 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Graph Representation Learning by Contrastive Regularization
Jan 27, 2021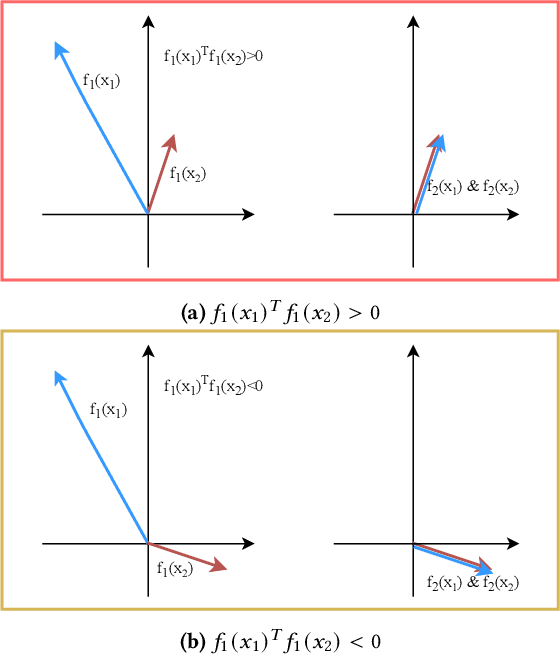
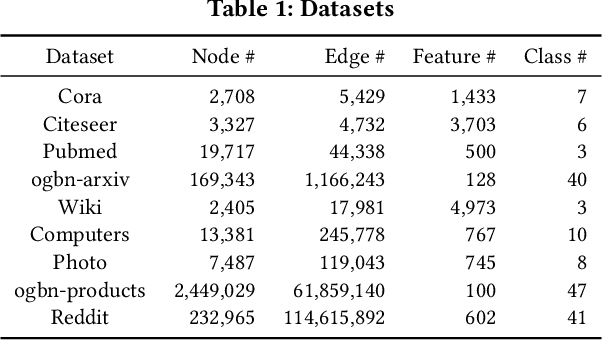
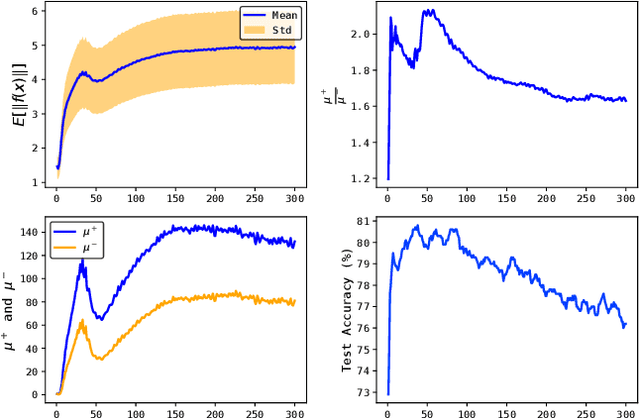
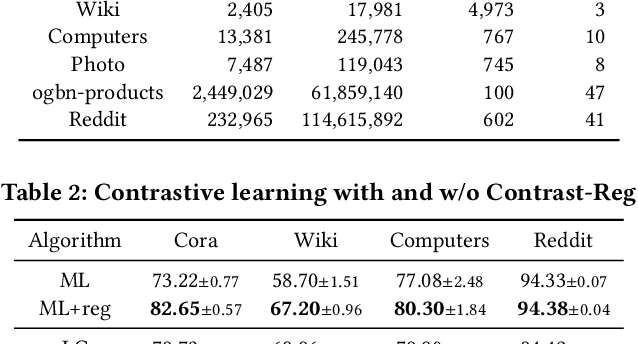
Graph representation learning is an important task with applications in various areas such as online social networks, e-commerce networks, WWW, and semantic webs. For unsupervised graph representation learning, many algorithms such as Node2Vec and Graph-SAGE make use of "negative sampling" and/or noise contrastive estimation loss. This bears similar ideas to contrastive learning, which "contrasts" the node representation similarities of semantically similar (positive) pairs against those of negative pairs. However, despite the success of contrastive learning, we found that directly applying this technique to graph representation learning models (e.g., graph convolutional networks) does not always work. We theoretically analyze the generalization performance and propose a light-weight regularization term that avoids the high scales of node representations' norms and the high variance among them to improve the generalization performance. Our experimental results further validate that this regularization term significantly improves the representation quality across different node similarity definitions and outperforms the state-of-the-art methods.
The item selection problem for user cold-start recommendation
Oct 27, 2020
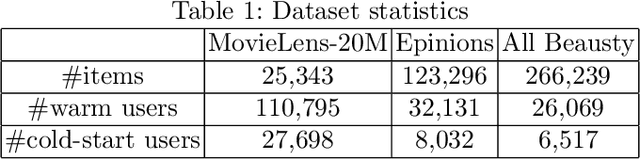
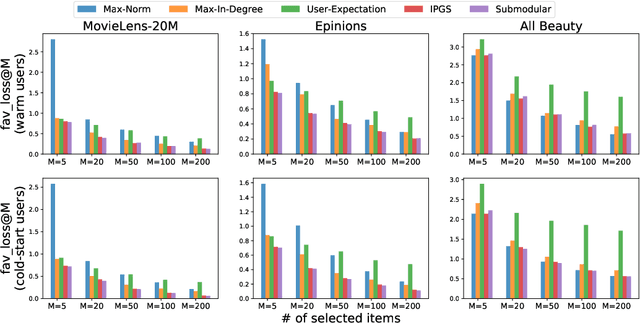
When a new user just signs up on a website, we usually have no information about him/her, i.e. no interaction with items, no user profile and no social links with other users. Under such circumstances, we still expect our recommender systems could attract the users at the first time so that the users decide to stay on the website and become active users. This problem falls into new user cold-start category and it is crucial to the development and even survival of a company. Existing works on user cold-start recommendation either require additional user efforts, e.g. setting up an interview process, or make use of side information [10] such as user demographics, locations, social relations, etc. However, users may not be willing to take the interview and side information on cold-start users is usually not available. Therefore, we consider a pure cold-start scenario where neither interaction nor side information is available and no user effort is required. Studying this setting is also important for the initialization of other cold-start solutions, such as initializing the first few questions of an interview.
Rethinking Graph Regularization For Graph Neural Networks
Sep 04, 2020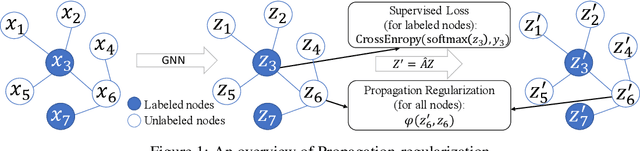
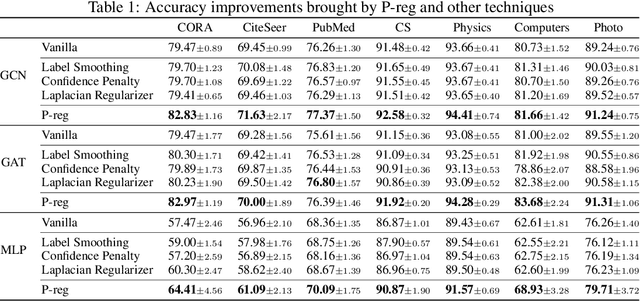
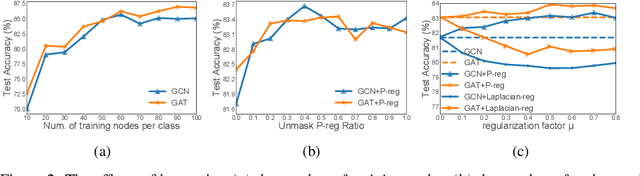
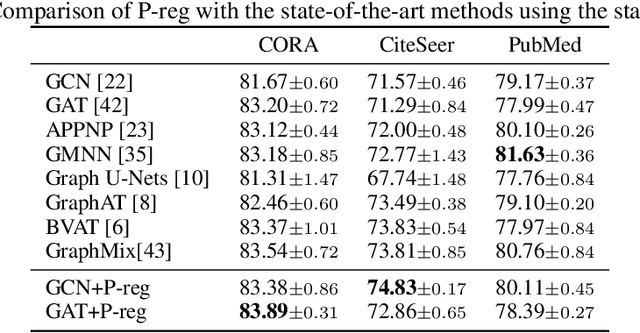
The graph Laplacian regularization term is usually used in semi-supervised node classification to provide graph structure information for a model $f(X)$. However, with the recent popularity of graph neural networks (GNNs), directly encoding graph structure $A$ into a model, i.e., $f(A, X)$, has become the more common approach. While we show that graph Laplacian regularization $f(X)^\top \Delta f(X)$ brings little-to-no benefit to existing GNNs, we propose a simple but non-trivial variant of graph Laplacian regularization, called Propagation-regularization (P-reg), to boost the performance of existing GNN models. We provide formal analyses to show that P-reg not only infuses extra information (that is not captured by the traditional graph Laplacian regularization) into GNNs, but also has the capacity equivalent to an infinite-depth graph convolutional network. The code is available at https://github.com/yang-han/P-reg.
Understanding Graph Neural Networks from Graph Signal Denoising Perspectives
Jun 08, 2020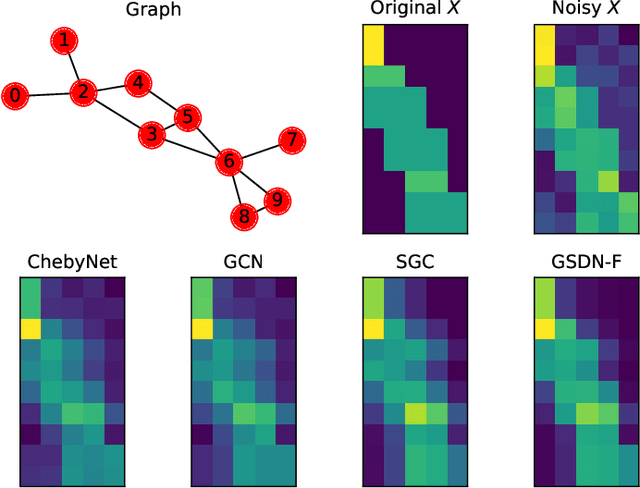
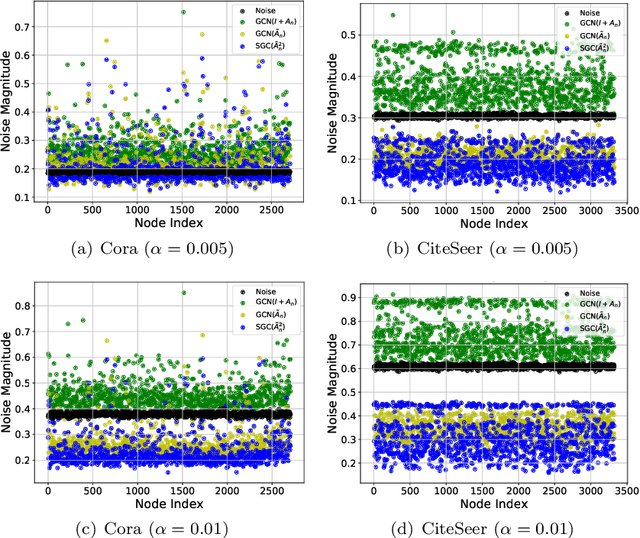
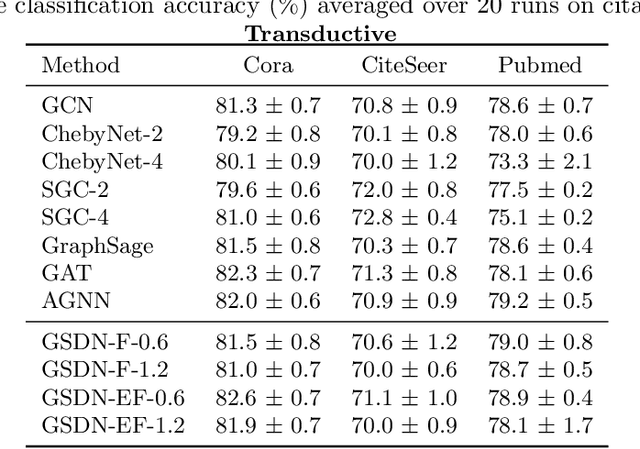
Graph neural networks (GNNs) have attracted much attention because of their excellent performance on tasks such as node classification. However, there is inadequate understanding on how and why GNNs work, especially for node representation learning. This paper aims to provide a theoretical framework to understand GNNs, specifically, spectral graph convolutional networks and graph attention networks, from graph signal denoising perspectives. Our framework shows that GNNs are implicitly solving graph signal denoising problems: spectral graph convolutions work as denoising node features, while graph attentions work as denoising edge weights. We also show that a linear self-attention mechanism is able to compete with the state-of-the-art graph attention methods. Our theoretical results further lead to two new models, GSDN-F and GSDN-EF, which work effectively for graphs with noisy node features and/or noisy edges. We validate our theoretical findings and also the effectiveness of our new models by experiments on benchmark datasets. The source code is available at \url{https://github.com/fuguoji/GSDN}.
Boosting First-order Methods by Shifting Objective: New Schemes with Faster Worst Case Rates
May 25, 2020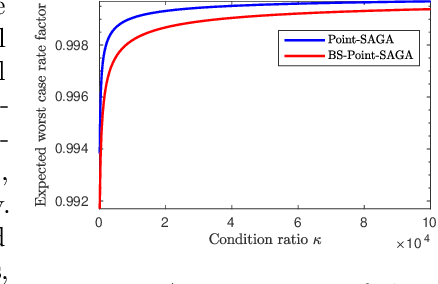
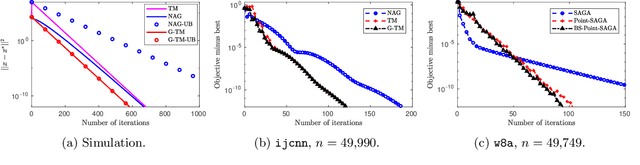
We propose a new methodology to design first-order methods for unconstrained strongly convex problems, i.e., to design for a shifted objective function. Several technical lemmas are provided as the building blocks for designing new methods. By shifting objective, the analysis is tightened, which leaves space for faster rates, and also simplified. Following this methodology, we derived several new accelerated schemes for problems that equipped with various first-order oracles, and all of the derived methods have faster worst case convergence rates than their existing counterparts. Experiments on machine learning tasks are conducted to evaluate the new methods.
TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism
Apr 16, 2020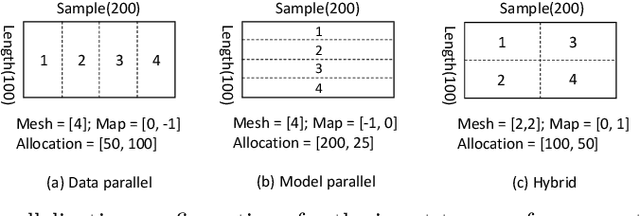
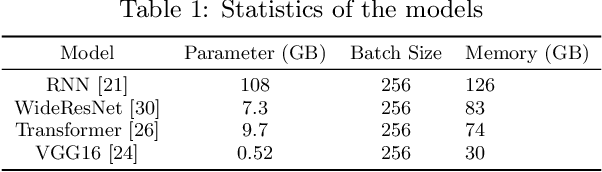
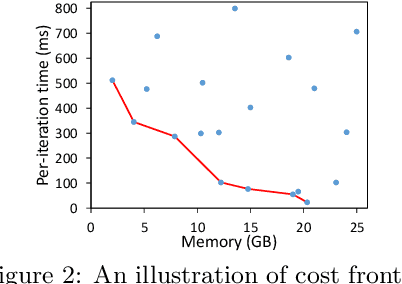

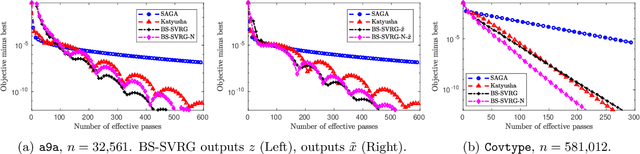
A good parallelization strategy can significantly improve the efficiency or reduce the cost for the distributed training of deep neural networks (DNNs). Recently, several methods have been proposed to find efficient parallelization strategies but they all optimize a single objective (e.g., execution time, memory consumption) and produce only one strategy. We propose FT, an efficient algorithm that searches for an optimal set of parallelization strategies to allow the trade-off among different objectives. FT can adapt to different scenarios by minimizing the memory consumption when the number of devices is limited and fully utilize additional resources to reduce the execution time. For popular DNN models (e.g., vision, language), an in-depth analysis is conducted to understand the trade-offs among different objectives and their influence on the parallelization strategies. We also develop a user-friendly system, called TensorOpt, which allows users to run their distributed DNN training jobs without caring the details of parallelization strategies. Experimental results show that FT runs efficiently and provides accurate estimation of runtime costs, and TensorOpt is more flexible in adapting to resource availability compared with existing frameworks.
Self-Enhanced GNN: Improving Graph Neural Networks Using Model Outputs
Mar 16, 2020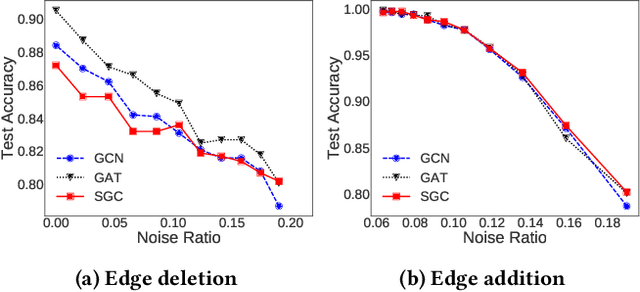
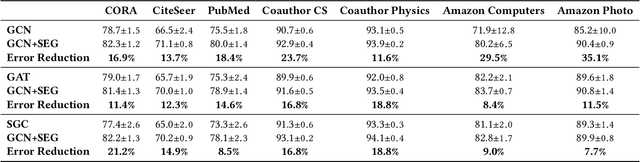
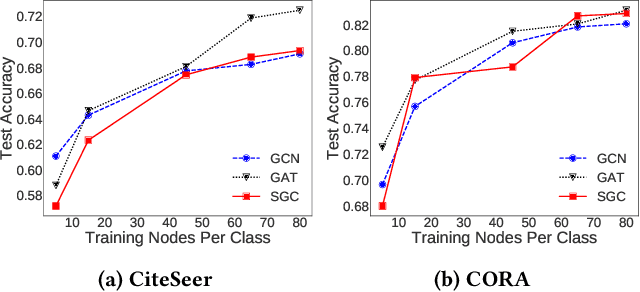
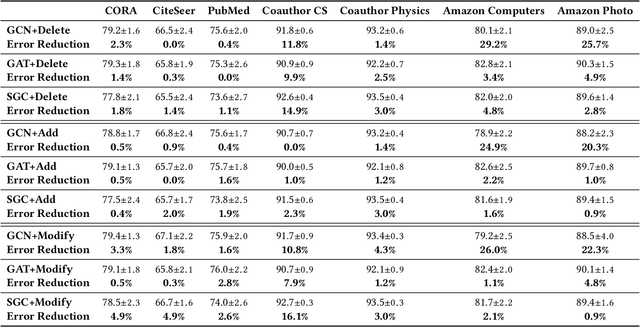
Graph neural networks (GNNs) have received much attention recently because of their excellent performance on graph-based tasks. However, existing research on GNNs focuses on designing more effective models without considering much the quality of the input data itself. In this paper, we propose self-enhanced GNN, which improves the quality of the input data using the outputs of existing GNN models for better performance on semi-supervised node classification. As graph data consist of both topology and node labels, we improve input data quality from both perspectives. For topology, we observe that higher classification accuracy can be achieved when the ratio of inter-class edges (connecting nodes from different classes) is low and propose topology update to remove inter-class edges and add intra-class edges. For node labels, we propose training node augmentation, which enlarges the training set using the labels predicted by existing GNN models. As self-enhanced GNN improves the quality of the input graph data, it is general and can be easily combined with existing GNN models. Experimental results on three well-known GNN models and seven popular datasets show that self-enhanced GNN consistently improves the performance of the three models. The reduction in classification error is 16.2% on average and can be as high as 35.1%.
Edit Distance Embedding using Convolutional Neural Networks
Jan 31, 2020
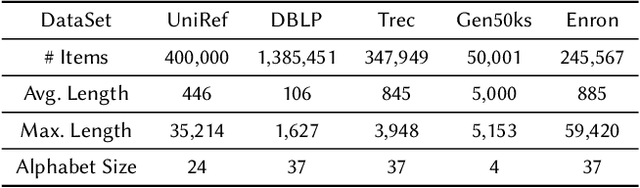
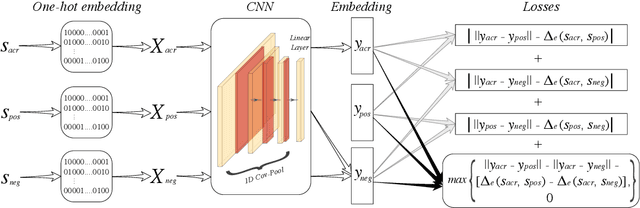
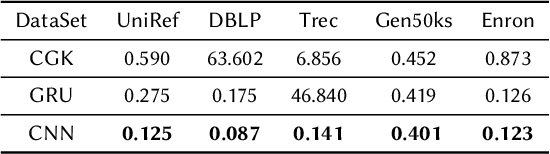
Edit-distance-based string similarity search has many applications such as spell correction, data de-duplication, and sequence alignment. However, computing edit distance is known to have high complexity, which makes string similarity search challenging for large datasets. In this paper, we propose a deep learning pipeline (called CNN-ED) that embeds edit distance into Euclidean distance for fast approximate similarity search. A convolutional neural network (CNN) is used to generate fixed-length vector embeddings for a dataset of strings and the loss function is a combination of the triplet loss and the approximation error. To justify our choice of using CNN instead of other structures (e.g., RNN) as the model, theoretical analysis is conducted to show that some basic operations in our CNN model preserve edit distance. Experimental results show that CNN-ED outperforms data-independent CGK embedding and RNN-based GRU embedding in terms of both accuracy and efficiency by a large margin. We also show that string similarity search can be significantly accelerated using CNN-based embeddings, sometimes by orders of magnitude.
Hyper-Sphere Quantization: Communication-Efficient SGD for Federated Learning
Nov 25, 2019
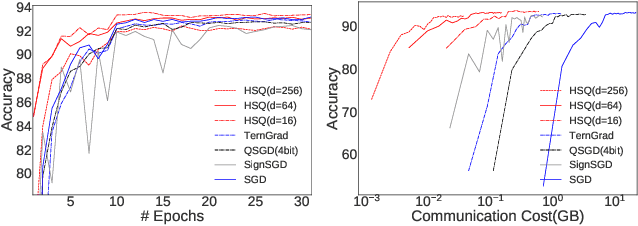
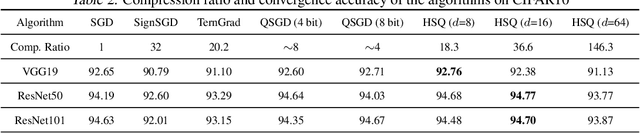
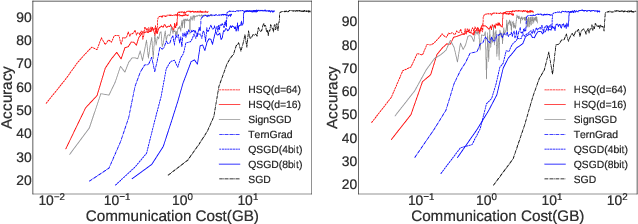
The high cost of communicating gradients is a major bottleneck for federated learning, as the bandwidth of the participating user devices is limited. Existing gradient compression algorithms are mainly designed for data centers with high-speed network and achieve $O(\sqrt{d} \log d)$ per-iteration communication cost at best, where $d$ is the size of the model. We propose hyper-sphere quantization (HSQ), a general framework that can be configured to achieve a continuum of trade-offs between communication efficiency and gradient accuracy. In particular, at the high compression ratio end, HSQ provides a low per-iteration communication cost of $O(\log d)$, which is favorable for federated learning. We prove the convergence of HSQ theoretically and show by experiments that HSQ significantly reduces the communication cost of model training without hurting convergence accuracy.
Norm-Explicit Quantization: Improving Vector Quantization for Maximum Inner Product Search
Nov 20, 2019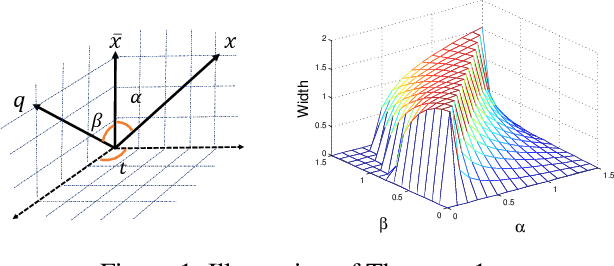
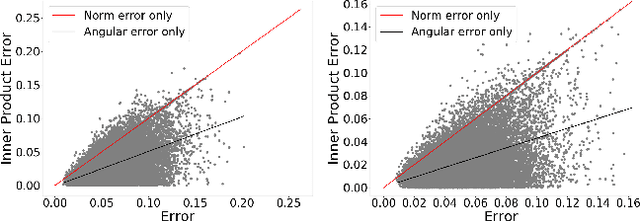
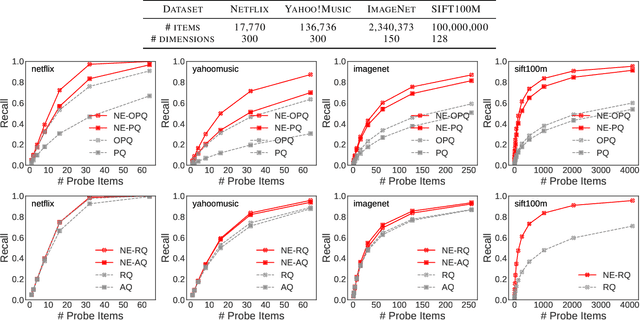
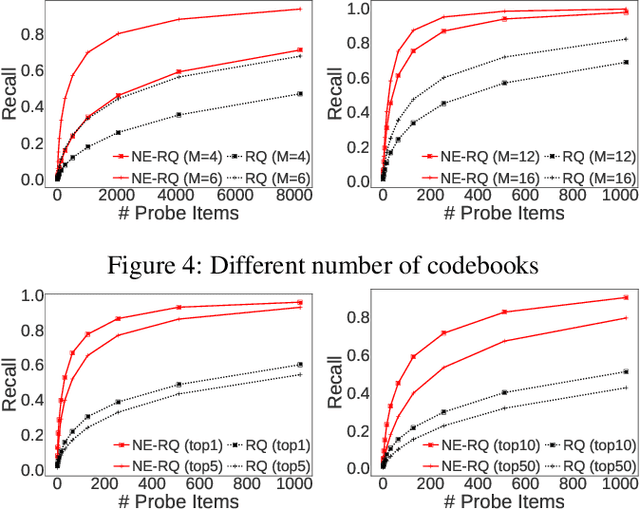
Vector quantization (VQ) techniques are widely used in similarity search for data compression, fast metric computation and etc. Originally designed for Euclidean distance, existing VQ techniques (e.g., PQ, AQ) explicitly or implicitly minimize the quantization error. In this paper, we present a new angle to analyze the quantization error, which decomposes the quantization error into norm error and direction error. We show that quantization errors in norm have much higher influence on inner products than quantization errors in direction, and small quantization error does not necessarily lead to good performance in maximum inner product search (MIPS). Based on this observation, we propose norm-explicit quantization (NEQ) --- a general paradigm that improves existing VQ techniques for MIPS. NEQ quantizes the norms of items in a dataset explicitly to reduce errors in norm, which is crucial for MIPS. For the direction vectors, NEQ can simply reuse an existing VQ technique to quantize them without modification. We conducted extensive experiments on a variety of datasets and parameter configurations. The experimental results show that NEQ improves the performance of various VQ techniques for MIPS, including PQ, OPQ, RQ and AQ.