 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrading Loss: A Fracture Grade-based Metric Loss for Vertebral Fracture Detection
Aug 18, 2020

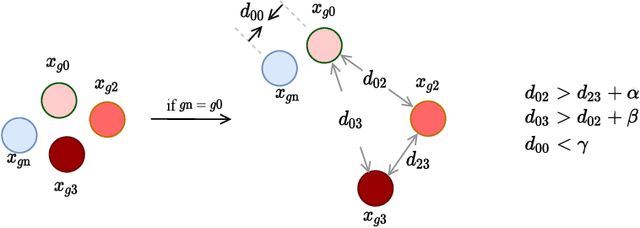
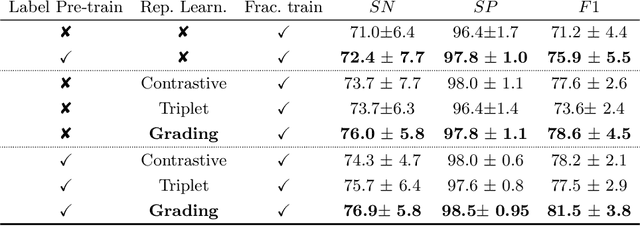
Osteoporotic vertebral fractures have a severe impact on patients' overall well-being but are severely under-diagnosed. These fractures present themselves at various levels of severity measured using the Genant's grading scale. Insufficient annotated datasets, severe data-imbalance, and minor difference in appearances between fractured and healthy vertebrae make naive classification approaches result in poor discriminatory performance. Addressing this, we propose a representation learning-inspired approach for automated vertebral fracture detection, aimed at learning latent representations efficient for fracture detection. Building on state-of-art metric losses, we present a novel Grading Loss for learning representations that respect Genant's fracture grading scheme. On a publicly available spine dataset, the proposed loss function achieves a fracture detection F1 score of 81.5%, a 10% increase over a naive classification baseline.
Probabilistic Point Cloud Reconstructions for Vertebral Shape Analysis
Aug 02, 2019

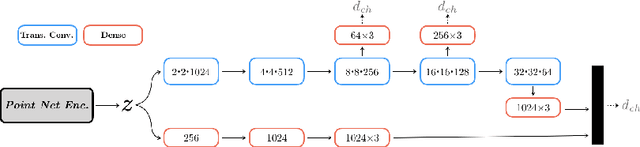
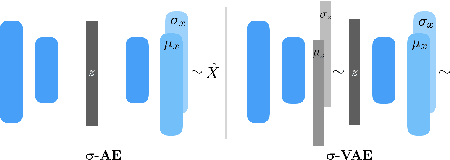
We propose an auto-encoding network architecture for point clouds (PC) capable of extracting shape signatures without supervision. Building on this, we (i) design a loss function capable of modelling data variance on PCs which are unstructured, and (ii) regularise the latent space as in a variational auto-encoder, both of which increase the auto-encoders' descriptive capacity while making them probabilistic. Evaluating the reconstruction quality of our architectures, we employ them for detecting vertebral fractures without any supervision. By learning to efficiently reconstruct only healthy vertebrae, fractures are detected as anomalous reconstructions. Evaluating on a dataset containing $\sim$1500 vertebrae, we achieve area-under-ROC curve of $>$75%, without using intensity-based features.