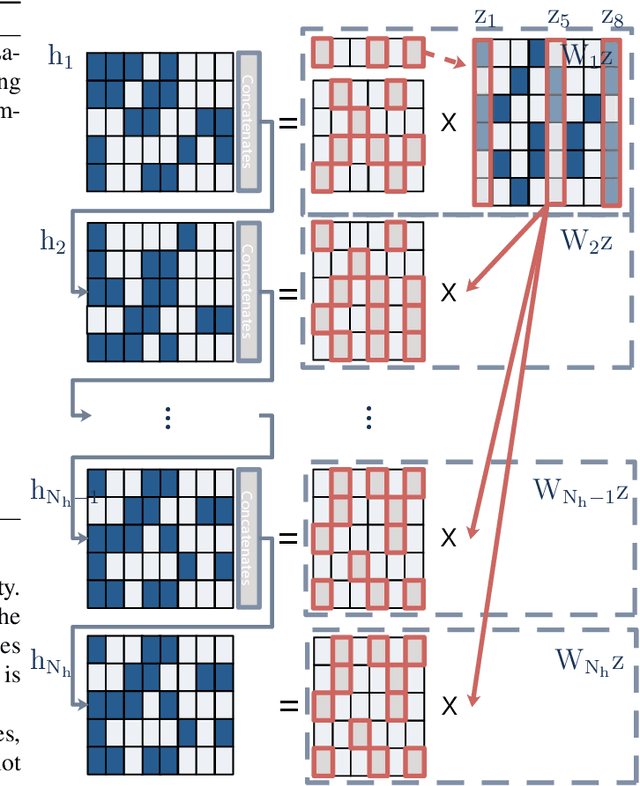
Meta-learning has been widely used for implementing few-shot learning and fast model adaptation. One kind of meta-learning methods attempt to learn how to control the gradient descent process in order to make the gradient-based learning have high speed and generalization. This work proposes a method that controls the gradient descent process of the model parameters of a neural network by limiting the model parameters in a low-dimensional latent space. The main challenge of this idea is that a decoder with too many parameters is required. This work designs a decoder with typical structure and shares a part of weights in the decoder to reduce the number of the required parameters. Besides, this work has introduced ensemble learning to work with the proposed approach for improving performance. The results show that the proposed approach is witnessed by the superior performance over the Omniglot classification and the miniImageNet classification tasks.