 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan VAEs Generate Novel Examples?
Dec 22, 2018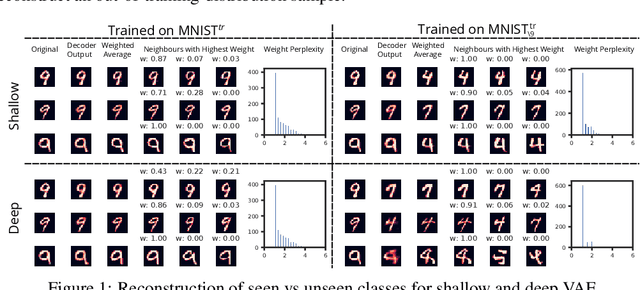
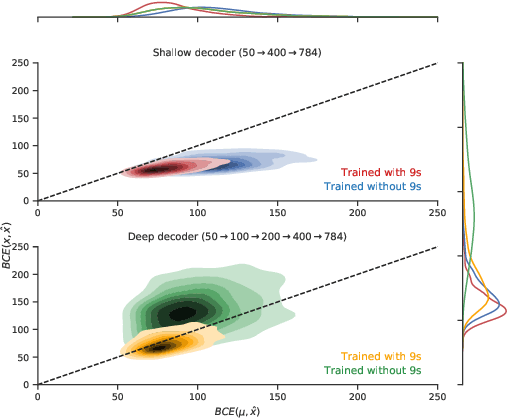

An implicit goal in works on deep generative models is that such models should be able to generate novel examples that were not previously seen in the training data. In this paper, we investigate to what extent this property holds for widely employed variational autoencoder (VAE) architectures. VAEs maximize a lower bound on the log marginal likelihood, which implies that they will in principle overfit the training data when provided with a sufficiently expressive decoder. In the limit of an infinite capacity decoder, the optimal generative model is a uniform mixture over the training data. More generally, an optimal decoder should output a weighted average over the examples in the training data, where the magnitude of the weights is determined by the proximity in the latent space. This leads to the hypothesis that, for a sufficiently high capacity encoder and decoder, the VAE decoder will perform nearest-neighbor matching according to the coordinates in the latent space. To test this hypothesis, we investigate generalization on the MNIST dataset. We consider both generalization to new examples of previously seen classes, and generalization to the classes that were withheld from the training set. In both cases, we find that reconstructions are closely approximated by nearest neighbors for higher-dimensional parameterizations. When generalizing to unseen classes however, lower-dimensional parameterizations offer a clear advantage.
Modeling Theory of Mind for Autonomous Agents with Probabilistic Programs
Dec 04, 2018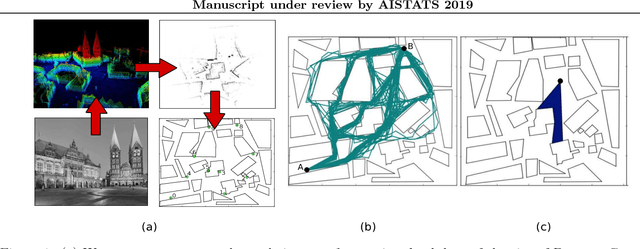

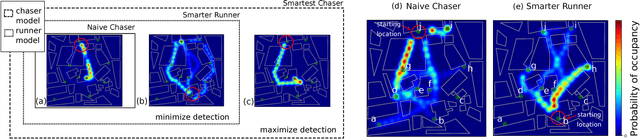
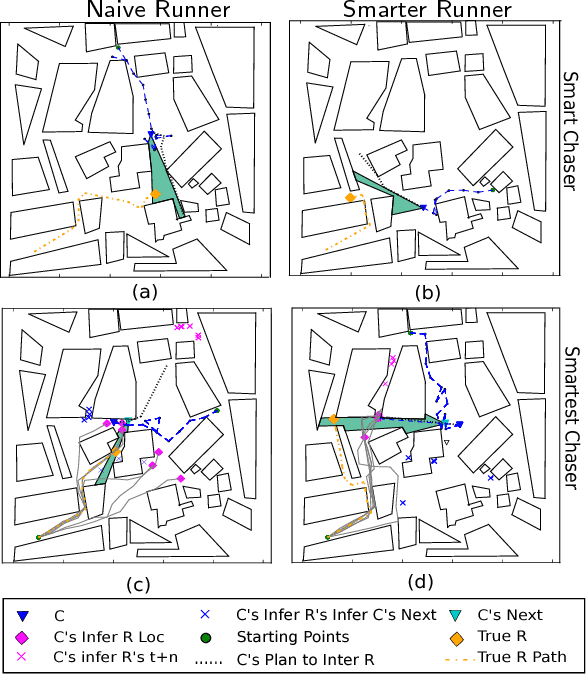
As autonomous agents become more ubiquitous, they will eventually have to reason about the mental state of other agents, including those agents' beliefs, desires and goals - so-called theory of mind reasoning. We introduce a collection of increasingly complex theory of mind models of a "chaser" pursuing a "runner", known as the Chaser-Runner model. We show that our implementation is a relatively straightforward theory of mind model that can capture a variety of rich behaviors, which in turn, increase runner detection rates relative to basic (non-theory-of-mind) models. In addition, our paper demonstrates that (1) using a planning-as-inference formulation based on nested importance sampling results in agents simultaneously reasoning about other agents' plans and crafting counter-plans, (2) probabilistic programming is a natural way to describe models in which each uses complex primitives such as path planners to make decisions, and (3) allocating additional computation to perform nested reasoning about agents result in lower-variance estimates of expected utility.
Composing Modeling and Inference Operations with Probabilistic Program Combinators
Nov 29, 2018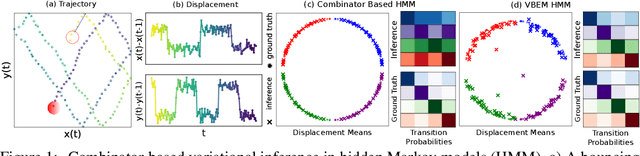

Probabilistic programs with dynamic computation graphs can define measures over sample spaces with unbounded dimensionality, which constitute programmatic analogues to Bayesian nonparametrics. Owing to the generality of this model class, inference relies on `black-box' Monte Carlo methods that are often not able to take advantage of conditional independence and exchangeability, which have historically been the cornerstones of efficient inference. We here seek to develop a `middle ground' between probabilistic models with fully dynamic and fully static computation graphs. To this end, we introduce a combinator library for the Probabilistic Torch framework. Combinators are functions that accept models and return transformed models. We assume that models are dynamic, but that model composition is static, in the sense that combinator application takes place prior to evaluating the model on data. Combinators provide primitives for both model and inference composition. Model combinators take the form of classic functional programming constructs such as map and reduce. These constructs define a computation graph at a coarsened level of representation, in which nodes correspond to models, rather than individual variables. Inference combinators implement operations such as importance resampling and application of a transition kernel, which alter the evaluation strategy for a model whilst preserving proper weighting. Owing to this property, models defined using combinators can be trained using stochastic methods that optimize either variational or wake-sleep style objectives. As a validation of this principle, we use combinators to implement black box inference for hidden Markov models.
On Exploration, Exploitation and Learning in Adaptive Importance Sampling
Oct 31, 2018



We study adaptive importance sampling (AIS) as an online learning problem and argue for the importance of the trade-off between exploration and exploitation in this adaptation. Borrowing ideas from the bandits literature, we propose Daisee, a partition-based AIS algorithm. We further introduce a notion of regret for AIS and show that Daisee has $\mathcal{O}(\sqrt{T}(\log T)^{\frac{3}{4}})$ cumulative pseudo-regret, where $T$ is the number of iterations. We then extend Daisee to adaptively learn a hierarchical partitioning of the sample space for more efficient sampling and confirm the performance of both algorithms empirically.
An Introduction to Probabilistic Programming
Sep 27, 2018
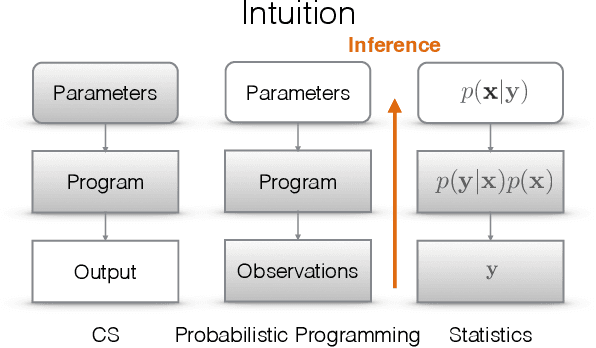


This document is designed to be a first-year graduate-level introduction to probabilistic programming. It not only provides a thorough background for anyone wishing to use a probabilistic programming system, but also introduces the techniques needed to design and build these systems. It is aimed at people who have an undergraduate-level understanding of either or, ideally, both probabilistic machine learning and programming languages. We start with a discussion of model-based reasoning and explain why conditioning as a foundational computation is central to the fields of probabilistic machine learning and artificial intelligence. We then introduce a simple first-order probabilistic programming language (PPL) whose programs define static-computation-graph, finite-variable-cardinality models. In the context of this restricted PPL we introduce fundamental inference algorithms and describe how they can be implemented in the context of models denoted by probabilistic programs. In the second part of this document, we introduce a higher-order probabilistic programming language, with a functionality analogous to that of established programming languages. This affords the opportunity to define models with dynamic computation graphs, at the cost of requiring inference methods that generate samples by repeatedly executing the program. Foundational inference algorithms for this kind of probabilistic programming language are explained in the context of an interface between program executions and an inference controller. This document closes with a chapter on advanced topics which we believe to be, at the time of writing, interesting directions for probabilistic programming research; directions that point towards a tight integration with deep neural network research and the development of systems for next-generation artificial intelligence applications.
Learning Disentangled Representations of Texts with Application to Biomedical Abstracts
Sep 03, 2018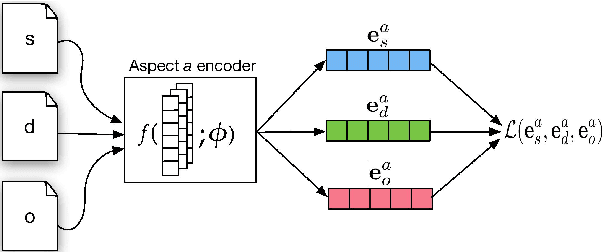
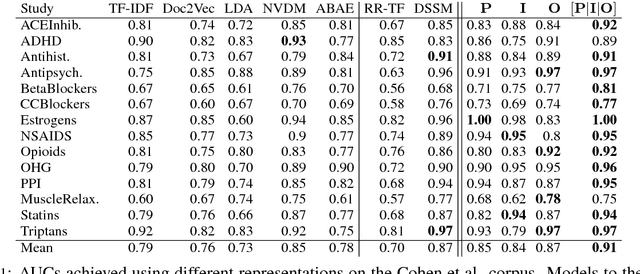
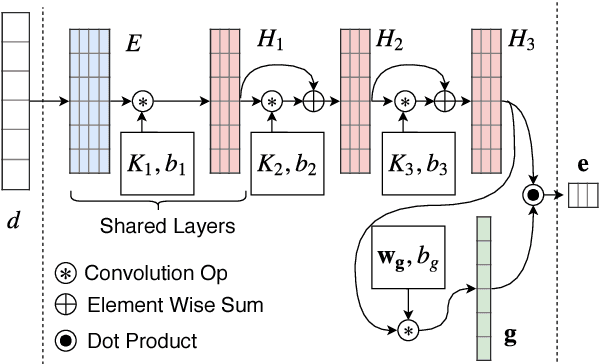

We propose a method for learning disentangled representations of texts that code for distinct and complementary aspects, with the aim of affording efficient model transfer and interpretability. To induce disentangled embeddings, we propose an adversarial objective based on the (dis)similarity between triplets of documents with respect to specific aspects. Our motivating application is embedding biomedical abstracts describing clinical trials in a manner that disentangles the populations, interventions, and outcomes in a given trial. We show that our method learns representations that encode these clinically salient aspects, and that these can be effectively used to perform aspect-specific retrieval. We demonstrate that the approach generalizes beyond our motivating application in experiments on two multi-aspect review corpora.
Inference Trees: Adaptive Inference with Exploration
Jun 25, 2018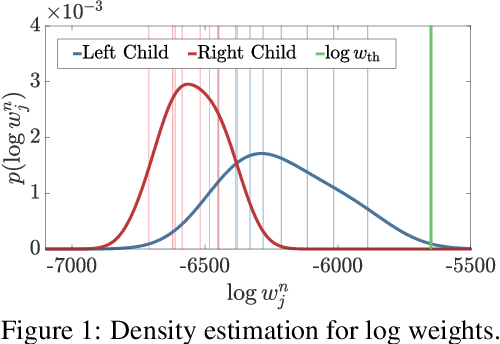
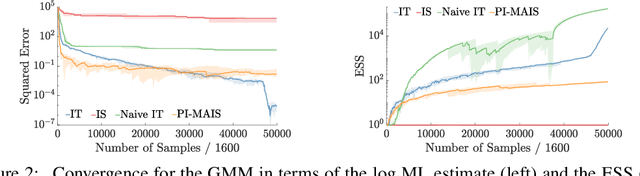
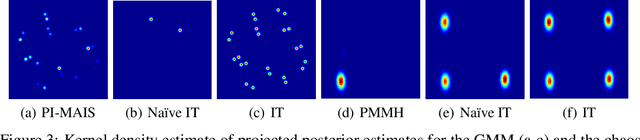
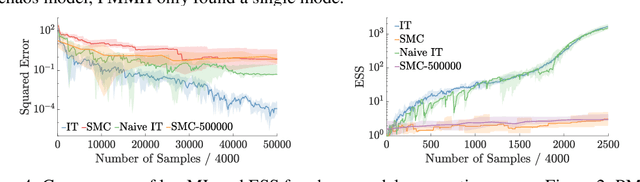
We introduce inference trees (ITs), a new class of inference methods that build on ideas from Monte Carlo tree search to perform adaptive sampling in a manner that balances exploration with exploitation, ensures consistency, and alleviates pathologies in existing adaptive methods. ITs adaptively sample from hierarchical partitions of the parameter space, while simultaneously learning these partitions in an online manner. This enables ITs to not only identify regions of high posterior mass, but also maintain uncertainty estimates to track regions where significant posterior mass may have been missed. ITs can be based on any inference method that provides a consistent estimate of the marginal likelihood. They are particularly effective when combined with sequential Monte Carlo, where they capture long-range dependencies and yield improvements beyond proposal adaptation alone.
Structured Disentangled Representations
May 29, 2018



Deep latent-variable models learn representations of high-dimensional data in an unsupervised manner. A number of recent efforts have focused on learning representations that disentangle statistically independent axes of variation by introducing modifications to the standard objective function. These approaches generally assume a simple diagonal Gaussian prior and as a result are not able to reliably disentangle discrete factors of variation. We propose a two-level hierarchical objective to control relative degree of statistical independence between blocks of variables and individual variables within blocks. We derive this objective as a generalization of the evidence lower bound, which allows us to explicitly represent the trade-offs between mutual information between data and representation, KL divergence between representation and prior, and coverage of the support of the empirical data distribution. Experiments on a variety of datasets demonstrate that our objective can not only disentangle discrete variables, but that doing so also improves disentanglement of other variables and, importantly, generalization even to unseen combinations of factors.
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017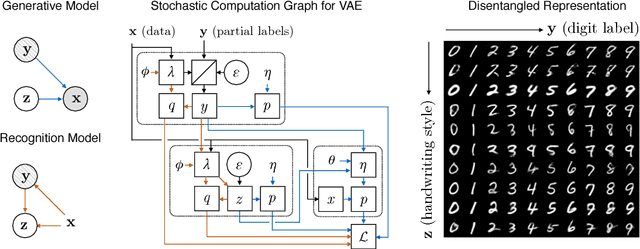

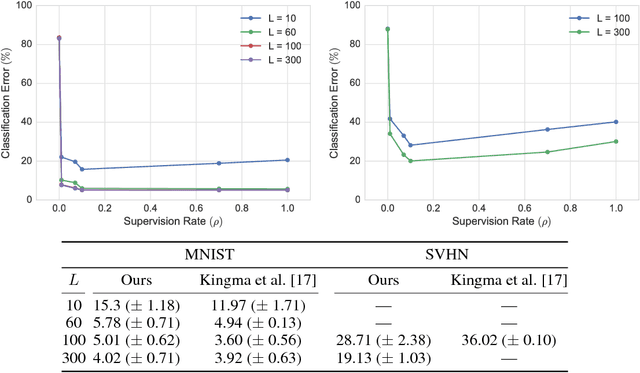
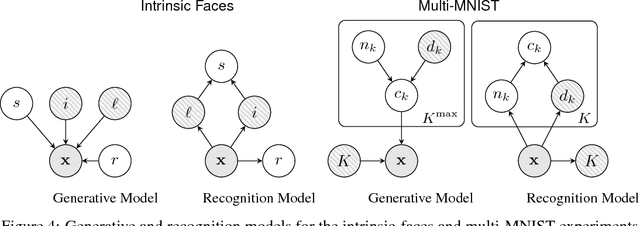
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.
Bayesian Optimization for Probabilistic Programs
Jul 13, 2017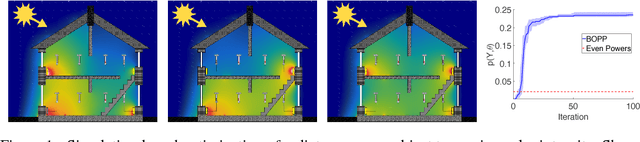
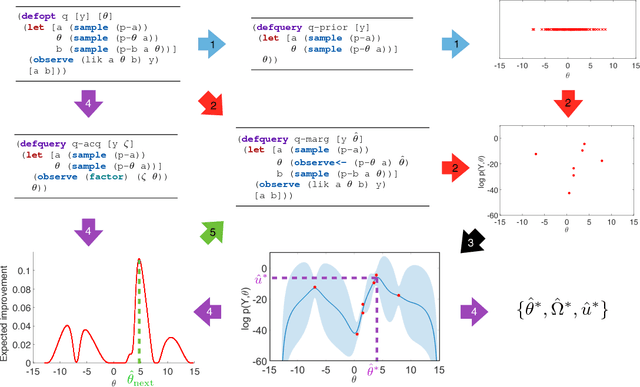
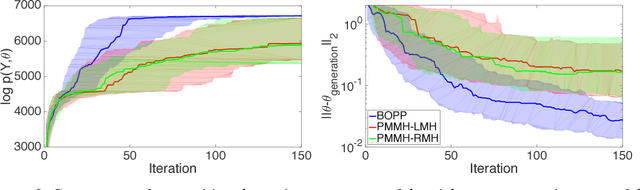
We present the first general purpose framework for marginal maximum a posteriori estimation of probabilistic program variables. By using a series of code transformations, the evidence of any probabilistic program, and therefore of any graphical model, can be optimized with respect to an arbitrary subset of its sampled variables. To carry out this optimization, we develop the first Bayesian optimization package to directly exploit the source code of its target, leading to innovations in problem-independent hyperpriors, unbounded optimization, and implicit constraint satisfaction; delivering significant performance improvements over prominent existing packages. We present applications of our method to a number of tasks including engineering design and parameter optimization.