 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMODIS: A Benchmark for Context-Dependent Emoji Disambiguation in Large Language Models
Nov 10, 2025Large language models (LLMs) are increasingly deployed in real-world communication settings, yet their ability to resolve context-dependent ambiguity remains underexplored. In this work, we present EMODIS, a new benchmark for evaluating LLMs' capacity to interpret ambiguous emoji expressions under minimal but contrastive textual contexts. Each instance in EMODIS comprises an ambiguous sentence containing an emoji, two distinct disambiguating contexts that lead to divergent interpretations, and a specific question that requires contextual reasoning. We evaluate both open-source and API-based LLMs, and find that even the strongest models frequently fail to distinguish meanings when only subtle contextual cues are present. Further analysis reveals systematic biases toward dominant interpretations and limited sensitivity to pragmatic contrast. EMODIS provides a rigorous testbed for assessing contextual disambiguation, and highlights the gap in semantic reasoning between humans and LLMs.
TritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
Feb 20, 2025Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
Will you donate money to a chatbot? The effect of chatbot anthropomorphic features and persuasion strategies on willingness to donate
Dec 28, 2024

This work investigates the causal mechanism behind the effect of chatbot personification and persuasion strategies on users' perceptions and donation likelihood. In a 2 (personified vs. non-personified chatbot) x 2 (emotional vs. logical persuasion strategy) between-subjects experiment (N=76), participants engaged with a chatbot that represented a non-profit charitable organization. The results suggest that interaction with a personified chatbot evokes perceived anthropomorphism; however, it does not elicit greater willingness to donate. In fact, we found that commonly used anthropomorphic features, like name and narrative, led to negative attitudes toward an AI agent in the donation context. Our results showcase a preference for non-personified chatbots paired with logical persuasion appeal, emphasizing the significance of consistency in chatbot interaction, mirroring human-human engagement. We discuss the importance of moving from exploring the common scenario of a chatbot with machine identity vs. a chatbot with human identity in light of the recent regulations of AI systems.
Chain Association-based Attacking and Shielding Natural Language Processing Systems
Nov 12, 2024



Association as a gift enables people do not have to mention something in completely straightforward words and allows others to understand what they intend to refer to. In this paper, we propose a chain association-based adversarial attack against natural language processing systems, utilizing the comprehension gap between humans and machines. We first generate a chain association graph for Chinese characters based on the association paradigm for building search space of potential adversarial examples. Then, we introduce an discrete particle swarm optimization algorithm to search for the optimal adversarial examples. We conduct comprehensive experiments and show that advanced natural language processing models and applications, including large language models, are vulnerable to our attack, while humans appear good at understanding the perturbed text. We also explore two methods, including adversarial training and associative graph-based recovery, to shield systems from chain association-based attack. Since a few examples that use some derogatory terms, this paper contains materials that may be offensive or upsetting to some people.
IAE: Irony-based Adversarial Examples for Sentiment Analysis Systems
Nov 12, 2024Adversarial examples, which are inputs deliberately perturbed with imperceptible changes to induce model errors, have raised serious concerns for the reliability and security of deep neural networks (DNNs). While adversarial attacks have been extensively studied in continuous data domains such as images, the discrete nature of text presents unique challenges. In this paper, we propose Irony-based Adversarial Examples (IAE), a method that transforms straightforward sentences into ironic ones to create adversarial text. This approach exploits the rhetorical device of irony, where the intended meaning is opposite to the literal interpretation, requiring a deeper understanding of context to detect. The IAE method is particularly challenging due to the need to accurately locate evaluation words, substitute them with appropriate collocations, and expand the text with suitable ironic elements while maintaining semantic coherence. Our research makes the following key contributions: (1) We introduce IAE, a strategy for generating textual adversarial examples using irony. This method does not rely on pre-existing irony corpora, making it a versatile tool for creating adversarial text in various NLP tasks. (2) We demonstrate that the performance of several state-of-the-art deep learning models on sentiment analysis tasks significantly deteriorates when subjected to IAE attacks. This finding underscores the susceptibility of current NLP systems to adversarial manipulation through irony. (3) We compare the impact of IAE on human judgment versus NLP systems, revealing that humans are less susceptible to the effects of irony in text.
What Makes Entities Similar? A Similarity Flooding Perspective for Multi-sourced Knowledge Graph Embeddings
Jun 05, 2023Joint representation learning over multi-sourced knowledge graphs (KGs) yields transferable and expressive embeddings that improve downstream tasks. Entity alignment (EA) is a critical step in this process. Despite recent considerable research progress in embedding-based EA, how it works remains to be explored. In this paper, we provide a similarity flooding perspective to explain existing translation-based and aggregation-based EA models. We prove that the embedding learning process of these models actually seeks a fixpoint of pairwise similarities between entities. We also provide experimental evidence to support our theoretical analysis. We propose two simple but effective methods inspired by the fixpoint computation in similarity flooding, and demonstrate their effectiveness on benchmark datasets. Our work bridges the gap between recent embedding-based models and the conventional similarity flooding algorithm. It would improve our understanding of and increase our faith in embedding-based EA.
Joint Pre-training and Local Re-training: Transferable Representation Learning on Multi-source Knowledge Graphs
Jun 05, 2023



In this paper, we present the ``joint pre-training and local re-training'' framework for learning and applying multi-source knowledge graph (KG) embeddings. We are motivated by the fact that different KGs contain complementary information to improve KG embeddings and downstream tasks. We pre-train a large teacher KG embedding model over linked multi-source KGs and distill knowledge to train a student model for a task-specific KG. To enable knowledge transfer across different KGs, we use entity alignment to build a linked subgraph for connecting the pre-trained KGs and the target KG. The linked subgraph is re-trained for three-level knowledge distillation from the teacher to the student, i.e., feature knowledge distillation, network knowledge distillation, and prediction knowledge distillation, to generate more expressive embeddings. The teacher model can be reused for different target KGs and tasks without having to train from scratch. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our framework.
Deep Active Alignment of Knowledge Graph Entities and Schemata
Apr 19, 2023



Knowledge graphs (KGs) store rich facts about the real world. In this paper, we study KG alignment, which aims to find alignment between not only entities but also relations and classes in different KGs. Alignment at the entity level can cross-fertilize alignment at the schema level. We propose a new KG alignment approach, called DAAKG, based on deep learning and active learning. With deep learning, it learns the embeddings of entities, relations and classes, and jointly aligns them in a semi-supervised manner. With active learning, it estimates how likely an entity, relation or class pair can be inferred, and selects the best batch for human labeling. We design two approximation algorithms for efficient solution to batch selection. Our experiments on benchmark datasets show the superior accuracy and generalization of DAAKG and validate the effectiveness of all its modules.
Trustworthy Knowledge Graph Completion Based on Multi-sourced Noisy Data
Jan 21, 2022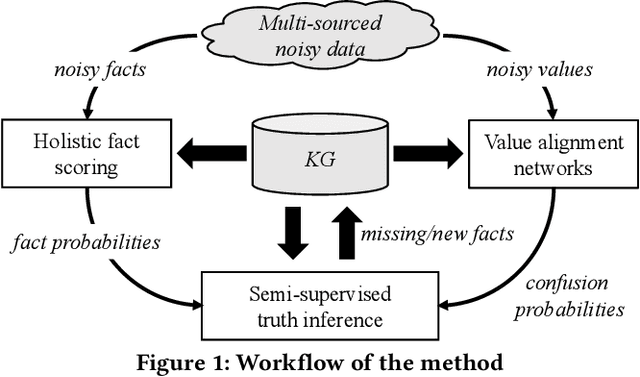
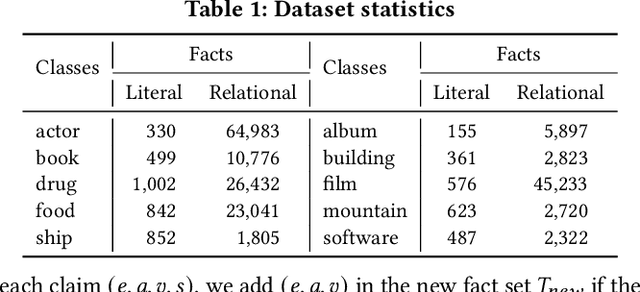
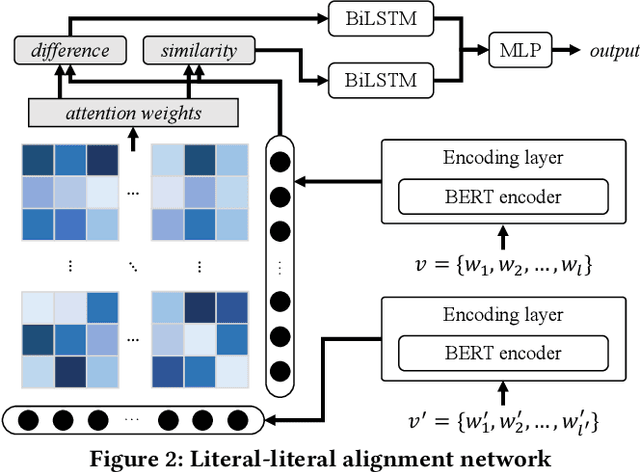
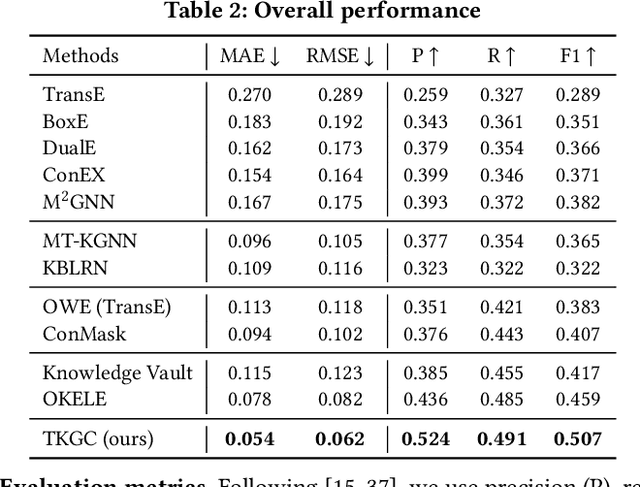
Knowledge graphs (KGs) have become a valuable asset for many AI applications. Although some KGs contain plenty of facts, they are widely acknowledged as incomplete. To address this issue, many KG completion methods are proposed. Among them, open KG completion methods leverage the Web to find missing facts. However, noisy data collected from diverse sources may damage the completion accuracy. In this paper, we propose a new trustworthy method that exploits facts for a KG based on multi-sourced noisy data and existing facts in the KG. Specifically, we introduce a graph neural network with a holistic scoring function to judge the plausibility of facts with various value types. We design value alignment networks to resolve the heterogeneity between values and map them to entities even outside the KG. Furthermore, we present a truth inference model that incorporates data source qualities into the fact scoring function, and design a semi-supervised learning way to infer the truths from heterogeneous values. We conduct extensive experiments to compare our method with the state-of-the-arts. The results show that our method achieves superior accuracy not only in completing missing facts but also in discovering new facts.
Data Augmentation for Text Generation Without Any Augmented Data
May 28, 2021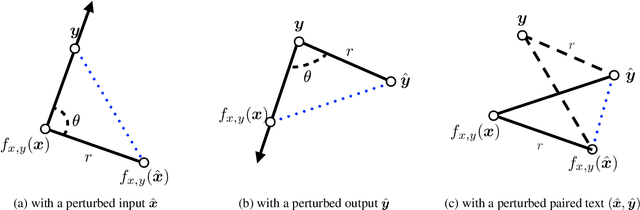
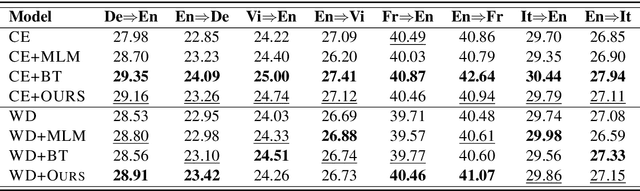
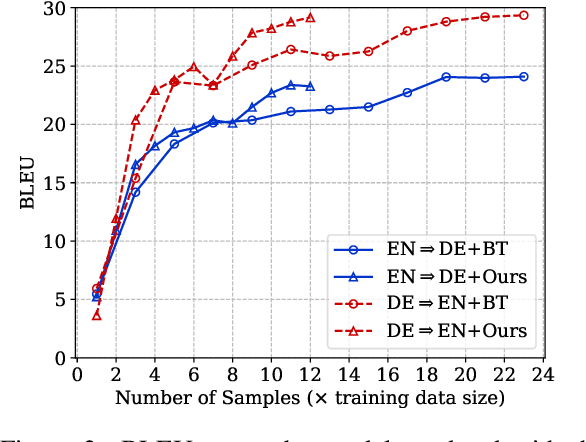
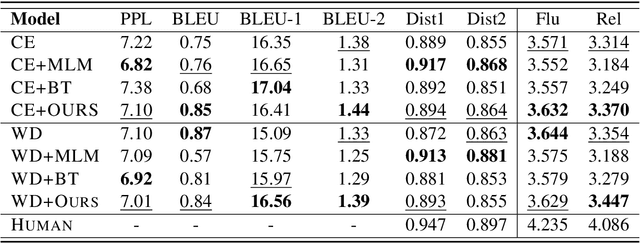
Data augmentation is an effective way to improve the performance of many neural text generation models. However, current data augmentation methods need to define or choose proper data mapping functions that map the original samples into the augmented samples. In this work, we derive an objective to formulate the problem of data augmentation on text generation tasks without any use of augmented data constructed by specific mapping functions. Our proposed objective can be efficiently optimized and applied to popular loss functions on text generation tasks with a convergence rate guarantee. Experiments on five datasets of two text generation tasks show that our approach can approximate or even surpass popular data augmentation methods.