 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Based Generative Modeling through Stochastic Differential Equations
Nov 26, 2020
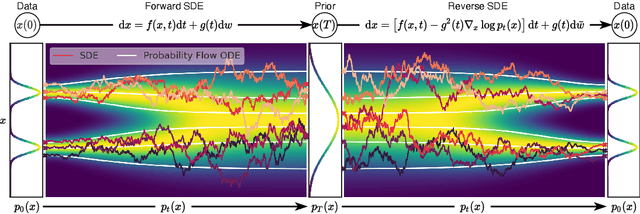

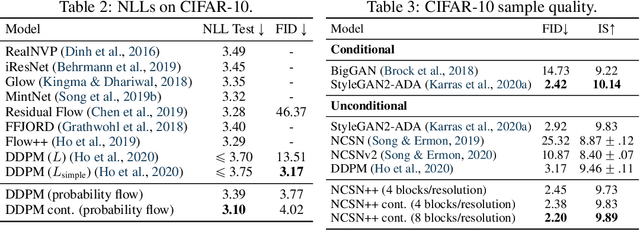
Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (a.k.a., score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in diffusion probabilistic modeling and score-based generative modeling, and allows for new sampling procedures. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, which enables exact likelihood computation, and improved sampling efficiency. In addition, our framework enables conditional generation with an unconditional model, as we demonstrate with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 3.10 bits/dim, and demonstrate high fidelity generation of $1024 \times 1024$ images for the first time from a score-based generative model.
Towards NNGP-guided Neural Architecture Search
Nov 11, 2020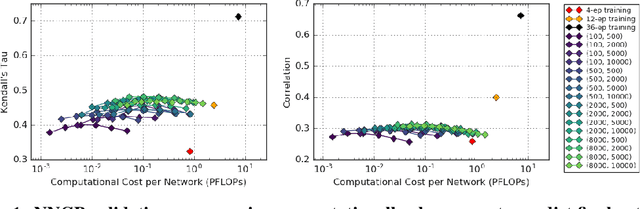
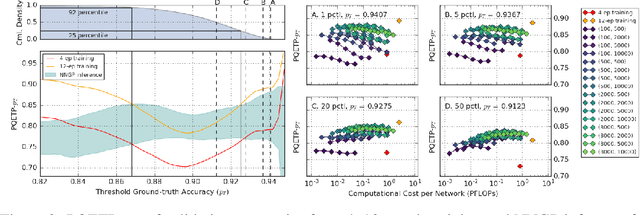
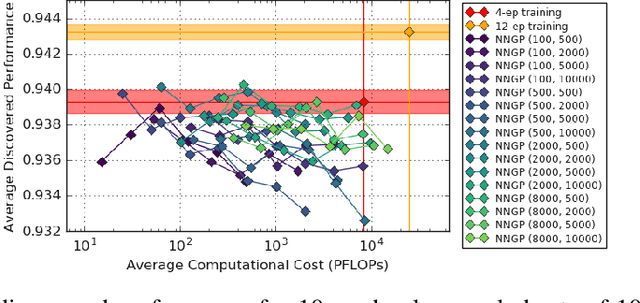

The predictions of wide Bayesian neural networks are described by a Gaussian process, known as the Neural Network Gaussian Process (NNGP). Analytic forms for NNGP kernels are known for many models, but computing the exact kernel for convolutional architectures is prohibitively expensive. One can obtain effective approximations of these kernels through Monte-Carlo estimation using finite networks at initialization. Monte-Carlo NNGP inference is orders-of-magnitude cheaper in FLOPs compared to gradient descent training when the dataset size is small. Since NNGP inference provides a cheap measure of performance of a network architecture, we investigate its potential as a signal for neural architecture search (NAS). We compute the NNGP performance of approximately 423k networks in the NAS-bench 101 dataset on CIFAR-10 and compare its utility against conventional performance measures obtained by shortened gradient-based training. We carry out a similar analysis on 10k randomly sampled networks in the mobile neural architecture search (MNAS) space for ImageNet. We discover comparative advantages of NNGP-based metrics, and discuss potential applications. In particular, we propose that NNGP performance is an inexpensive signal independent of metrics obtained from training that can either be used for reducing big search spaces, or improving training-based performance measures.
Reverse engineering learned optimizers reveals known and novel mechanisms
Nov 04, 2020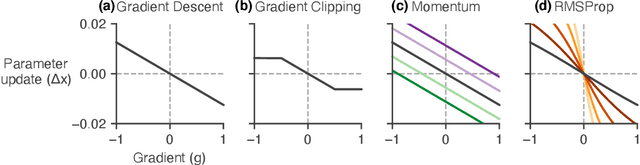
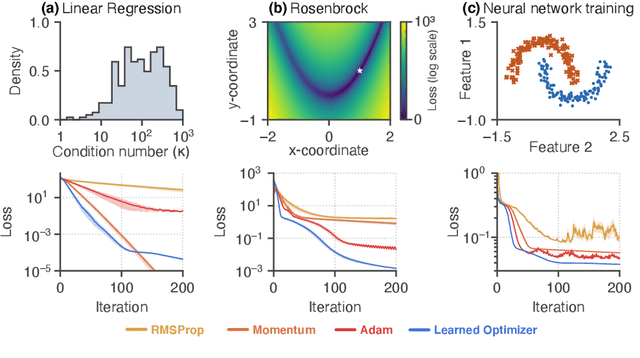
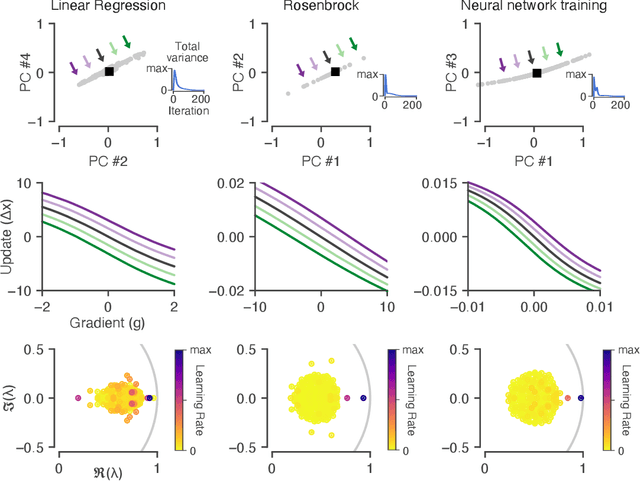
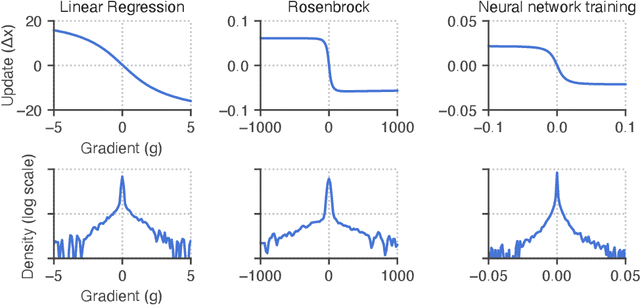
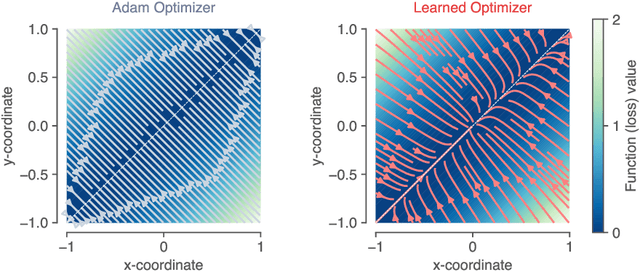
Learned optimizers are algorithms that can themselves be trained to solve optimization problems. In contrast to baseline optimizers (such as momentum or Adam) that use simple update rules derived from theoretical principles, learned optimizers use flexible, high-dimensional, nonlinear parameterizations. Although this can lead to better performance in certain settings, their inner workings remain a mystery. How is a learned optimizer able to outperform a well tuned baseline? Has it learned a sophisticated combination of existing optimization techniques, or is it implementing completely new behavior? In this work, we address these questions by careful analysis and visualization of learned optimizers. We study learned optimizers trained from scratch on three disparate tasks, and discover that they have learned interpretable mechanisms, including: momentum, gradient clipping, learning rate schedules, and a new form of learning rate adaptation. Moreover, we show how the dynamics of learned optimizers enables these behaviors. Our results help elucidate the previously murky understanding of how learned optimizers work, and establish tools for interpreting future learned optimizers.
Is Batch Norm unique? An empirical investigation and prescription to emulate the best properties of common normalizers without batch dependence
Oct 21, 2020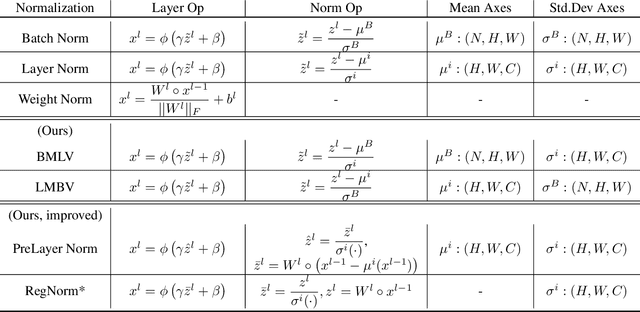
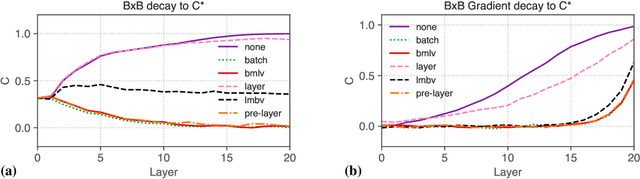
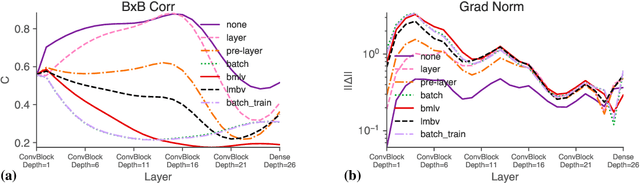
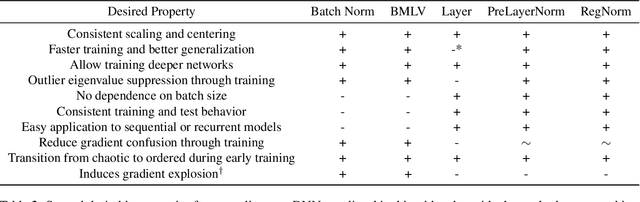
We perform an extensive empirical study of the statistical properties of Batch Norm and other common normalizers. This includes an examination of the correlation between representations of minibatches, gradient norms, and Hessian spectra both at initialization and over the course of training. Through this analysis, we identify several statistical properties which appear linked to Batch Norm's superior performance. We propose two simple normalizers, PreLayerNorm and RegNorm, which better match these desirable properties without involving operations along the batch dimension. We show that PreLayerNorm and RegNorm achieve much of the performance of Batch Norm without requiring batch dependence, that they reliably outperform LayerNorm, and that they can be applied in situations where Batch Norm is ineffective.
Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
Sep 23, 2020
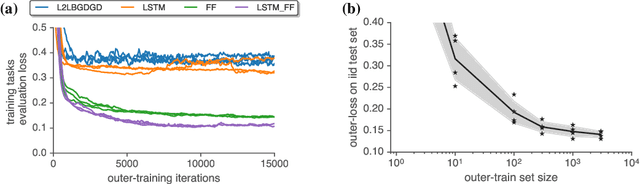
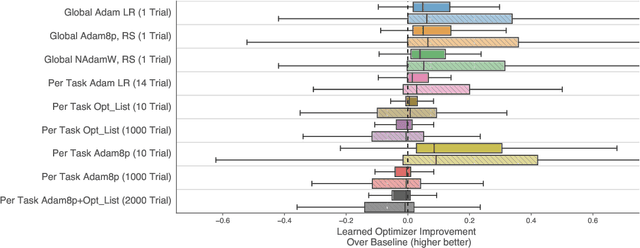
Much as replacing hand-designed features with learned functions has revolutionized how we solve perceptual tasks, we believe learned algorithms will transform how we train models. In this work we focus on general-purpose learned optimizers capable of training a wide variety of problems with no user-specified hyperparameters. We introduce a new, neural network parameterized, hierarchical optimizer with access to additional features such as validation loss to enable automatic regularization. Most learned optimizers have been trained on only a single task, or a small number of tasks. We train our optimizers on thousands of tasks, making use of orders of magnitude more compute, resulting in optimizers that generalize better to unseen tasks. The learned optimizers not only perform well, but learn behaviors that are distinct from existing first order optimizers. For instance, they generate update steps that have implicit regularization and adapt as the problem hyperparameters (e.g. batch size) or architecture (e.g. neural network width) change. Finally, these learned optimizers show evidence of being useful for out of distribution tasks such as training themselves from scratch.
Finite Versus Infinite Neural Networks: an Empirical Study
Sep 08, 2020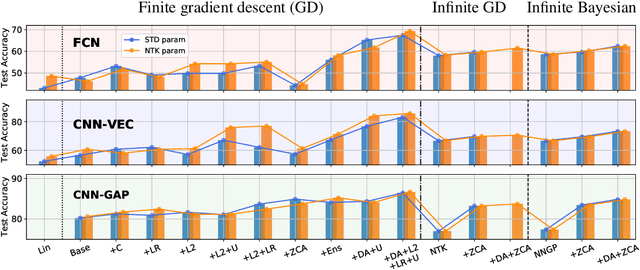



We perform a careful, thorough, and large scale empirical study of the correspondence between wide neural networks and kernel methods. By doing so, we resolve a variety of open questions related to the study of infinitely wide neural networks. Our experimental results include: kernel methods outperform fully-connected finite-width networks, but underperform convolutional finite width networks; neural network Gaussian process (NNGP) kernels frequently outperform neural tangent (NT) kernels; centered and ensembled finite networks have reduced posterior variance and behave more similarly to infinite networks; weight decay and the use of a large learning rate break the correspondence between finite and infinite networks; the NTK parameterization outperforms the standard parameterization for finite width networks; diagonal regularization of kernels acts similarly to early stopping; floating point precision limits kernel performance beyond a critical dataset size; regularized ZCA whitening improves accuracy; finite network performance depends non-monotonically on width in ways not captured by double descent phenomena; equivariance of CNNs is only beneficial for narrow networks far from the kernel regime. Our experiments additionally motivate an improved layer-wise scaling for weight decay which improves generalization in finite-width networks. Finally, we develop improved best practices for using NNGP and NT kernels for prediction, including a novel ensembling technique. Using these best practices we achieve state-of-the-art results on CIFAR-10 classification for kernels corresponding to each architecture class we consider.
Whitening and second order optimization both destroy information about the dataset, and can make generalization impossible
Aug 25, 2020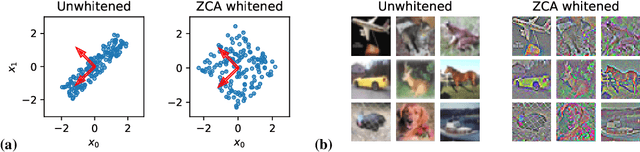
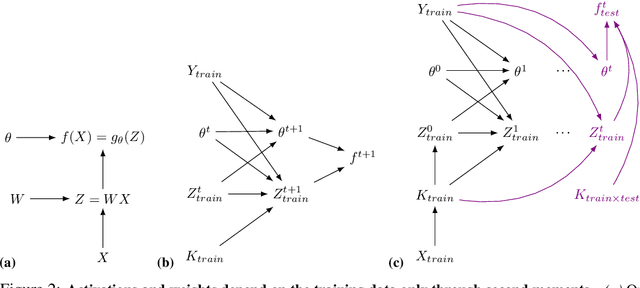
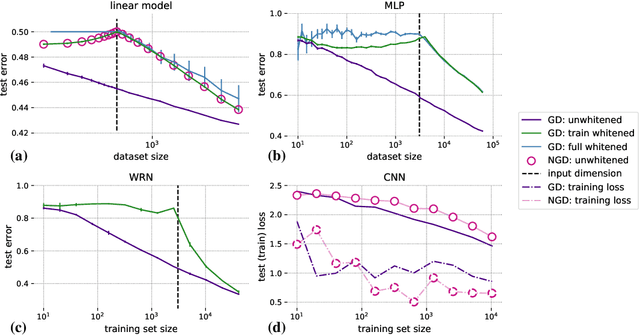
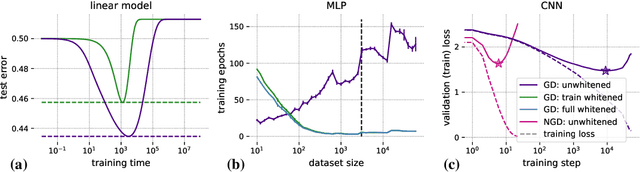
Machine learning is predicated on the concept of generalization: a model achieving low error on a sufficiently large training set should also perform well on novel samples from the same distribution. We show that both data whitening and second order optimization can harm or entirely prevent generalization. In general, model training harnesses information contained in the sample-sample second moment matrix of a dataset. For a general class of models, namely models with a fully connected first layer, we prove that the information contained in this matrix is the only information which can be used to generalize. Models trained using whitened data, or with certain second order optimization schemes, have less access to this information; in the high dimensional regime they have no access at all, producing models that generalize poorly or not at all. We experimentally verify these predictions for several architectures, and further demonstrate that generalization continues to be harmed even when theoretical requirements are relaxed. However, we also show experimentally that regularized second order optimization can provide a practical tradeoff, where training is still accelerated but less information is lost, and generalization can in some circumstances even improve.
A new method for parameter estimation in probabilistic models: Minimum probability flow
Jul 17, 2020
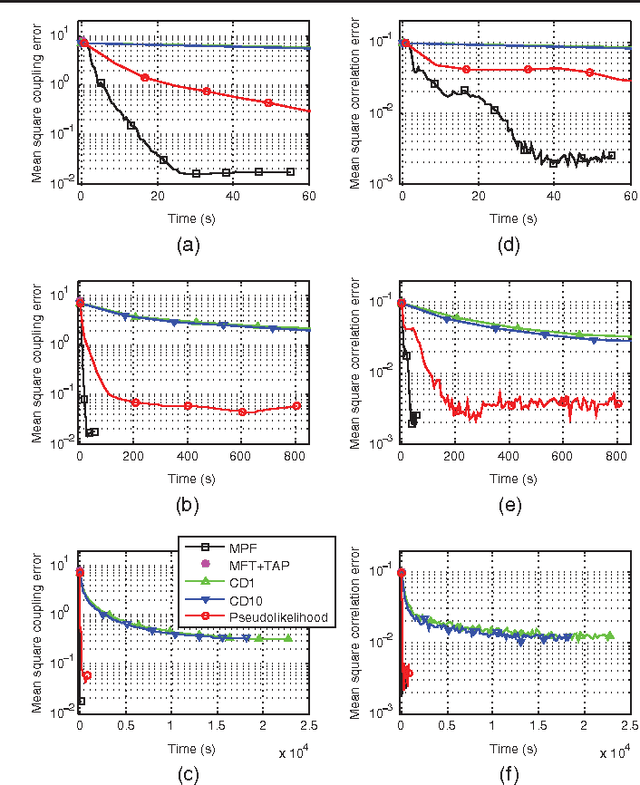

Fitting probabilistic models to data is often difficult, due to the general intractability of the partition function. We propose a new parameter fitting method, Minimum Probability Flow (MPF), which is applicable to any parametric model. We demonstrate parameter estimation using MPF in two cases: a continuous state space model, and an Ising spin glass. In the latter case it outperforms current techniques by at least an order of magnitude in convergence time with lower error in the recovered coupling parameters.
Exact posterior distributions of wide Bayesian neural networks
Jun 18, 2020
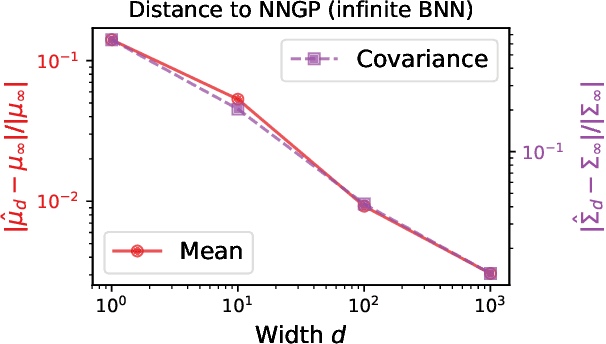
Recent work has shown that the prior over functions induced by a deep Bayesian neural network (BNN) behaves as a Gaussian process (GP) as the width of all layers becomes large. However, many BNN applications are concerned with the BNN function space posterior. While some empirical evidence of the posterior convergence was provided in the original works of Neal (1996) and Matthews et al. (2018), it is limited to small datasets or architectures due to the notorious difficulty of obtaining and verifying exactness of BNN posterior approximations. We provide the missing theoretical proof that the exact BNN posterior converges (weakly) to the one induced by the GP limit of the prior. For empirical validation, we show how to generate exact samples from a finite BNN on a small dataset via rejection sampling.
Infinite attention: NNGP and NTK for deep attention networks
Jun 18, 2020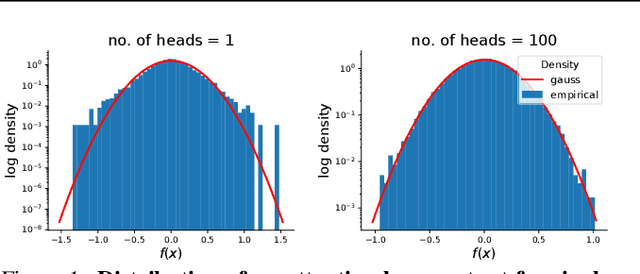

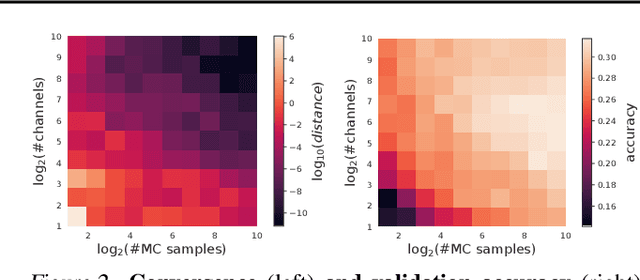

There is a growing amount of literature on the relationship between wide neural networks (NNs) and Gaussian processes (GPs), identifying an equivalence between the two for a variety of NN architectures. This equivalence enables, for instance, accurate approximation of the behaviour of wide Bayesian NNs without MCMC or variational approximations, or characterisation of the distribution of randomly initialised wide NNs optimised by gradient descent without ever running an optimiser. We provide a rigorous extension of these results to NNs involving attention layers, showing that unlike single-head attention, which induces non-Gaussian behaviour, multi-head attention architectures behave as GPs as the number of heads tends to infinity. We further discuss the effects of positional encodings and layer normalisation, and propose modifications of the attention mechanism which lead to improved results for both finite and infinitely wide NNs. We evaluate attention kernels empirically, leading to a moderate improvement upon the previous state-of-the-art on CIFAR-10 for GPs without trainable kernels and advanced data preprocessing. Finally, we introduce new features to the Neural Tangents library (Novak et al., 2020) allowing applications of NNGP/NTK models, with and without attention, to variable-length sequences, with an example on the IMDb reviews dataset.