 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Kinodynamic Planning on the Constraint Manifold with Deep Neural Networks
Jan 12, 2023



Motion planning is a mature area of research in robotics with many well-established methods based on optimization or sampling the state space, suitable for solving kinematic motion planning. However, when dynamic motions under constraints are needed and computation time is limited, fast kinodynamic planning on the constraint manifold is indispensable. In recent years, learning-based solutions have become alternatives to classical approaches, but they still lack comprehensive handling of complex constraints, such as planning on a lower-dimensional manifold of the task space while considering the robot's dynamics. This paper introduces a novel learning-to-plan framework that exploits the concept of constraint manifold, including dynamics, and neural planning methods. Our approach generates plans satisfying an arbitrary set of constraints and computes them in a short constant time, namely the inference time of a neural network. This allows the robot to plan and replan reactively, making our approach suitable for dynamic environments. We validate our approach on two simulated tasks and in a demanding real-world scenario, where we use a Kuka LBR Iiwa 14 robotic arm to perform the hitting movement in robotic Air Hockey.
Learning-based Design and Control for Quadrupedal Robots with Parallel-Elastic Actuators
Jan 09, 2023



Parallel-elastic joints can improve the efficiency and strength of robots by assisting the actuators with additional torques. For these benefits to be realized, a spring needs to be carefully designed. However, designing robots is an iterative and tedious process, often relying on intuition and heuristics. We introduce a design optimization framework that allows us to co-optimize a parallel elastic knee joint and locomotion controller for quadrupedal robots with minimal human intuition. We design a parallel elastic joint and optimize its parameters with respect to the efficiency in a model-free fashion. In the first step, we train a design-conditioned policy using model-free Reinforcement Learning, capable of controlling the quadruped in the predefined range of design parameters. Afterwards, we use Bayesian Optimization to find the best design using the policy. We use this framework to optimize the parallel-elastic spring parameters for the knee of our quadrupedal robot ANYmal together with the optimal controller. We evaluate the optimized design and controller in real-world experiments over various terrains. Our results show that the new system improves the torque-square efficiency of the robot by 33% compared to the baseline and reduces maximum joint torque by 30% without compromising tracking performance. The improved design resulted in 11% longer operation time on flat terrain.
Visual Tactile Sensor Based Force Estimation for Position-Force Teleoperation
Dec 26, 2022Vision-based tactile sensors have gained extensive attention in the robotics community. The sensors are highly expected to be capable of extracting contact information i.e. haptic information during in-hand manipulation. This nature of tactile sensors makes them a perfect match for haptic feedback applications. In this paper, we propose a contact force estimation method using the vision-based tactile sensor DIGIT, and apply it to a position-force teleoperation architecture for force feedback. The force estimation is done by building a depth map for DIGIT gel surface deformation measurement and applying a regression algorithm on estimated depth data and ground truth force data to get the depth-force relationship. The experiment is performed by constructing a grasping force feedback system with a haptic device as a leader robot and a parallel robot gripper as a follower robot, where the DIGIT sensor is attached to the tip of the robot gripper to estimate the contact force. The preliminary results show the capability of using the low-cost vision-based sensor for force feedback applications.
Information-Theoretic Safe Exploration with Gaussian Processes
Dec 09, 2022



We consider a sequential decision making task where we are not allowed to evaluate parameters that violate an a priori unknown (safety) constraint. A common approach is to place a Gaussian process prior on the unknown constraint and allow evaluations only in regions that are safe with high probability. Most current methods rely on a discretization of the domain and cannot be directly extended to the continuous case. Moreover, the way in which they exploit regularity assumptions about the constraint introduces an additional critical hyperparameter. In this paper, we propose an information-theoretic safe exploration criterion that directly exploits the GP posterior to identify the most informative safe parameters to evaluate. Our approach is naturally applicable to continuous domains and does not require additional hyperparameters. We theoretically analyze the method and show that we do not violate the safety constraint with high probability and that we explore by learning about the constraint up to arbitrary precision. Empirical evaluations demonstrate improved data-efficiency and scalability.
Hierarchical Policy Blending As Optimal Transport
Dec 04, 2022We present hierarchical policy blending as optimal transport (HiPBOT). This hierarchical framework adapts the weights of low-level reactive expert policies, adding a look-ahead planning layer on the parameter space of a product of expert policies and agents. Our high-level planner realizes a policy blending via unbalanced optimal transport, consolidating the scaling of underlying Riemannian motion policies, effectively adjusting their Riemannian matrix, and deciding over the priorities between experts and agents, guaranteeing safety and task success. Our experimental results in a range of application scenarios from low-dimensional navigation to high-dimensional whole-body control showcase the efficacy and efficiency of HiPBOT, which outperforms state-of-the-art baselines that either perform probabilistic inference or define a tree structure of experts, paving the way for new applications of optimal transport to robot control. More material at https://sites.google.com/view/hipobot
PAC-Bayes Bounds for Bandit Problems: A Survey and Experimental Comparison
Nov 29, 2022



PAC-Bayes has recently re-emerged as an effective theory with which one can derive principled learning algorithms with tight performance guarantees. However, applications of PAC-Bayes to bandit problems are relatively rare, which is a great misfortune. Many decision-making problems in healthcare, finance and natural sciences can be modelled as bandit problems. In many of these applications, principled algorithms with strong performance guarantees would be very much appreciated. This survey provides an overview of PAC-Bayes performance bounds for bandit problems and an experimental comparison of these bounds. Our experimental comparison has revealed that available PAC-Bayes upper bounds on the cumulative regret are loose, whereas available PAC-Bayes lower bounds on the expected reward can be surprisingly tight. We found that an offline contextual bandit algorithm that learns a policy by optimising a PAC-Bayes bound was able to learn randomised neural network polices with competitive expected reward and non-vacuous performance guarantees.
How Crucial is Transformer in Decision Transformer?
Nov 26, 2022



Decision Transformer (DT) is a recently proposed architecture for Reinforcement Learning that frames the decision-making process as an auto-regressive sequence modeling problem and uses a Transformer model to predict the next action in a sequence of states, actions, and rewards. In this paper, we analyze how crucial the Transformer model is in the complete DT architecture on continuous control tasks. Namely, we replace the Transformer by an LSTM model while keeping the other parts unchanged to obtain what we call a Decision LSTM model. We compare it to DT on continuous control tasks, including pendulum swing-up and stabilization, in simulation and on physical hardware. Our experiments show that DT struggles with continuous control problems, such as inverted pendulum and Furuta pendulum stabilization. On the other hand, the proposed Decision LSTM is able to achieve expert-level performance on these tasks, in addition to learning a swing-up controller on the real system. These results suggest that the strength of the Decision Transformer for continuous control tasks may lie in the overall sequential modeling architecture and not in the Transformer per se.
Variational Hierarchical Mixtures for Learning Probabilistic Inverse Dynamics
Nov 02, 2022Well-calibrated probabilistic regression models are a crucial learning component in robotics applications as datasets grow rapidly and tasks become more complex. Classical regression models are usually either probabilistic kernel machines with a flexible structure that does not scale gracefully with data or deterministic and vastly scalable automata, albeit with a restrictive parametric form and poor regularization. In this paper, we consider a probabilistic hierarchical modeling paradigm that combines the benefits of both worlds to deliver computationally efficient representations with inherent complexity regularization. The presented approaches are probabilistic interpretations of local regression techniques that approximate nonlinear functions through a set of local linear or polynomial units. Importantly, we rely on principles from Bayesian nonparametrics to formulate flexible models that adapt their complexity to the data and can potentially encompass an infinite number of components. We derive two efficient variational inference techniques to learn these representations and highlight the advantages of hierarchical infinite local regression models, such as dealing with non-smooth functions, mitigating catastrophic forgetting, and enabling parameter sharing and fast predictions. Finally, we validate this approach on a set of large inverse dynamics datasets and test the learned models in real-world control scenarios.
Active Exploration for Robotic Manipulation
Oct 23, 2022Robotic manipulation stands as a largely unsolved problem despite significant advances in robotics and machine learning in recent years. One of the key challenges in manipulation is the exploration of the dynamics of the environment when there is continuous contact between the objects being manipulated. This paper proposes a model-based active exploration approach that enables efficient learning in sparse-reward robotic manipulation tasks. The proposed method estimates an information gain objective using an ensemble of probabilistic models and deploys model predictive control (MPC) to plan actions online that maximize the expected reward while also performing directed exploration. We evaluate our proposed algorithm in simulation and on a real robot, trained from scratch with our method, on a challenging ball pushing task on tilted tables, where the target ball position is not known to the agent a-priori. Our real-world robot experiment serves as a fundamental application of active exploration in model-based reinforcement learning of complex robotic manipulation tasks.
Hierarchical Policy Blending as Inference for Reactive Robot Control
Oct 14, 2022
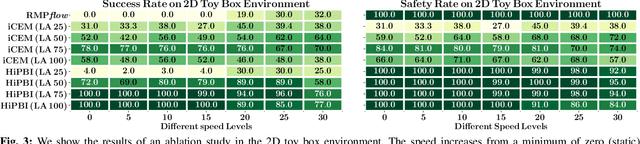
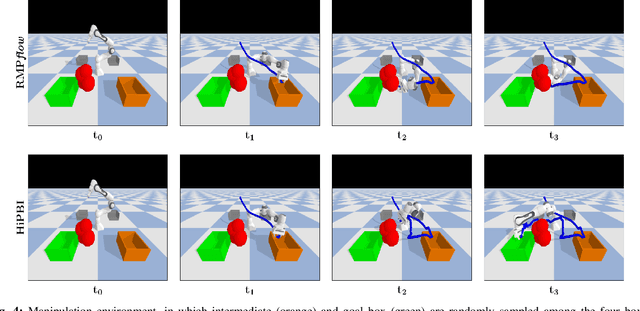
Motion generation in cluttered, dense, and dynamic environments is a central topic in robotics, rendered as a multi-objective decision-making problem. Current approaches trade-off between safety and performance. On the one hand, reactive policies guarantee fast response to environmental changes at the risk of suboptimal behavior. On the other hand, planning-based motion generation provides feasible trajectories, but the high computational cost may limit the control frequency and thus safety. To combine the benefits of reactive policies and planning, we propose a hierarchical motion generation method. Moreover, we adopt probabilistic inference methods to formalize the hierarchical model and stochastic optimization. We realize this approach as a weighted product of stochastic, reactive expert policies, where planning is used to adaptively compute the optimal weights over the task horizon. This stochastic optimization avoids local optima and proposes feasible reactive plans that find paths in cluttered and dense environments. Our extensive experimental study in planar navigation and 6DoF manipulation shows that our proposed hierarchical motion generation method outperforms both myopic reactive controllers and online re-planning methods.