 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaking in the Feature: Accelerating Volumetric Segmentation by Rendering Feature Maps
Sep 26, 2022


Methods have recently been proposed that densely segment 3D volumes into classes using only color images and expert supervision in the form of sparse semantically annotated pixels. While impressive, these methods still require a relatively large amount of supervision and segmenting an object can take several minutes in practice. Such systems typically only optimize their representation on the particular scene they are fitting, without leveraging any prior information from previously seen images. In this paper, we propose to use features extracted with models trained on large existing datasets to improve segmentation performance. We bake this feature representation into a Neural Radiance Field (NeRF) by volumetrically rendering feature maps and supervising on features extracted from each input image. We show that by baking this representation into the NeRF, we make the subsequent classification task much easier. Our experiments show that our method achieves higher segmentation accuracy with fewer semantic annotations than existing methods over a wide range of scenes.
On the programming effort required to generate Behavior Trees and Finite State Machines for robotic applications
Sep 15, 2022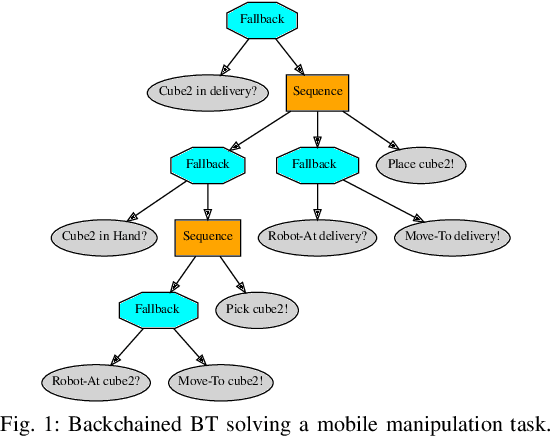
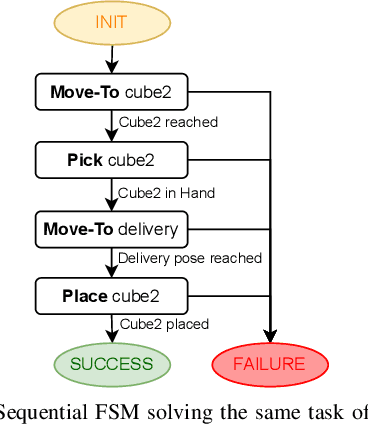


In this paper we provide a practical demonstration of how the modularity in a Behavior Tree (BT) decreases the effort in programming a robot task when compared to a Finite State Machine (FSM). In recent years the way to represent a task plan to control an autonomous agent has been shifting from the standard FSM towards BTs. Many works in the literature have highlighted and proven the benefits of such design compared to standard approaches, especially in terms of modularity, reactivity and human readability. However, these works have often failed in providing a tangible comparison in the implementation of those policies and the programming effort required to modify them. This is a relevant aspect in many robotic applications, where the design choice is dictated both by the robustness of the policy and by the time required to program it. In this work, we compare backward chained BTs with a fault-tolerant design of FSMs by evaluating the cost to modify them. We validate the analysis with a set of experiments in a simulation environment where a mobile manipulator solves an item fetching task.
Learning Agent-Aware Affordances for Closed-Loop Interaction with Articulated Objects
Sep 14, 2022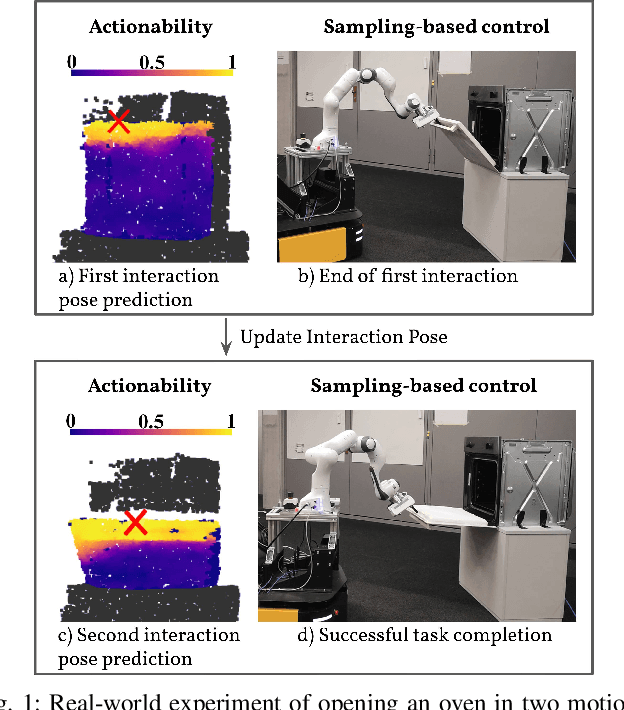


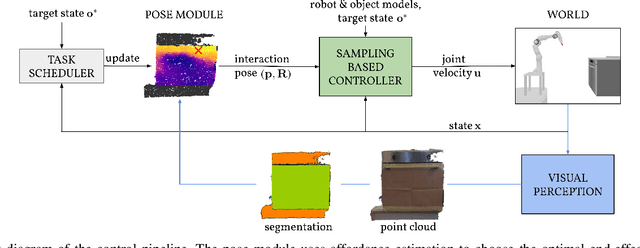
Interactions with articulated objects are a challenging but important task for mobile robots. To tackle this challenge, we propose a novel closed-loop control pipeline, which integrates manipulation priors from affordance estimation with sampling-based whole-body control. We introduce the concept of agent-aware affordances which fully reflect the agent's capabilities and embodiment and we show that they outperform their state-of-the-art counterparts which are only conditioned on the end-effector geometry. Additionally, closed-loop affordance inference is found to allow the agent to divide a task into multiple non-continuous motions and recover from failure and unexpected states. Finally, the pipeline is able to perform long-horizon mobile manipulation tasks, i.e. opening and closing an oven, in the real world with high success rates (opening: 71%, closing: 72%).
Closed-Loop Next-Best-View Planning for Target-Driven Grasping
Jul 21, 2022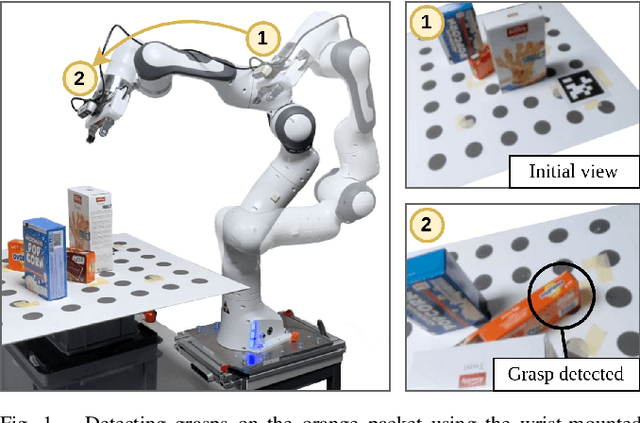
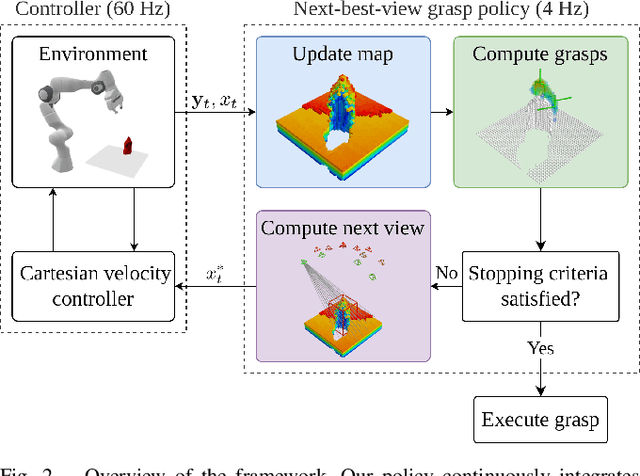
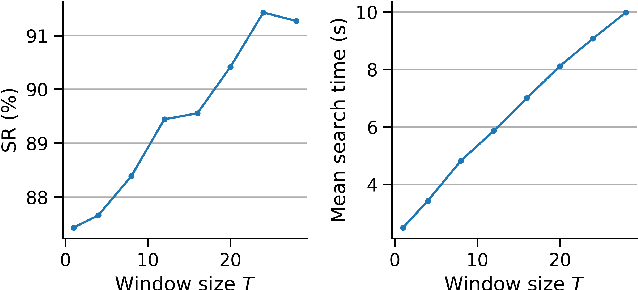

Picking a specific object from clutter is an essential component of many manipulation tasks. Partial observations often require the robot to collect additional views of the scene before attempting a grasp. This paper proposes a closed-loop next-best-view planner that drives exploration based on occluded object parts. By continuously predicting grasps from an up-to-date scene reconstruction, our policy can decide online to finalize a grasp execution or to adapt the robot's trajectory for further exploration. We show that our reactive approach decreases execution times without loss of grasp success rates compared to common camera placements and handles situations where the fixed baselines fail. Video and code are available at https://github.com/ethz-asl/active_grasp.
Probabilistic network topology prediction for active planning:An adaptive algorithm and application
Jun 27, 2022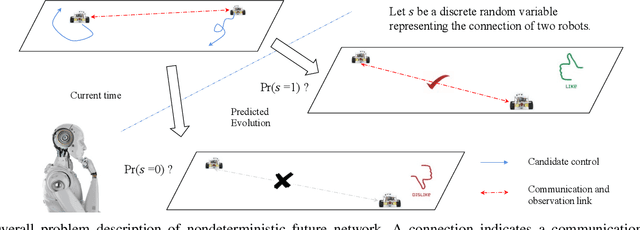
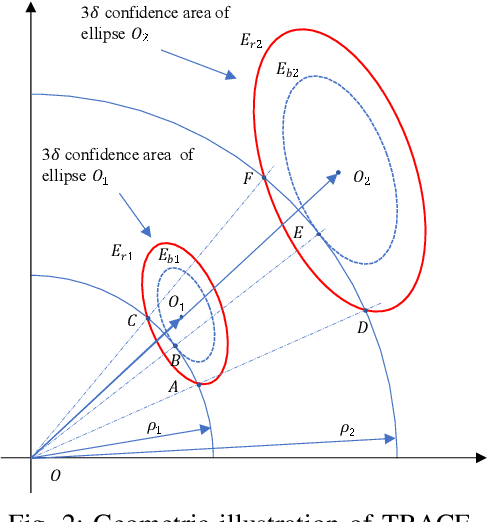

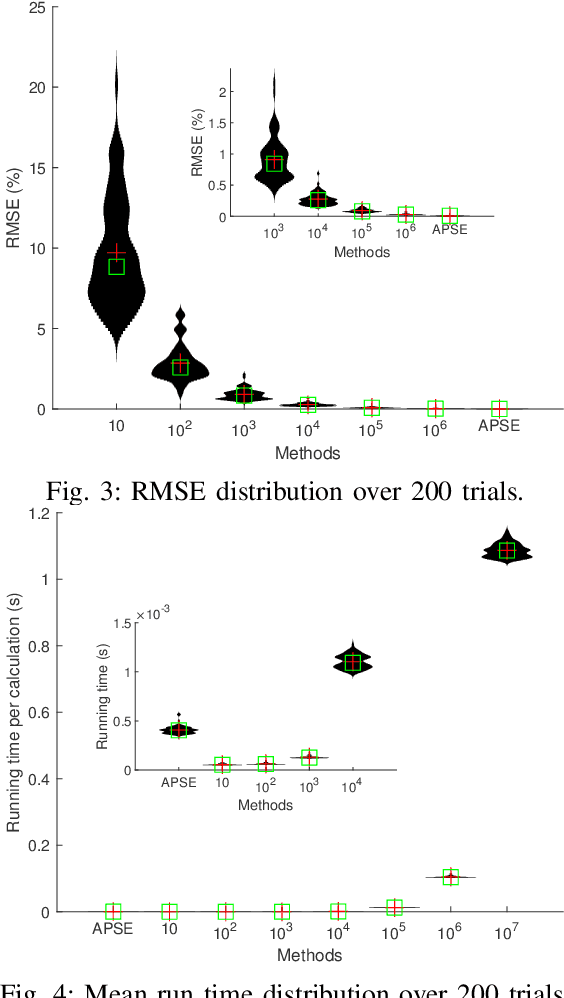
This paper tackles the problem of active planning to achieve cooperative localization for multi-robot systems (MRS) under measurement uncertainty in GNSS-limited scenarios. Specifically, we address the issue of accurately predicting the probability of a future connection between two robots equipped with range-based measurement devices. Due to the limited range of the equipped sensors, edges in the network connection topology will be created or destroyed as the robots move with respect to one another. Accurately predicting the future existence of an edge, given imperfect state estimation and noisy actuation, is therefore a challenging task. An adaptive power series expansion (or APSE) algorithm is developed based on current estimates and control candidates. Such an algorithm applies the power series expansion formula of the quadratic positive form in a normal distribution. Finite-term approximation is made to realize the computational tractability. Further analyses are presented to show that the truncation error in the finite-term approximation can be theoretically reduced to a desired threshold by adaptively choosing the summation degree of the power series. Several sufficient conditions are rigorously derived as the selection principles. Finally, extensive simulation results and comparisons, with respect to both single and multi-robot cases, validate that a formally computed and therefore more accurate probability of future topology can help improve the performance of active planning under uncertainty.
NavDreams: Towards Camera-Only RL Navigation Among Humans
Mar 23, 2022
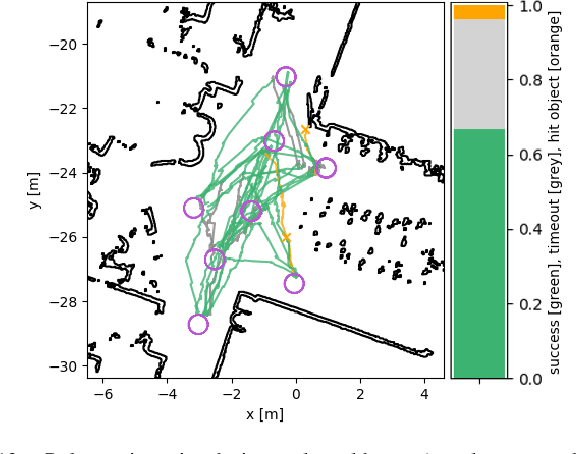
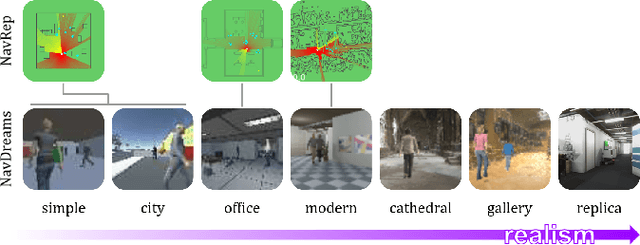
Autonomously navigating a robot in everyday crowded spaces requires solving complex perception and planning challenges. When using only monocular image sensor data as input, classical two-dimensional planning approaches cannot be used. While images present a significant challenge when it comes to perception and planning, they also allow capturing potentially important details, such as complex geometry, body movement, and other visual cues. In order to successfully solve the navigation task from only images, algorithms must be able to model the scene and its dynamics using only this channel of information. We investigate whether the world model concept, which has shown state-of-the-art results for modeling and learning policies in Atari games as well as promising results in 2D LiDAR-based crowd navigation, can also be applied to the camera-based navigation problem. To this end, we create simulated environments where a robot must navigate past static and moving humans without colliding in order to reach its goal. We find that state-of-the-art methods are able to achieve success in solving the navigation problem, and can generate dream-like predictions of future image-sequences which show consistent geometry and moving persons. We are also able to show that policy performance in our high-fidelity sim2real simulation scenario transfers to the real world by testing the policy on a real robot. We make our simulator, models and experiments available at https://github.com/danieldugas/NavDreams.
Descriptellation: Deep Learned Constellation Descriptors for SLAM
Mar 01, 2022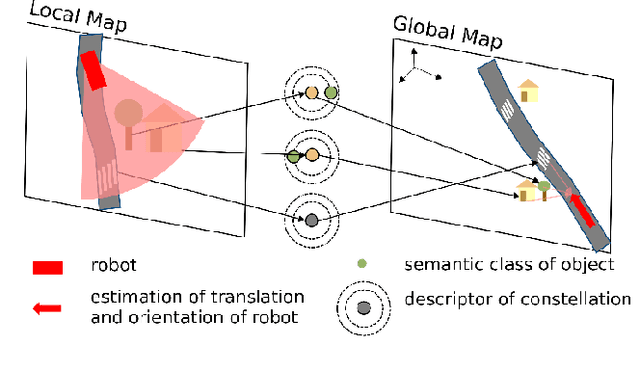
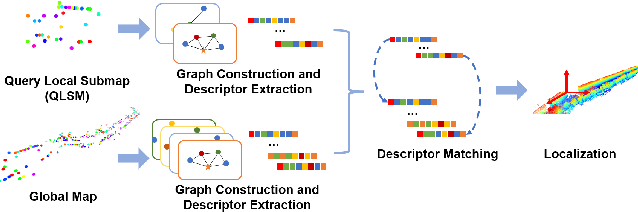
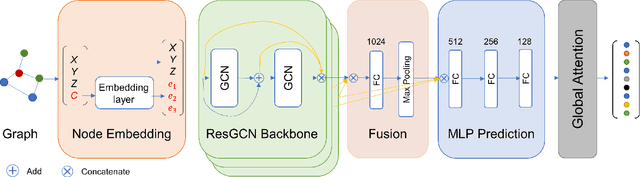
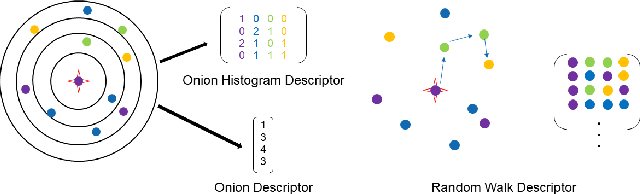
Current global localization descriptors in Simultaneous Localization and Mapping (SLAM) often fail under vast viewpoint or appearance changes. Adding topological information of semantic objects into the descriptors ameliorates the problem. However, hand-crafted topological descriptors extract limited information and they are not robust to environmental noise, drastic perspective changes, or object occlusion or misdetections. To solve this problem, we formulate a learning-based approach by constructing constellations from semantically meaningful objects and use Deep Graph Convolution Networks to map the constellation representation to a descriptor. We demonstrate the effectiveness of our Deep Learned Constellation Descriptor (Descriptellation) on the Paris-Rue-Lille and IQmulus datasets. Although Descriptellation is trained on randomly generated simulation datasets, it shows good generalization abilities on real-world datasets. Descriptellation outperforms the PointNet and handcrafted constellation descriptors for global localization, and shows robustness against different types of noise.
Semi-automatic 3D Object Keypoint Annotation and Detection for the Masses
Jan 19, 2022
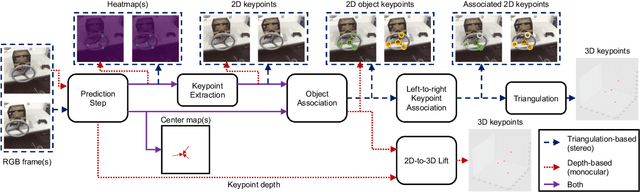

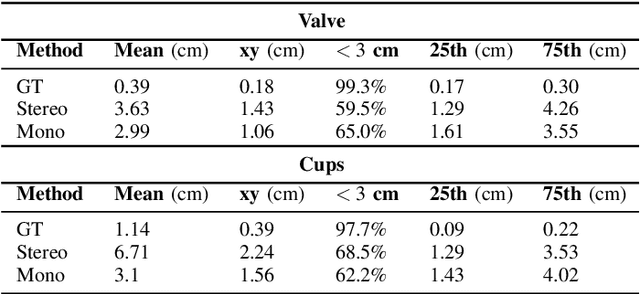
Creating computer vision datasets requires careful planning and lots of time and effort. In robotics research, we often have to use standardized objects, such as the YCB object set, for tasks such as object tracking, pose estimation, grasping and manipulation, as there are datasets and pre-learned methods available for these objects. This limits the impact of our research since learning-based computer vision methods can only be used in scenarios that are supported by existing datasets. In this work, we present a full object keypoint tracking toolkit, encompassing the entire process from data collection, labeling, model learning and evaluation. We present a semi-automatic way of collecting and labeling datasets using a wrist mounted camera on a standard robotic arm. Using our toolkit and method, we are able to obtain a working 3D object keypoint detector and go through the whole process of data collection, annotation and learning in just a couple hours of active time.
Under the Sand: Navigation and Localization of a Small Unmanned Aerial Vehicle for Landmine Detection with Ground Penetrating Synthetic Aperture Radar
Jun 18, 2021
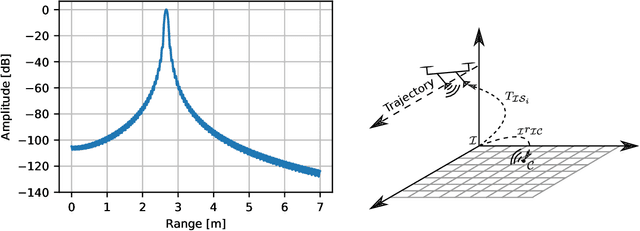
Ground penetrating radar mounted on a small unmanned aerial vehicle (UAV) is a promising tool to assist humanitarian landmine clearance. However, the quality of synthetic aperture radar images depends on accurate and precise motion estimation of the radar antennas as well as generating informative viewpoints with the UAV. This paper presents a complete and automatic airborne ground-penetrating synthetic aperture radar (GPSAR) system. The system consists of a spatially calibrated and temporally synchronized industrial grade sensor suite that enables navigation above ground level, radar imaging, and optical imaging. A custom mission planning framework allows generation and automatic execution of stripmap and circular GPSAR trajectories controlled above ground level as well as aerial imaging survey flights. A factor graph based state estimator fuses measurements from dual receiver real-time kinematic (RTK) global navigation satellite system (GNSS) and an inertial measurement unit (IMU) to obtain precise, high rate platform positions and orientations. Ground truth experiments showed sensor timing as accurate as 0.8 {\mu}s and as precise as 0.1 {\mu}s with localization rates of 1 kHz. The dual position factor formulation improves online localization accuracy up to 40 % and batch localization accuracy up to 59 % compared to a single position factor with uncertain heading initialization. Our field trials validated a localization accuracy and precision that enables coherent radar measurement addition and detection of radar targets buried in sand. This validates the potential as an aerial landmine detection system.
CalQNet -- Detection of Calibration Quality for Life-Long Stereo Camera Setups
Apr 10, 2021
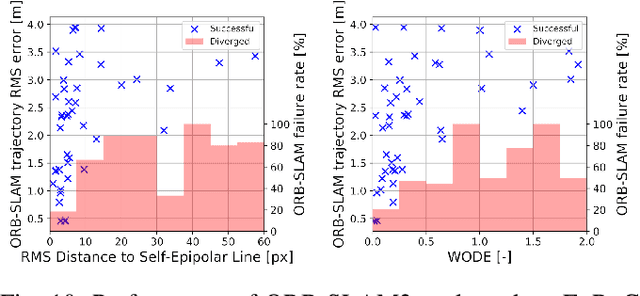

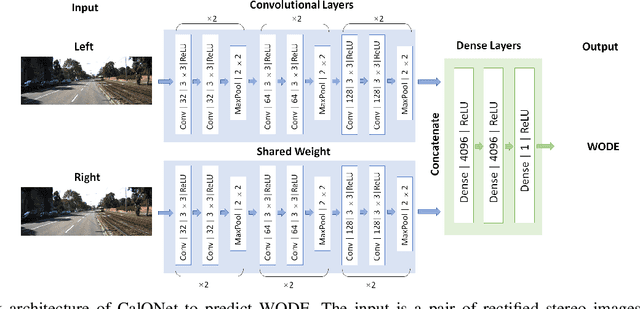
Many mobile robotic platforms rely on an accurate knowledge of the extrinsic calibration parameters, especially systems performing visual stereo matching. Although a number of accurate stereo camera calibration methods have been developed, which provide good initial "factory" calibrations, the determined parameters can lose their validity over time as the sensors are exposed to environmental conditions and external effects. Thus, on autonomous platforms on-board diagnostic methods for an early detection of the need to repeat calibration procedures have the potential to prevent critical failures of crucial systems, such as state estimation or obstacle detection. In this work, we present a novel data-driven method to estimate the calibration quality and detect discrepancies between the original calibration and the current system state for stereo camera systems. The framework consists of a novel dataset generation pipeline to train CalQNet, a deep convolutional neural network. CalQNet can estimate the calibration quality using a new metric that approximates the degree of miscalibration in stereo setups. We show the framework's ability to predict from a single stereo frame if a state-of-the-art stereo-visual odometry system will diverge due to a degraded calibration in two real-world experiments.