 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Biomechanically-constrained CT/MRI Registration of the Spine
May 16, 2022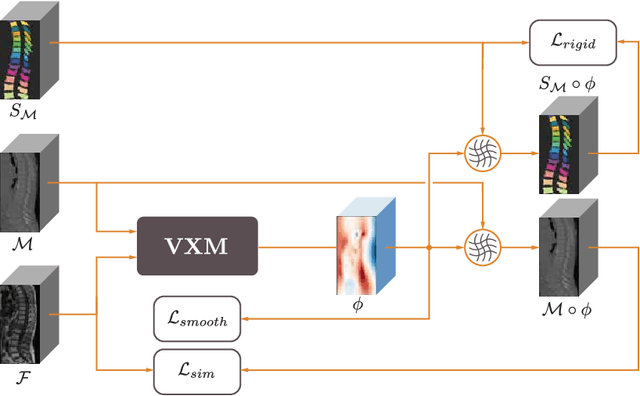
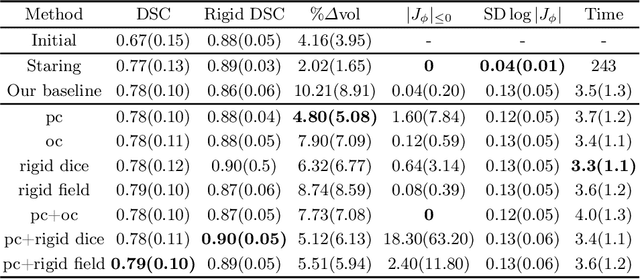
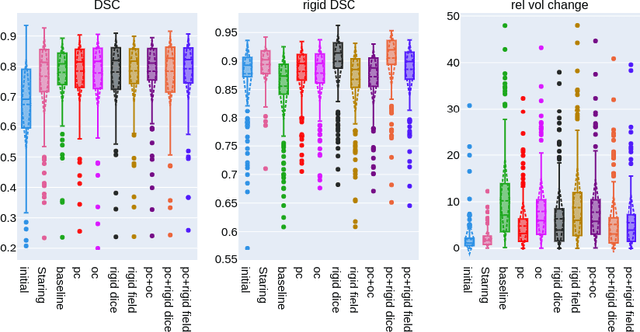

CT and MRI are two of the most informative modalities in spinal diagnostics and treatment planning. CT is useful when analysing bony structures, while MRI gives information about the soft tissue. Thus, fusing the information of both modalities can be very beneficial. Registration is the first step for this fusion. While the soft tissues around the vertebra are deformable, each vertebral body is constrained to move rigidly. We propose a weakly-supervised deep learning framework that preserves the rigidity and the volume of each vertebra while maximizing the accuracy of the registration. To achieve this goal, we introduce anatomy-aware losses for training the network. We specifically design these losses to depend only on the CT label maps since automatic vertebra segmentation in CT gives more accurate results contrary to MRI. We evaluate our method on an in-house dataset of 167 patients. Our results show that adding the anatomy-aware losses increases the plausibility of the inferred transformation while keeping the accuracy untouched.
Interpretable Vertebral Fracture Diagnosis
Mar 30, 2022
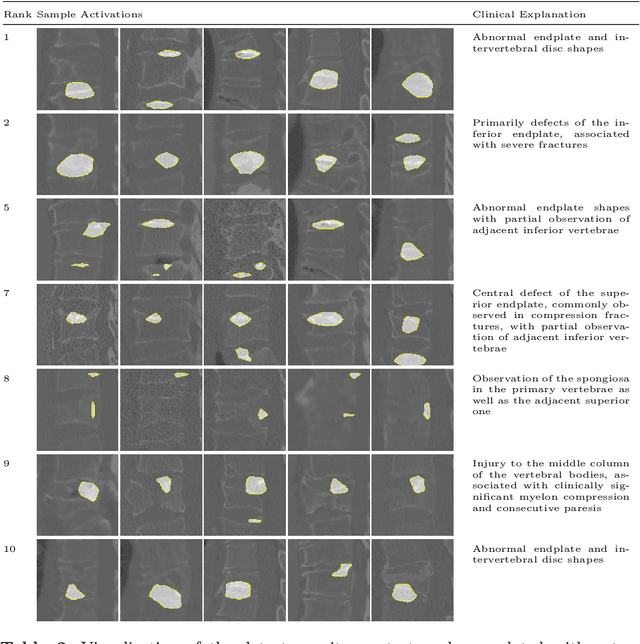
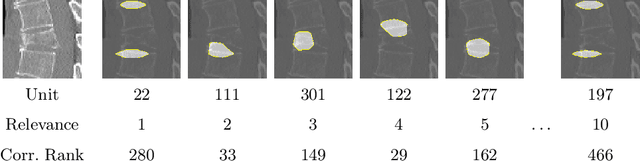
Do black-box neural network models learn clinically relevant features for fracture diagnosis? The answer not only establishes reliability quenches scientific curiosity but also leads to explainable and verbose findings that can assist the radiologists in the final and increase trust. This work identifies the concepts networks use for vertebral fracture diagnosis in CT images. This is achieved by associating concepts to neurons highly correlated with a specific diagnosis in the dataset. The concepts are either associated with neurons by radiologists pre-hoc or are visualized during a specific prediction and left for the user's interpretation. We evaluate which concepts lead to correct diagnosis and which concepts lead to false positives. The proposed frameworks and analysis pave the way for reliable and explainable vertebral fracture diagnosis.
Differentiable Deconvolution for Improved Stroke Perfusion Analysis
Mar 31, 2021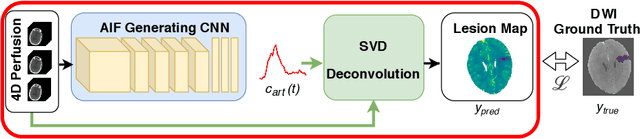

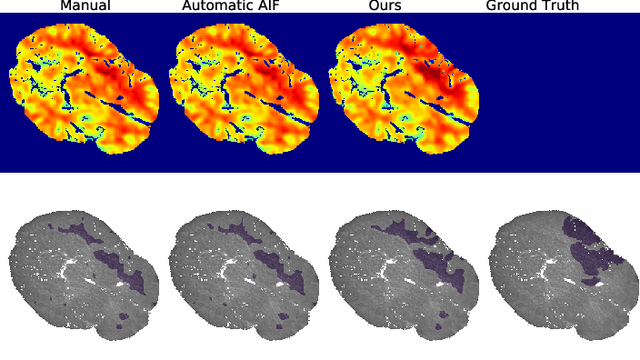
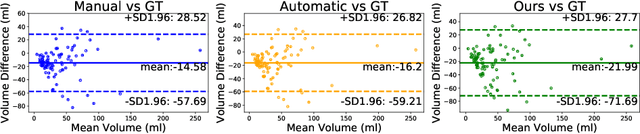
Perfusion imaging is the current gold standard for acute ischemic stroke analysis. It allows quantification of the salvageable and non-salvageable tissue regions (penumbra and core areas respectively). In clinical settings, the singular value decomposition (SVD) deconvolution is one of the most accepted and used approaches for generating interpretable and physically meaningful maps. Though this method has been widely validated in experimental and clinical settings, it might produce suboptimal results because the chosen inputs to the model cannot guarantee optimal performance. For the most critical input, the arterial input function (AIF), it is still controversial how and where it should be chosen even though the method is very sensitive to this input. In this work we propose an AIF selection approach that is optimized for maximal core lesion segmentation performance. The AIF is regressed by a neural network optimized through a differentiable SVD deconvolution, aiming to maximize core lesion segmentation agreement with ground truth data. To our knowledge, this is the first work exploiting a differentiable deconvolution model with neural networks. We show that our approach is able to generate AIFs without any manual annotation, and hence avoiding manual rater's influences. The method achieves manual expert performance in the ISLES18 dataset. We conclude that the methodology opens new possibilities for improving perfusion imaging quantification with deep neural networks.
* Accepted at MICCAI 2020
Patient-specific virtual spine straightening and vertebra inpainting: An automatic framework for osteoplasty planning
Mar 23, 2021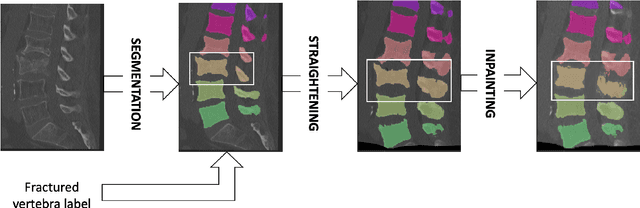
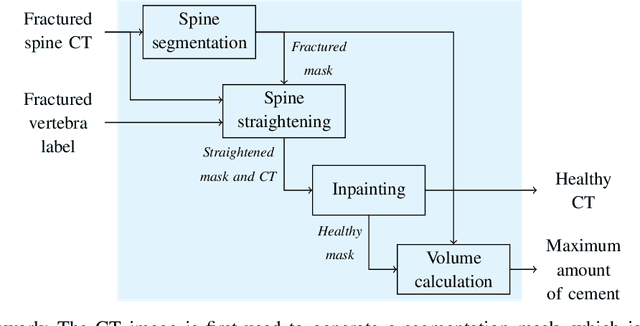
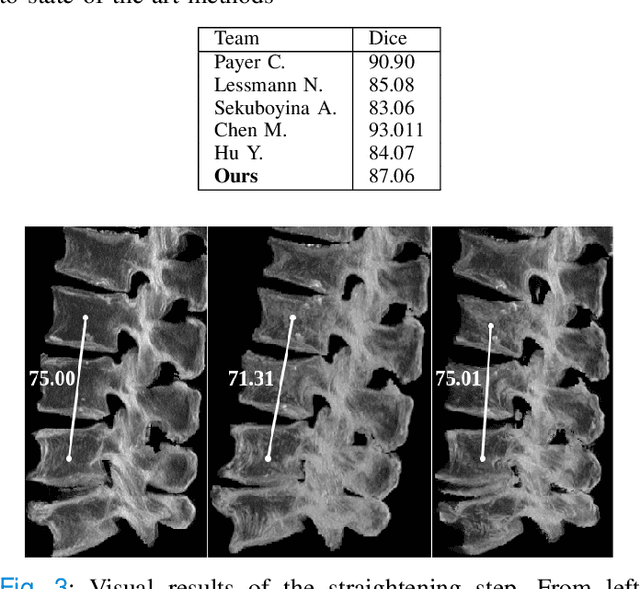
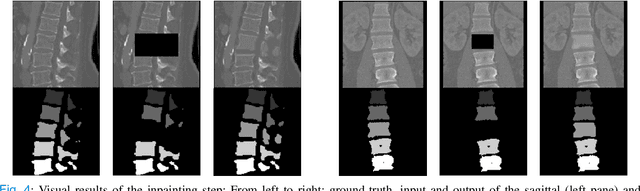
Symptomatic spinal vertebral compression fractures (VCFs) often require osteoplasty treatment. A cement-like material is injected into the bone to stabilize the fracture, restore the vertebral body height and alleviate pain. Leakage is a common complication and may occur due to too much cement being injected. In this work, we propose an automated patient-specific framework that can allow physicians to calculate an upper bound of cement for the injection and estimate the optimal outcome of osteoplasty. The framework uses the patient CT scan and the fractured vertebra label to build a virtual healthy spine using a high-level approach. Firstly, the fractured spine is segmented with a three-step Convolution Neural Network (CNN) architecture. Next, a per-vertebra rigid registration to a healthy spine atlas restores its curvature. Finally, a GAN-based inpainting approach replaces the fractured vertebra with an estimation of its original shape. Based on this outcome, we then estimate the maximum amount of bone cement for injection. We evaluate our framework by comparing the virtual vertebrae volumes of ten patients to their healthy equivalent and report an average error of 3.88$\pm$7.63\%. The presented pipeline offers a first approach to a personalized automatic high-level framework for planning osteoplasty procedures.
A Computed Tomography Vertebral Segmentation Dataset with Anatomical Variations and Multi-Vendor Scanner Data
Mar 10, 2021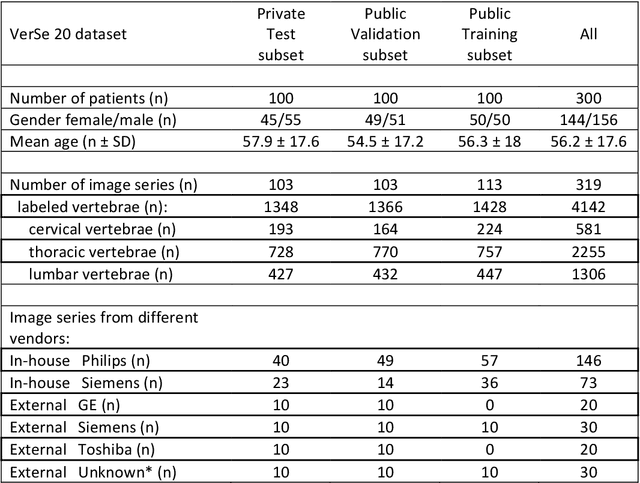
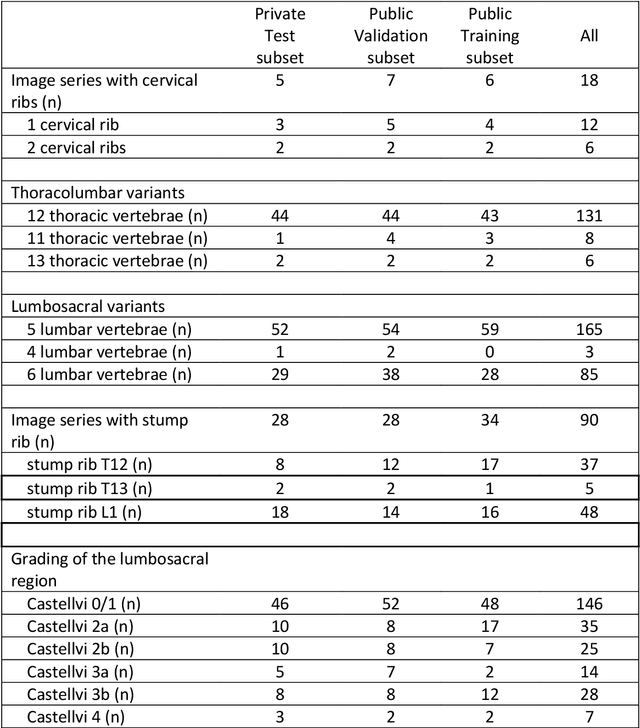
With the advent of deep learning algorithms, fully automated radiological image analysis is within reach. In spine imaging, several atlas- and shape-based as well as deep learning segmentation algorithms have been proposed, allowing for subsequent automated analysis of morphology and pathology. The first Large Scale Vertebrae Segmentation Challenge (VerSe 2019) showed that these perform well on normal anatomy, but fail in variants not frequently present in the training dataset. Building on that experience, we report on the largely increased VerSe 2020 dataset and results from the second iteration of the VerSe challenge (MICCAI 2020, Lima, Peru). VerSe 2020 comprises annotated spine computed tomography (CT) images from 300 subjects with 4142 fully visualized and annotated vertebrae, collected across multiple centres from four different scanner manufacturers, enriched with cases that exhibit anatomical variants such as enumeration abnormalities (n=77) and transitional vertebrae (n=161). Metadata includes vertebral labelling information, voxel-level segmentation masks obtained with a human-machine hybrid algorithm and anatomical ratings, to enable the development and benchmarking of robust and accurate segmentation algorithms.
AIFNet: Automatic Vascular Function Estimation for Perfusion Analysis Using Deep Learning
Oct 04, 2020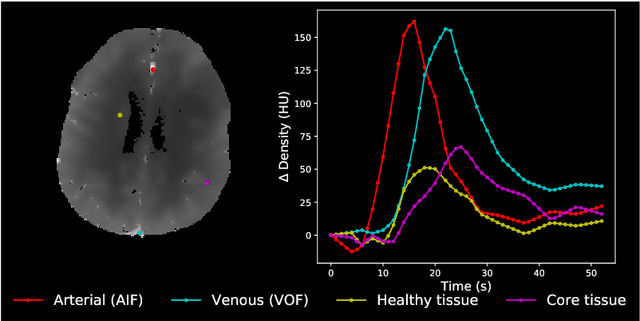

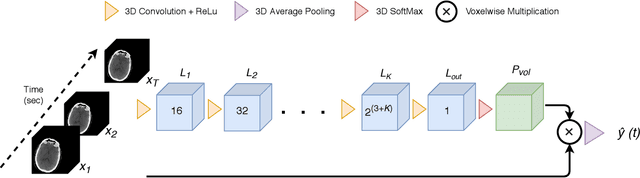
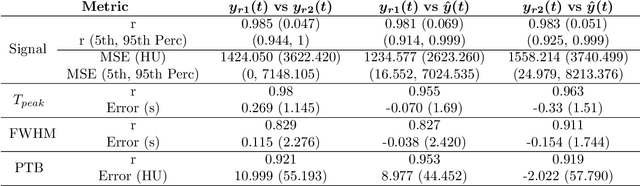
Perfusion imaging is crucial in acute ischemic stroke for quantifying the salvageable penumbra and irreversibly damaged core lesions. As such, it helps clinicians to decide on the optimal reperfusion treatment. In perfusion CT imaging, deconvolution methods are used to obtain clinically interpretable perfusion parameters that allow identifying brain tissue abnormalities. Deconvolution methods require the selection of two reference vascular functions as inputs to the model: the arterial input function (AIF) and the venous output function, with the AIF as the most critical model input. When manually performed, the vascular function selection is time demanding, suffers from poor reproducibility and is subject to the professionals' experience. This leads to potentially unreliable quantification of the penumbra and core lesions and, hence, might harm the treatment decision process. In this work we automatize the perfusion analysis with AIFNet, a fully automatic and end-to-end trainable deep learning approach for estimating the vascular functions. Unlike previous methods using clustering or segmentation techniques to select vascular voxels, AIFNet is directly optimized at the vascular function estimation, which allows to better recognise the time-curve profiles. Validation on the public ISLES18 stroke database shows that AIFNet reaches inter-rater performance for the vascular function estimation and, subsequently, for the parameter maps and core lesion quantification obtained through deconvolution. We conclude that AIFNet has potential for clinical transfer and could be incorporated in perfusion deconvolution software.
Cranial Implant Prediction using Low-Resolution 3D Shape Completion and High-Resolution 2D Refinement
Sep 27, 2020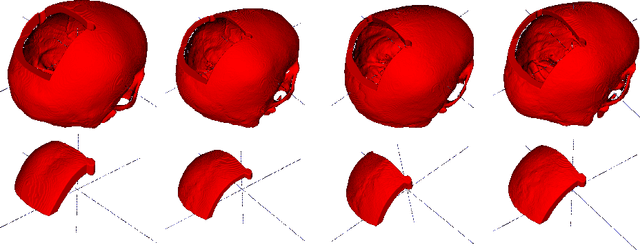
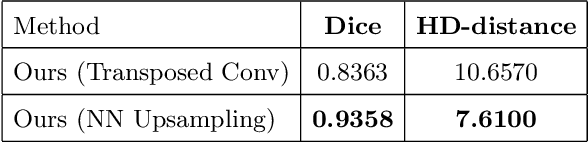
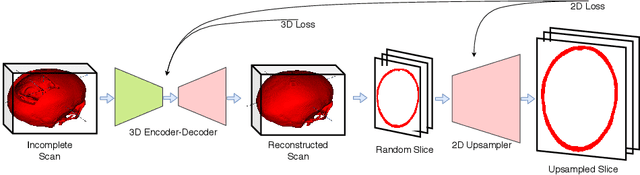
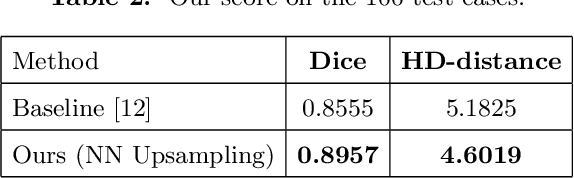
Designing of a cranial implant needs a 3D understanding of the complete skull shape. Thus, taking a 2D approach is sub-optimal, since a 2D model lacks a holistic 3D view of both the defective and healthy skulls. Further, loading the whole 3D skull shapes at its original image resolution is not feasible in commonly available GPUs. To mitigate these issues, we propose a fully convolutional network composed of two subnetworks. The first subnetwork is designed to complete the shape of the downsampled defective skull. The second subnetwork upsamples the reconstructed shape slice-wise. We train the 3D and 2D networks together end-to-end, with a hierarchical loss function. Our proposed solution accurately predicts a high-resolution 3D implant in the challenge test case in terms of dice-score and the Hausdorff distance.
Robustification of Segmentation Models Against Adversarial Perturbations In Medical Imaging
Sep 23, 2020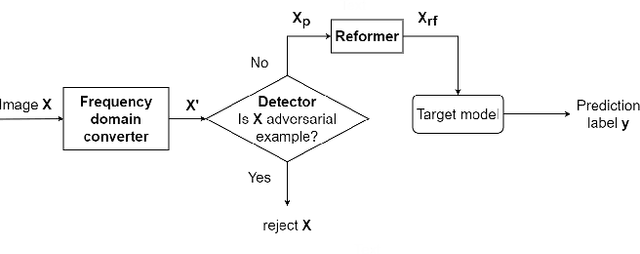
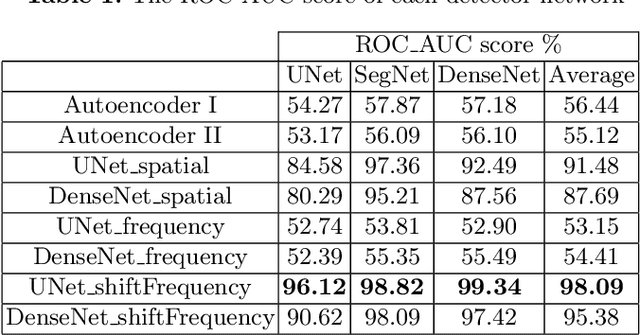
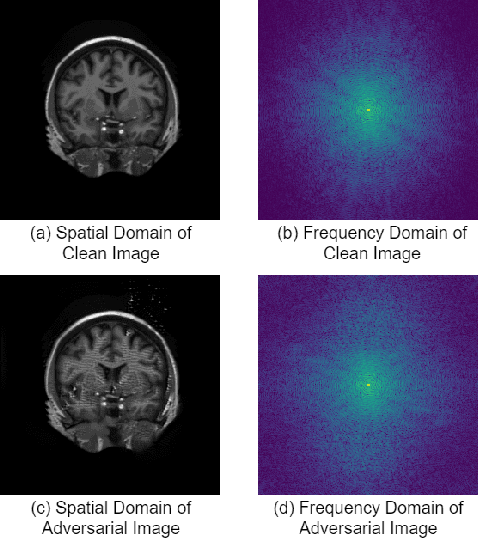

This paper presents a novel yet efficient defense framework for segmentation models against adversarial attacks in medical imaging. In contrary to the defense methods against adversarial attacks for classification models which widely are investigated, such defense methods for segmentation models has been less explored. Our proposed method can be used for any deep learning models without revising the target deep learning models, as well as can be independent of adversarial attacks. Our framework consists of a frequency domain converter, a detector, and a reformer. The frequency domain converter helps the detector detects adversarial examples by using a frame domain of an image. The reformer helps target models to predict more precisely. We have experiments to empirically show that our proposed method has a better performance compared to the existing defense method.
Grading Loss: A Fracture Grade-based Metric Loss for Vertebral Fracture Detection
Aug 18, 2020

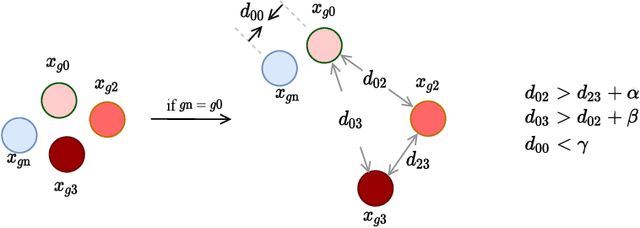
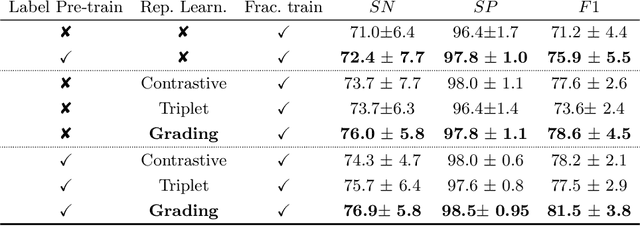
Osteoporotic vertebral fractures have a severe impact on patients' overall well-being but are severely under-diagnosed. These fractures present themselves at various levels of severity measured using the Genant's grading scale. Insufficient annotated datasets, severe data-imbalance, and minor difference in appearances between fractured and healthy vertebrae make naive classification approaches result in poor discriminatory performance. Addressing this, we propose a representation learning-inspired approach for automated vertebral fracture detection, aimed at learning latent representations efficient for fracture detection. Building on state-of-art metric losses, we present a novel Grading Loss for learning representations that respect Genant's fracture grading scheme. On a publicly available spine dataset, the proposed loss function achieves a fracture detection F1 score of 81.5%, a 10% increase over a naive classification baseline.
Inferring the 3D Standing Spine Posture from 2D Radiographs
Jul 13, 2020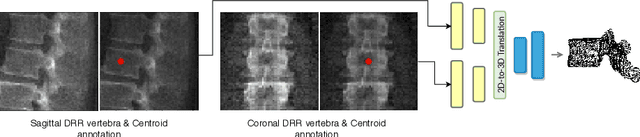
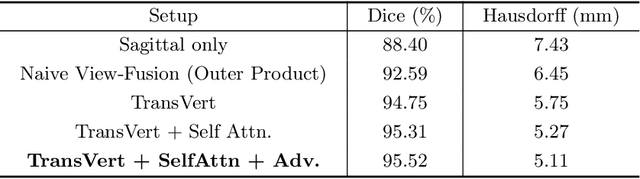
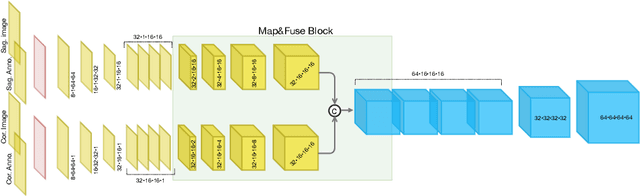

The treatment of degenerative spinal disorders requires an understanding of the individual spinal anatomy and curvature in 3D. An upright spinal pose (i.e. standing) under natural weight bearing is crucial for such bio-mechanical analysis. 3D volumetric imaging modalities (e.g. CT and MRI) are performed in patients lying down. On the other hand, radiographs are captured in an upright pose, but result in 2D projections. This work aims to integrate the two realms, i.e. it combines the upright spinal curvature from radiographs with the 3D vertebral shape from CT imaging for synthesizing an upright 3D model of spine, loaded naturally. Specifically, we propose a novel neural network architecture working vertebra-wise, termed \emph{TransVert}, which takes orthogonal 2D radiographs and infers the spine's 3D posture. We validate our architecture on digitally reconstructed radiographs, achieving a 3D reconstruction Dice of $95.52\%$, indicating an almost perfect 2D-to-3D domain translation. Deploying our model on clinical radiographs, we successfully synthesise full-3D, upright, patient-specific spine models for the first time.