 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Jun 16, 2020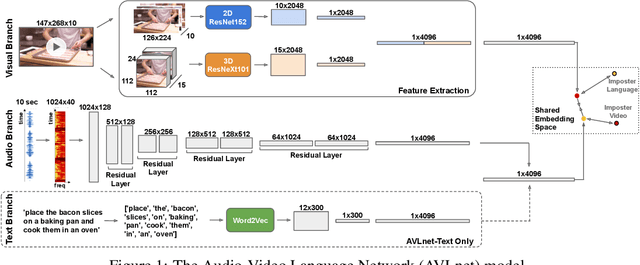
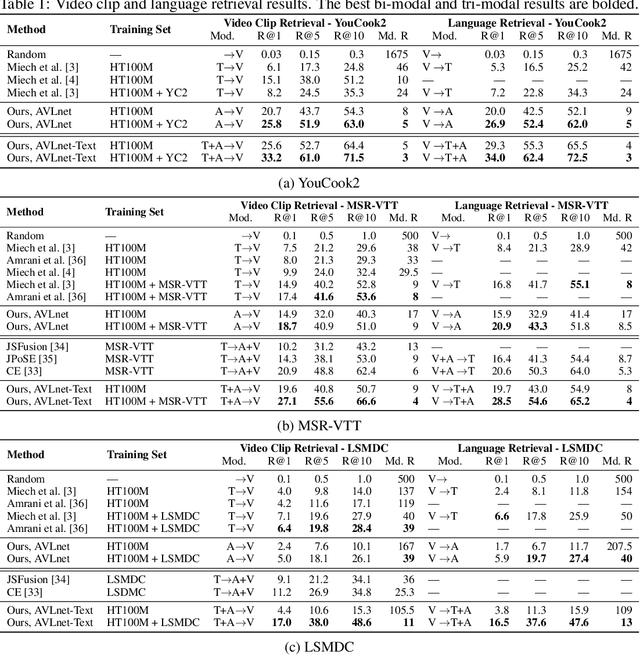
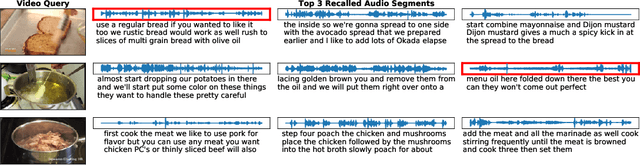
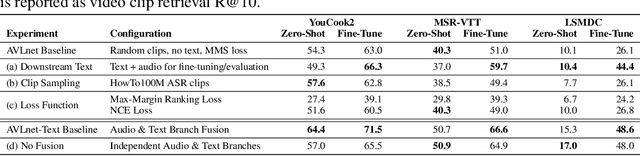
Current methods for learning visually grounded language from videos often rely on time-consuming and expensive data collection, such as human annotated textual summaries or machine generated automatic speech recognition transcripts. In this work, we introduce Audio-Video Language Network (AVLnet), a self-supervised network that learns a shared audio-visual embedding space directly from raw video inputs. We circumvent the need for annotation and instead learn audio-visual language representations directly from randomly segmented video clips and their raw audio waveforms. We train AVLnet on publicly available instructional videos and evaluate our model on video clip and language retrieval tasks on three video datasets. Our proposed model outperforms several state-of-the-art text-video baselines by up to 11.8% in a video clip retrieval task, despite operating on the raw audio instead of manually annotated text captions. Further, we show AVLnet is capable of integrating textual information, increasing its modularity and improving performance by up to 20.3% on the video clip retrieval task. Finally, we perform analysis of AVLnet's learned representations, showing our model has learned to relate visual objects with salient words and natural sounds.
CSTNet: Contrastive Speech Translation Network for Self-Supervised Speech Representation Learning
Jun 04, 2020
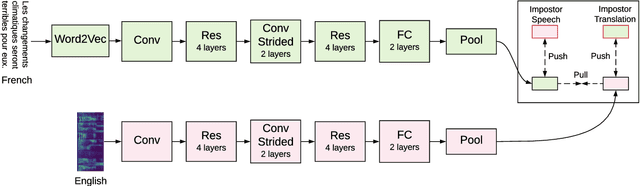
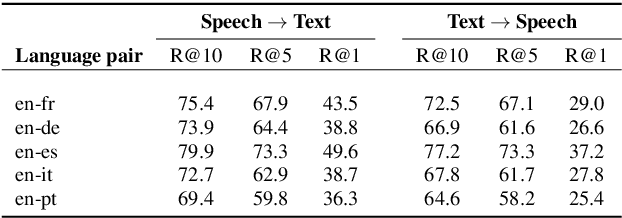
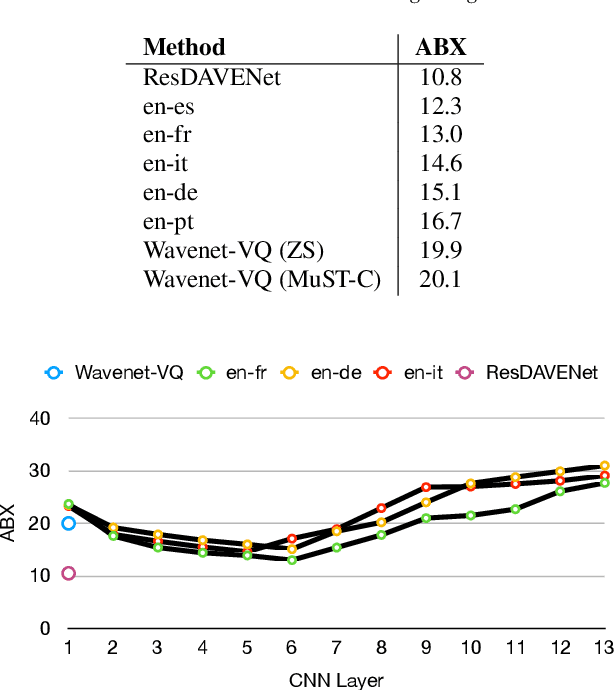
More than half of the 7,000 languages in the world are in imminent danger of going extinct. Traditional methods of documenting language proceed by collecting audio data followed by manual annotation by trained linguists at different levels of granularity. This time consuming and painstaking process could benefit from machine learning. Many endangered languages do not have any orthographic form but usually have speakers that are bi-lingual and trained in a high resource language. It is relatively easy to obtain textual translations corresponding to speech. In this work, we provide a multimodal machine learning framework for speech representation learning by exploiting the correlations between the two modalities namely speech and its corresponding text translation. Here, we construct a convolutional neural network audio encoder capable of extracting linguistic representations from speech. The audio encoder is trained to perform a speech-translation retrieval task in a contrastive learning framework. By evaluating the learned representations on a phone recognition task, we demonstrate that linguistic representations emerge in the audio encoder's internal representations as a by-product of learning to perform the retrieval task.
A Convolutional Deep Markov Model for Unsupervised Speech Representation Learning
Jun 03, 2020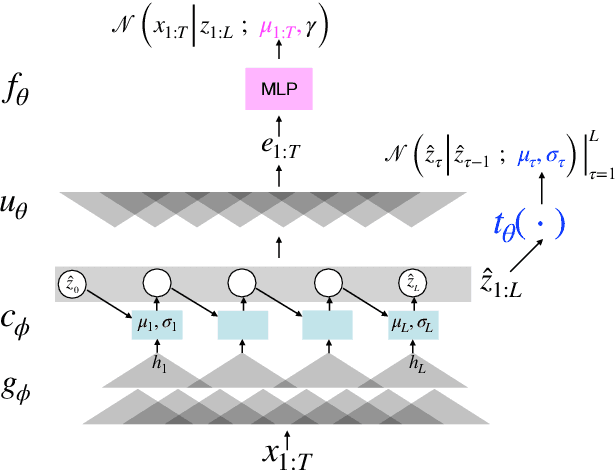
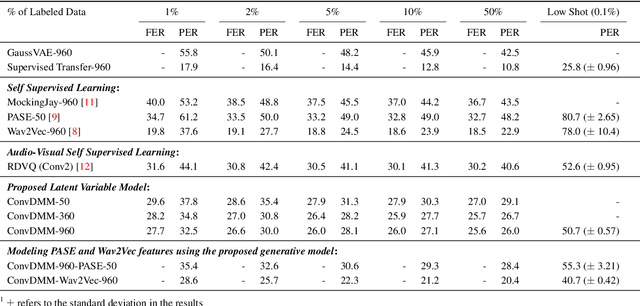
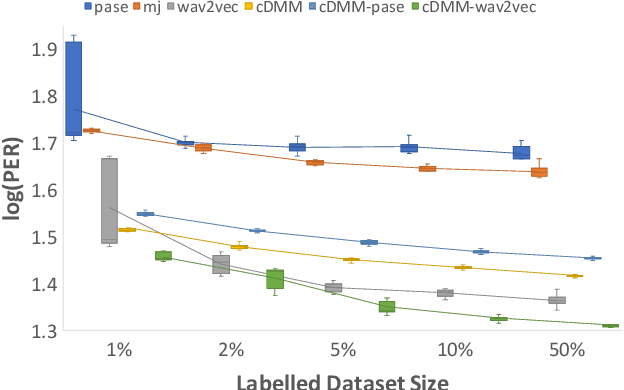
Probabilistic Latent Variable Models (LVMs) provide an alternative to self-supervised learning approaches for linguistic representation learning from speech. LVMs admit an intuitive probabilistic interpretation where the latent structure shapes the information extracted from the signal. Even though LVMs have recently seen a renewed interest due to the introduction of Variational Autoencoders (VAEs), their use for speech representation learning remains largely unexplored. In this work, we propose Convolutional Deep Markov Model (ConvDMM), a Gaussian state-space model with non-linear emission and transition functions modelled by deep neural networks. This unsupervised model is trained using black box variational inference. A deep convolutional neural network is used as an inference network for structured variational approximation. When trained on a large scale speech dataset (LibriSpeech), ConvDMM produces features that significantly outperform multiple self-supervised feature extracting methods on linear phone classification and recognition on the Wall Street Journal dataset. Furthermore, we found that ConvDMM complements self-supervised methods like Wav2Vec and PASE, improving on the results achieved with any of the methods alone. Lastly, we find that ConvDMM features enable learning better phone recognizers than any other features in an extreme low-resource regime with few labeled training examples.
Prototypical Q Networks for Automatic Conversational Diagnosis and Few-Shot New Disease Adaption
May 19, 2020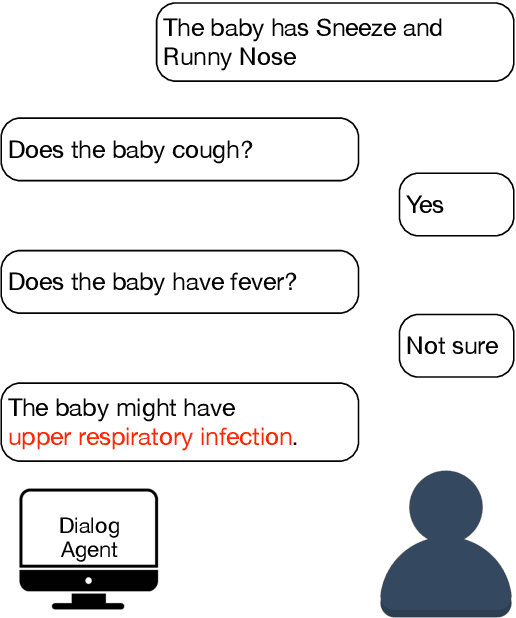


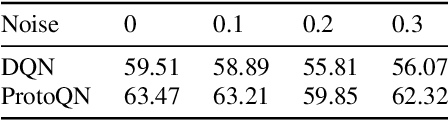
Spoken dialog systems have seen applications in many domains, including medical for automatic conversational diagnosis. State-of-the-art dialog managers are usually driven by deep reinforcement learning models, such as deep Q networks (DQNs), which learn by interacting with a simulator to explore the entire action space since real conversations are limited. However, the DQN-based automatic diagnosis models do not achieve satisfying performances when adapted to new, unseen diseases with only a few training samples. In this work, we propose the Prototypical Q Networks (ProtoQN) as the dialog manager for the automatic diagnosis systems. The model calculates prototype embeddings with real conversations between doctors and patients, learning from them and simulator-augmented dialogs more efficiently. We create both supervised and few-shot learning tasks with the Muzhi corpus. Experiments showed that the ProtoQN significantly outperformed the baseline DQN model in both supervised and few-shot learning scenarios, and achieves state-of-the-art few-shot learning performances.
Vector-Quantized Autoregressive Predictive Coding
May 17, 2020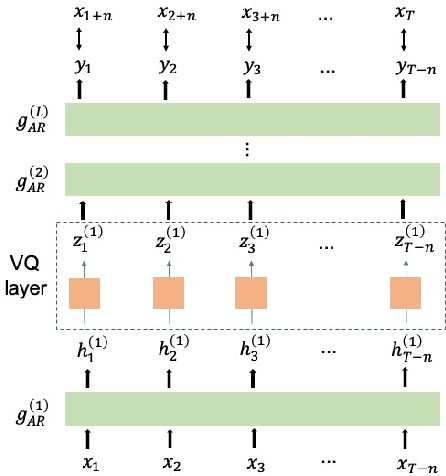
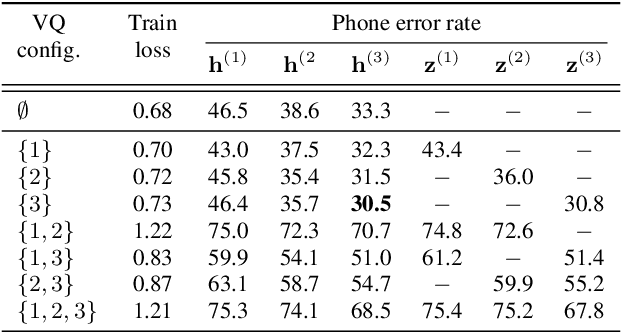
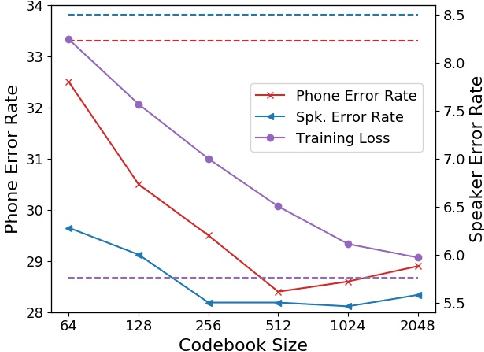
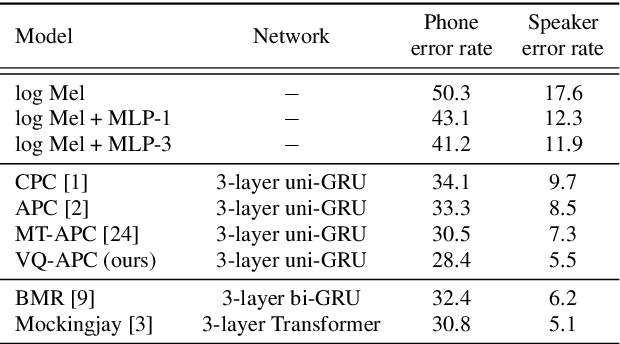
Autoregressive Predictive Coding (APC), as a self-supervised objective, has enjoyed success in learning representations from large amounts of unlabeled data, and the learned representations are rich for many downstream tasks. However, the connection between low self-supervised loss and strong performance in downstream tasks remains unclear. In this work, we propose Vector-Quantized Autoregressive Predictive Coding (VQ-APC), a novel model that produces quantized representations, allowing us to explicitly control the amount of information encoded in the representations. By studying a sequence of increasingly limited models, we reveal the constituents of the learned representations. In particular, we confirm the presence of information with probing tasks, while showing the absence of information with mutual information, uncovering the model's preference in preserving speech information as its capacity becomes constrained. We find that there exists a point where phonetic and speaker information are amplified to maximize a self-supervised objective. As a byproduct, the learned codes for a particular model capacity correspond well to English phones.
What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context
May 09, 2020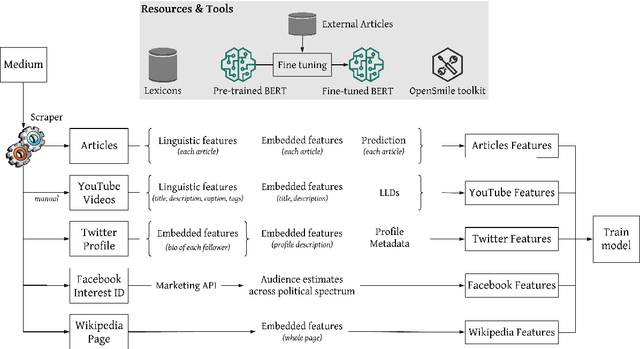
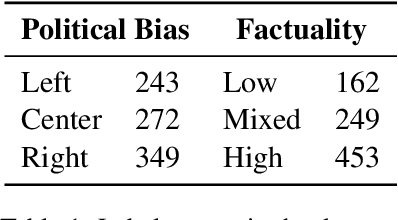
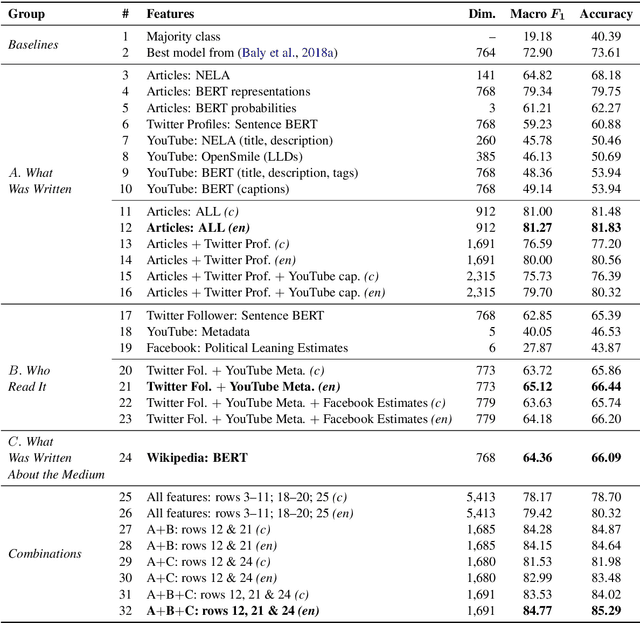
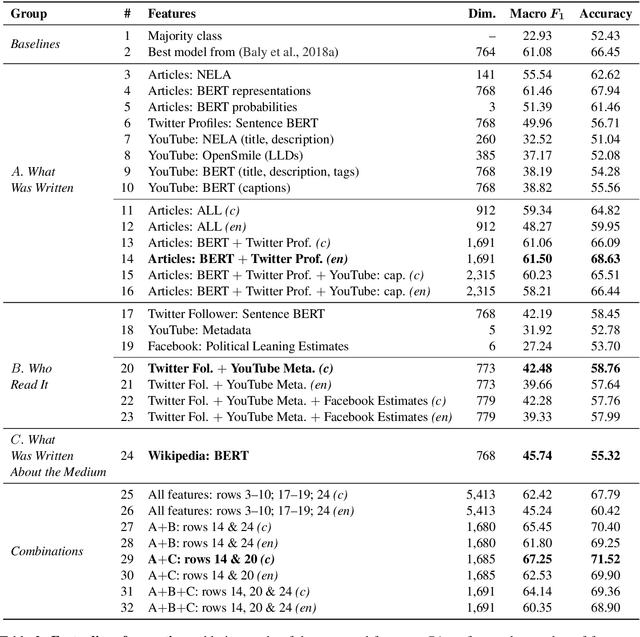
Predicting the political bias and the factuality of reporting of entire news outlets are critical elements of media profiling, which is an understudied but an increasingly important research direction. The present level of proliferation of fake, biased, and propagandistic content online, has made it impossible to fact-check every single suspicious claim, either manually or automatically. Alternatively, we can profile entire news outlets and look for those that are likely to publish fake or biased content. This approach makes it possible to detect likely "fake news" the moment they are published, by simply checking the reliability of their source. From a practical perspective, political bias and factuality of reporting have a linguistic aspect but also a social context. Here, we study the impact of both, namely (i) what was written (i.e., what was published by the target medium, and how it describes itself on Twitter) vs. (ii) who read it (i.e., analyzing the readers of the target medium on Facebook, Twitter, and YouTube). We further study (iii) what was written about the target medium on Wikipedia. The evaluation results show that what was written matters most, and that putting all information sources together yields huge improvements over the current state-of-the-art.
* Factuality of reporting, fact-checking, political ideology, media bias, disinformation, propaganda, social media, news media
Similarity Analysis of Contextual Word Representation Models
May 03, 2020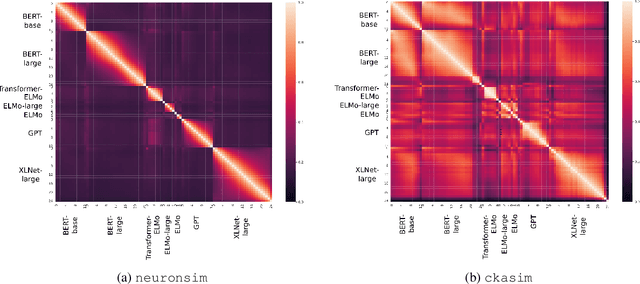
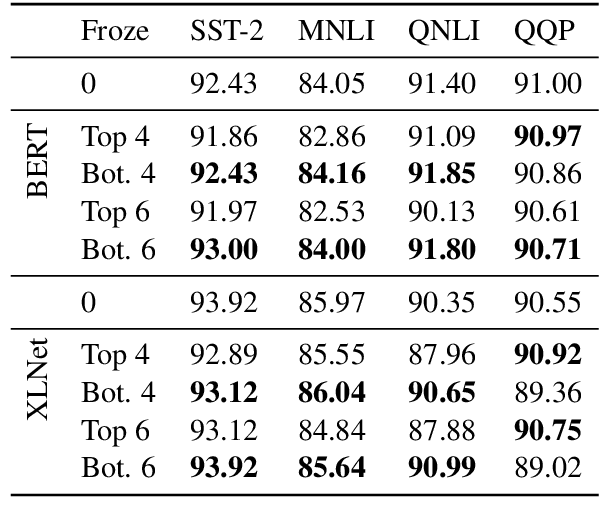
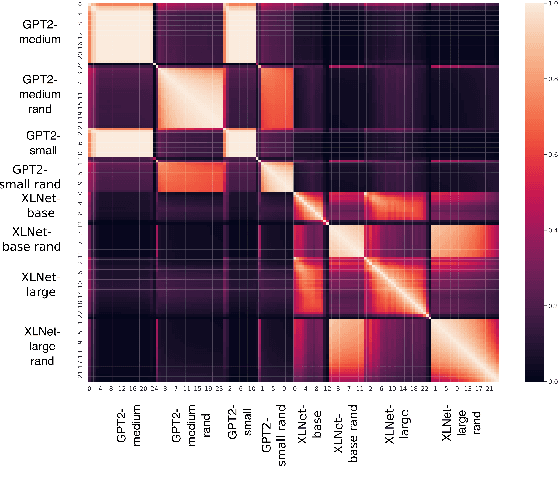
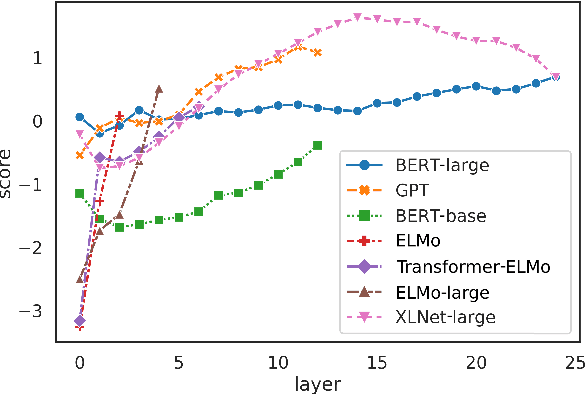
This paper investigates contextual word representation models from the lens of similarity analysis. Given a collection of trained models, we measure the similarity of their internal representations and attention. Critically, these models come from vastly different architectures. We use existing and novel similarity measures that aim to gauge the level of localization of information in the deep models, and facilitate the investigation of which design factors affect model similarity, without requiring any external linguistic annotation. The analysis reveals that models within the same family are more similar to one another, as may be expected. Surprisingly, different architectures have rather similar representations, but different individual neurons. We also observed differences in information localization in lower and higher layers and found that higher layers are more affected by fine-tuning on downstream tasks.
Improved Speech Representations with Multi-Target Autoregressive Predictive Coding
Apr 11, 2020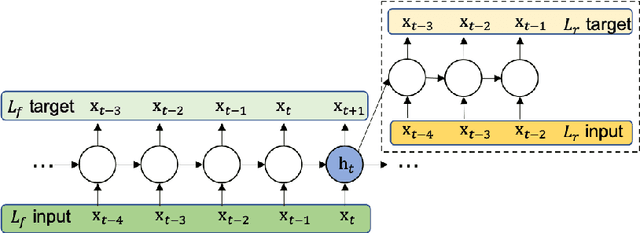
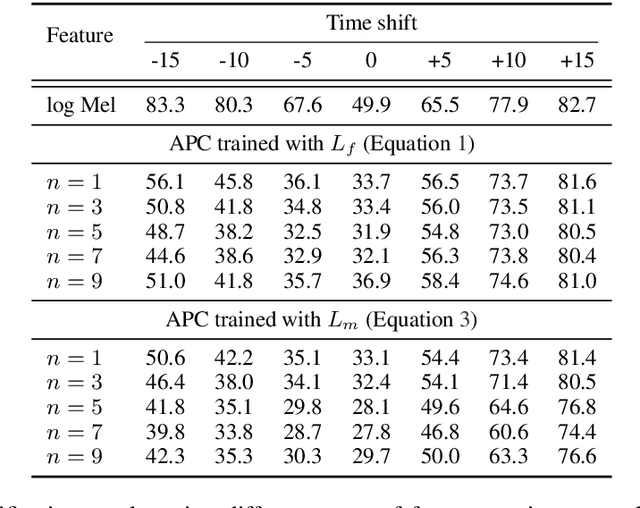
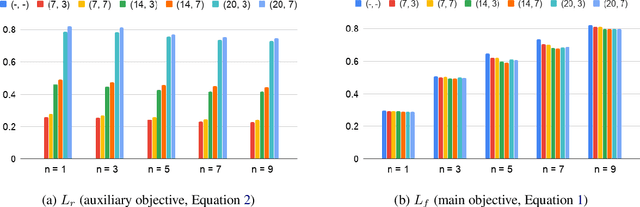

Training objectives based on predictive coding have recently been shown to be very effective at learning meaningful representations from unlabeled speech. One example is Autoregressive Predictive Coding (Chung et al., 2019), which trains an autoregressive RNN to generate an unseen future frame given a context such as recent past frames. The basic hypothesis of these approaches is that hidden states that can accurately predict future frames are a useful representation for many downstream tasks. In this paper we extend this hypothesis and aim to enrich the information encoded in the hidden states by training the model to make more accurate future predictions. We propose an auxiliary objective that serves as a regularization to improve generalization of the future frame prediction task. Experimental results on phonetic classification, speech recognition, and speech translation not only support the hypothesis, but also demonstrate the effectiveness of our approach in learning representations that contain richer phonetic content.
SemEval-2016 Task 3: Community Question Answering
Dec 03, 2019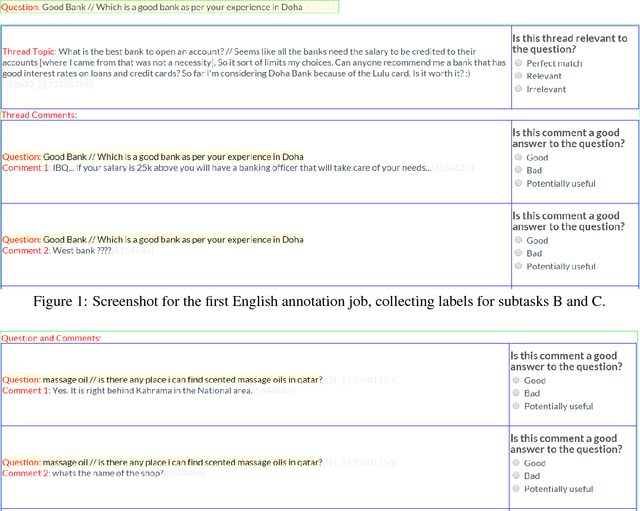
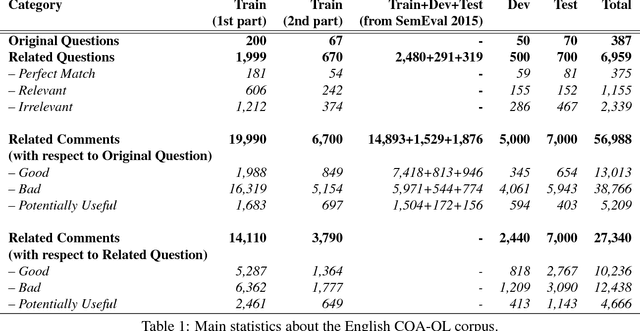
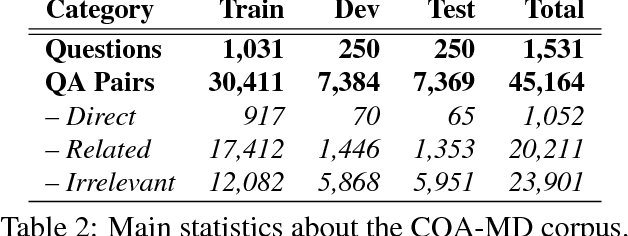
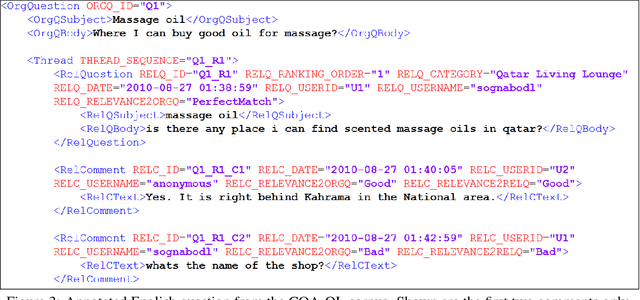
This paper describes the SemEval--2016 Task 3 on Community Question Answering, which we offered in English and Arabic. For English, we had three subtasks: Question--Comment Similarity (subtask A), Question--Question Similarity (B), and Question--External Comment Similarity (C). For Arabic, we had another subtask: Rerank the correct answers for a new question (D). Eighteen teams participated in the task, submitting a total of 95 runs (38 primary and 57 contrastive) for the four subtasks. A variety of approaches and features were used by the participating systems to address the different subtasks, which are summarized in this paper. The best systems achieved an official score (MAP) of 79.19, 76.70, 55.41, and 45.83 in subtasks A, B, C, and D, respectively. These scores are significantly better than those for the baselines that we provided. For subtask A, the best system improved over the 2015 winner by 3 points absolute in terms of Accuracy.
* community question answering, question-question similarity, question-comment similarity, answer reranking, English, Arabic. arXiv admin note: substantial text overlap with arXiv:1912.00730
SemEval-2015 Task 3: Answer Selection in Community Question Answering
Nov 26, 2019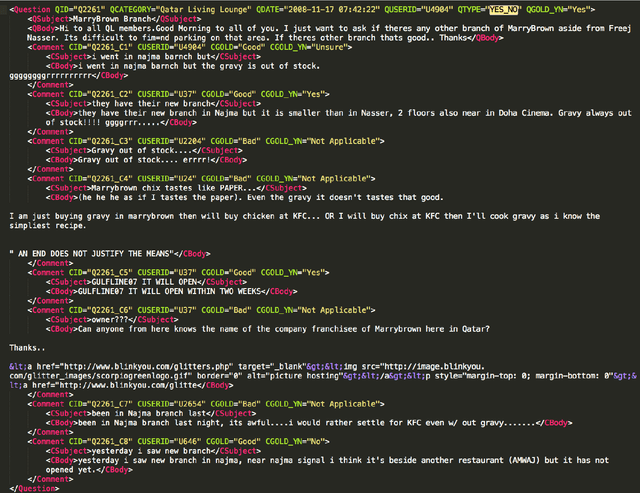
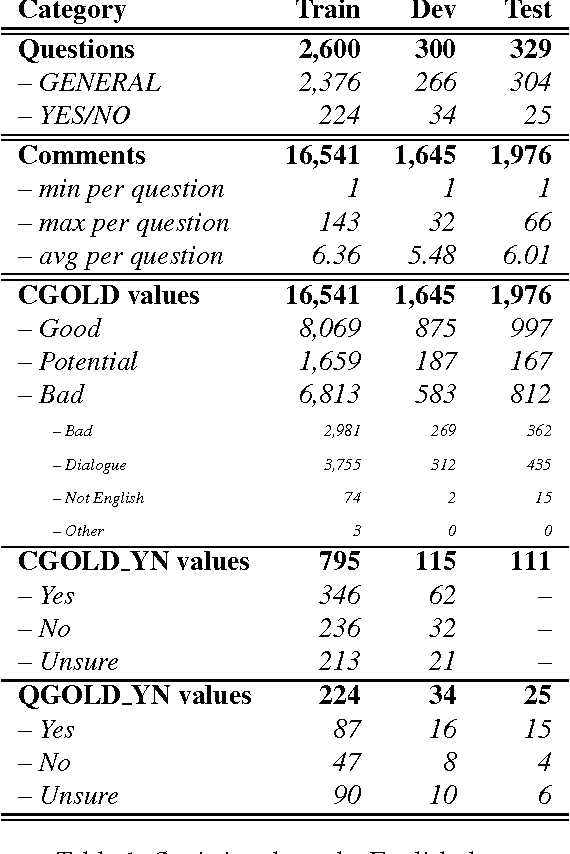
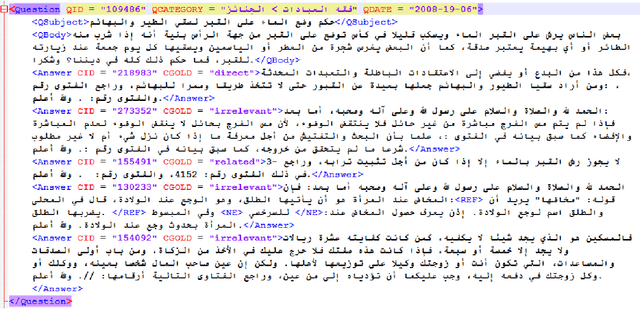
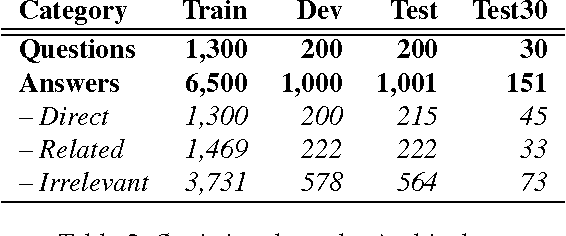
Community Question Answering (cQA) provides new interesting research directions to the traditional Question Answering (QA) field, e.g., the exploitation of the interaction between users and the structure of related posts. In this context, we organized SemEval-2015 Task 3 on "Answer Selection in cQA", which included two subtasks: (a) classifying answers as "good", "bad", or "potentially relevant" with respect to the question, and (b) answering a YES/NO question with "yes", "no", or "unsure", based on the list of all answers. We set subtask A for Arabic and English on two relatively different cQA domains, i.e., the Qatar Living website for English, and a Quran-related website for Arabic. We used crowdsourcing on Amazon Mechanical Turk to label a large English training dataset, which we released to the research community. Thirteen teams participated in the challenge with a total of 61 submissions: 24 primary and 37 contrastive. The best systems achieved an official score (macro-averaged F1) of 57.19 and 63.7 for the English subtasks A and B, and 78.55 for the Arabic subtask A.
* community question answering, answer selection, English, Arabic